1 信息检索概述
1.1 传统检索方式的缺点
• 文件检索
操作系统常见的是硬盘文件检索
文档检索:整个文档打开时已经加载到内存了;
缺点:全盘遍历,慢,内存的海量数据
• 数据库检索
like "%三星%" 全表遍历;
like "三星%" 最左特性 不会全表遍历;
无法满足海量数据下准确迅速的定位
mysql 单表数据量---千万级
oracle 单表数据量---亿级
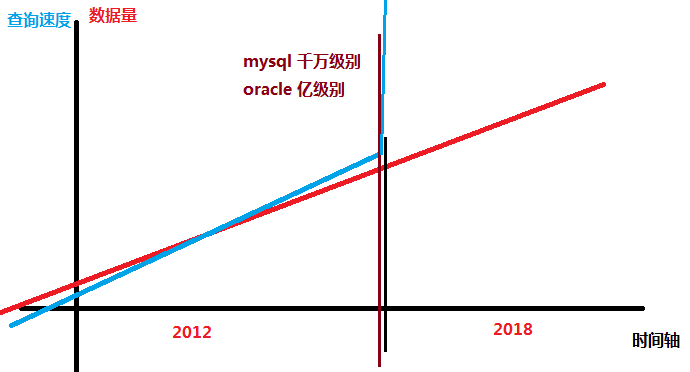
总结:传统的方式无法满足检索的需求(迅速,准确,海量)
2 全文检索技术(大型互联网公司的搜索功能都是全文检索)
2.1 定义:
- 在海量的信息中,通过固定的数据结构引入索引文件,利用对索引文件的处理实现对应数据的快速定位等功能的技术;
- 信息检索系统(全文检索技术的应用,搜索引擎百度,google)
- 信息采集:通过爬虫技术,将公网的海量非结构化数据爬去到本地的分布式存储系统进行存储
- 信息整理:非结构化数据无法直接提供使用,需要整理,整理成索引文件
- 信息查询:通过建立一个搜索的应用,提供用户的入口进行查询操作,利用查询条件搜索索引文件中的有效数据;
2.2结构
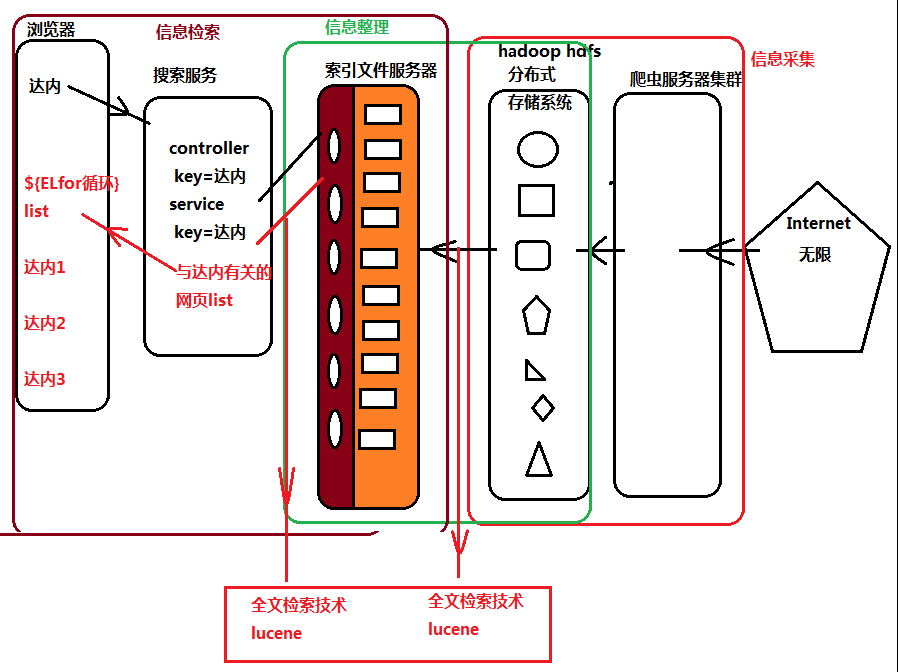
问题:非结构化数据,海量数据如何整理成有结构的索引文件(索引文件到底什么结构)?
2.3 倒排索引
索引文件,是全文检索技术的核心内容,创建索引,搜索索引也是核心,搜索在创建之后的;
如何将海量数据计算输出成有结构的索引文件,需要严格规范的计算逻辑-----倒排索引的计算
以网页为例:
假设爬虫系统爬去公网海量网页(2条);利用倒排索引的计算逻辑,将这2个非结构化的网页信息数据整理成索引文件;
源数据: 标题,时间,作者,留言,内容
网页1(id=1): 王思聪的IG战队获得LOL世界冠军,结束长达8年的遗憾
网页2(id=2): 王思聪又换女朋友了吗?嗯,天天换.
倒排索引的第一步:计算分词(数据内容)
分词:将数据字符串进行切分,形成最小意义的词语 (不同语言底层实现是不一样的)
并且每个分词计算的词语都会携带计算过程中的一些参数
词语(来源的网页id,当前网页中该词语出现的频率,出现的位置)
网页1: 王思聪(1,1,1),IG(1,1,2),战队(1,1,3), LOL(1,1,4) 世界(1,1,5)
网页2: 王思聪(2,1,1),女朋友(2,1,1),天天(2,1,1);
倒排索引第二步:合并分词结果
合并结果:王思聪([1,2],[1,1],[1,1]),IG(1,1,2),战队(1,1,3), LOL(1,1,4) 世界(1,1,5),女朋友(2,1,1),天天(2,1,1);
合并逻辑:所有的网页的分词计算结果一定有重复的分词词汇,合并后所有参数也一起合并,结果形成了一批索引结构的数据;
倒排索引第三步:源数据整理document对象
document是索引文件中的文档对象,最小的数据单位(数据库中的一行数据)每个document对应一个网页
倒排索引第四步:形成索引文件
将网页的数据对象(document)和分词合并结果(index)一起存储到存储位置,形成整体的索引文件
索引文件结构:
数据对象
合并分词结果

对索引文件中的分词合并后的数据进行复杂的计算处理,获取我们想要的数据集合(document的集合)
3 Lucene
3.1介绍
是一个全文检索引擎工具包,hadoop的创始人Doug Cutting开发,2000年开始,每周花费2天,完成了lucene的第一个版本;引起搜索界的巨大轰动; java开发的工具包;
3.2 特点
- 稳定,索引性能高 (创建和搜索的性能)
- 现代磁盘每小时能索引150G数据(读写中)
- 对内存要求1MB栈内存
- 增量索引和批量索引速度一样快
- 索引的数据占整体索引文件20%
- 支持多种主流搜索功能.
3.3分词代码测试
准备依赖的jar包(lucene6.0)
<!-- lucene查询扩展转化器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>6.0.0</version>
</dependency>
<!-- lucene自带的智能中文分词器 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>6.0.0</version>
</dependency>
<!-- lucene核心功能包 -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.0.0</version>
</dependency>
lucene分词测试
索引的查询都是基于分词的计算结果完成的,这种计算分词的过程叫做词条化,得到的每一个词汇称之为词项,lucene提供抽象类Analyzer表示分词器对象,不同的实现类来自不同的开发团队,实现这个Analyzer完成各自分词的计算;lucene也提供了多种分词器计算
- StandardAnalyzer 标准分词器,分词英文
- WhitespaceAnalyzer 空格分词器
- SimpleAnalyzer 简单分词器
- SmartChineseAnalyzer 智能中文分词器
1 package com.jt.test.lucene; 2 3 import java.io.StringReader; 4 5 import org.apache.lucene.analysis.Analyzer; 6 import org.apache.lucene.analysis.TokenStream; 7 import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; 8 import org.apache.lucene.analysis.core.SimpleAnalyzer; 9 import org.apache.lucene.analysis.core.WhitespaceAnalyzer; 10 import org.apache.lucene.analysis.standard.StandardAnalyzer; 11 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 12 import org.junit.Test; 13 14 /** 15 *测试不同分词器对同一个字符串的分词结果 16 */ 17 public class AnalyzerTest { 18 19 //编写一个静态方法, String str,Analayzer a 20 //实现传入的字符串进行不同分词器的计算词项结果 21 public static void printA(Analyzer analyzer,String str) throws Exception{ 22 //org.apache.lucene 23 //获取str的刘对象 24 StringReader reader=new StringReader(str); 25 //通过字符串流获取分词词项流,每个不同的analyzer实现对象 26 //词项流的底层计算时不一样的; 27 //fieldName是当前字符串 代表的document的域名/属性名 28 TokenStream tokenStream = analyzer.tokenStream("name", reader); 29 //对流进行参数的重置reset,才能获取词项信息 30 tokenStream.reset(); 31 //获取词项的打印结果 32 CharTermAttribute attribute 33 = tokenStream.getAttribute(CharTermAttribute.class); 34 while(tokenStream.incrementToken()){ 35 System.out.println(attribute.toString()); 36 } 37 } 38 @Test 39 public void test() throws Exception{ 40 String str="近日,有网友偶遇诸葛亮王思聪和网红焦可然一起共进晚餐," 41 + "照片中,焦可然任由王思聪点菜,自己则专注玩手机,"; 42 //创建不同的分词计算器 43 Analyzer a1=new StandardAnalyzer(); 44 Analyzer a2=new SmartChineseAnalyzer(); 45 Analyzer a3=new SimpleAnalyzer(); 46 Analyzer a4=new WhitespaceAnalyzer(); 47 //调用方法测试不同分词器的分词效果 48 System.out.println("*******标准分词器*******"); 49 AnalyzerTest.printA(a1, str); 50 System.out.println("*******智能中文分词器*******"); 51 AnalyzerTest.printA(a2, str); 52 System.out.println("*******简单分词器*******"); 53 AnalyzerTest.printA(a3, str); 54 System.out.println("*******空格分词器*******"); 55 AnalyzerTest.printA(a4, str); 56 } 57 }
3.4中文分词器常用IKAnalyzer
可以实现中文的只能分词,并且支持扩展,随着语言的各种发展,可以利用ext.dic文档补充词项,也支持停用,stop.dic;
- 实现类的编写(IKAnalyzer需要自定义实现一些类)
1 package com.jt.lucene.IK; 2 3 import java.io.IOException; 4 5 import org.apache.lucene.analysis.Tokenizer; 6 import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; 7 import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; 8 import org.apache.lucene.analysis.tokenattributes.TypeAttribute; 9 import org.wltea.analyzer.core.IKSegmenter; 10 import org.wltea.analyzer.core.Lexeme; 11 12 public class IKTokenizer6x extends Tokenizer{ 13 //ik分词器实现 14 private IKSegmenter _IKImplement; 15 //词元文本属性 16 private final CharTermAttribute termAtt; 17 //词元位移属性 18 private final OffsetAttribute offsetAtt; 19 //词元分类属性 20 private final TypeAttribute typeAtt; 21 //记录最后一个词元的结束位置 22 private int endPosition; 23 //构造函数,实现最新的Tokenizer 24 public IKTokenizer6x(boolean useSmart){ 25 super(); 26 offsetAtt=addAttribute(OffsetAttribute.class); 27 termAtt=addAttribute(CharTermAttribute.class); 28 typeAtt=addAttribute(TypeAttribute.class); 29 _IKImplement=new IKSegmenter(input, useSmart); 30 } 31 32 @Override 33 public final boolean incrementToken() throws IOException { 34 //清除所有的词元属性 35 clearAttributes(); 36 Lexeme nextLexeme=_IKImplement.next(); 37 if(nextLexeme!=null){ 38 //将lexeme转成attributes 39 termAtt.append(nextLexeme.getLexemeText()); 40 termAtt.setLength(nextLexeme.getLength()); 41 offsetAtt.setOffset(nextLexeme.getBeginPosition(), 42 nextLexeme.getEndPosition()); 43 //记录分词的最后位置 44 endPosition=nextLexeme.getEndPosition(); 45 typeAtt.setType(nextLexeme.getLexemeText()); 46 return true;//告知还有下个词元 47 } 48 return false;//告知词元输出完毕 49 } 50 51 @Override 52 public void reset() throws IOException { 53 super.reset(); 54 _IKImplement.reset(input); 55 } 56 57 @Override 58 public final void end(){ 59 int finalOffset = correctOffset(this.endPosition); 60 offsetAtt.setOffset(finalOffset, finalOffset); 61 } 62 63 }
1 package com.jt.lucene.IK; 2 3 import org.apache.lucene.analysis.Analyzer; 4 import org.apache.lucene.analysis.Tokenizer; 5 6 public class IKAnalyzer6x extends Analyzer{ 7 private boolean useSmart; 8 public boolean useSmart(){ 9 return useSmart; 10 } 11 public void setUseSmart(boolean useSmart){ 12 this.useSmart=useSmart; 13 } 14 public IKAnalyzer6x(){ 15 this(false);//IK分词器lucene analyzer接口实现类,默认细粒度切分算法 16 } 17 //重写最新版本createComponents;重载analyzer接口,构造分词组件 18 @Override 19 protected TokenStreamComponents createComponents(String filedName) { 20 Tokenizer _IKTokenizer=new IKTokenizer6x(this.useSmart); 21 return new TokenStreamComponents(_IKTokenizer); 22 } 23 public IKAnalyzer6x(boolean useSmart){ 24 super(); 25 this.useSmart=useSmart; 26 } 27 28 }
- 手动导包
build-path添加依赖的jar包到当前工程 IKAnalyzer2012_u6.jar
- 扩展词典和停用词典的使用
<entry key="ext_dict">ext.dic;</entry> <!--用户可以在这里配置自己的扩展停止词字典--> <entry key="ext_stopwords">stopword.dic;</entry> 和配置文件同目录下准备2个词典; 确定分词器使用的代码编码字符集与词典编码是同一个
4 Lucene创建索引
4.1概念
查询(Query):对于全文检索,最终都是使用词项指向一批document文档对象的集合,利用对词项的逻辑计算可以实现不同的查询功能;查询时构建的对象就是Query;
文档(document):是索引文件中的一个最小的数据单位,例如非结构化数据中的网页将会封装成一个document存储在索引文件中,而封装过程中写在对象里的所有数据都会根据逻辑进行分词计算,不同的结构数据源会对应创建具有不同属性的document对象
文档的域(Field):每个文档对象根据不同的数据来源封装Field的名称,个数和数据,导致document的结构可能各不相同
词条化(tokenization):计算分词过程
词项(Term):计算分词的结果每一个词语都是一个项
4.2 创建一个空的索引文件
- 指向一个索引文件位置
- 生成输出对象,进行输出
1 @Test 2 public void emptyIndex() throws Exception{ 3 //指向一个文件夹位置 4 Path path = Paths.get("./index01"); 5 Directory dir=FSDirectory.open(path); 6 //生成一个输出对象 writer 需要分词计算器,配置对象 7 Analyzer analyzer=new IKAnalyzer6x(); 8 IndexWriterConfig config=new IndexWriterConfig(analyzer); 9 IndexWriter writer=new IndexWriter(dir,config); 10 //写出到磁盘,如果没有携带document,生成一个空的index文件 11 writer.commit(); 12 13 }
在索引中创建数据
- 将源数据读取封装成document对象,根据源数据的结构定义document的各种field;
1 @Test 2 public void createData() throws Exception{ 3 /* 4 * 1 指向一个索引文件 5 * 2 生成输出对象 6 * 3 封装document对象(手动填写数据) 7 * 4 将document添加到输出对象索引文件的输出 8 */ 9 //指向一个文件夹位置 10 Path path = Paths.get("./index02"); 11 Directory dir=FSDirectory.open(path); 12 //生成一个输出对象 writer 需要分词计算器,配置对象 13 Analyzer analyzer=new IKAnalyzer6x(); 14 IndexWriterConfig config=new IndexWriterConfig(analyzer); 15 IndexWriter writer=new IndexWriter(dir,config); 16 //构造document对象 17 Document doc1=new Document();//新闻 作者,内容,网站链接地址 18 Document doc2=new Document();//商品页面,title,price,详情,图片等 19 doc1.add(new TextField("author", "韩寒", Store.YES)); 20 doc1.add(new TextField("content","我是上海大金子",Store.NO)); 21 doc1.add(new StringField("address", "http://www.news.com", Store.YES)); 22 doc2.add(new TextField("title", "三星(SAMSUNG) 1TB Type-c USB3.1 移动固态硬盘",Store.YES)); 23 doc2.add(new TextField("price","1699",Store.YES)); 24 doc2.add(new TextField("desc","不怕爆炸你就买",Store.YES)); 25 doc2.add(new StringField("image", "image.jt.com/1/1.jpg", 26 Store.YES)); 27 //将2个document对象添加到writer中写出到索引文件; 28 writer.addDocument(doc1); 29 writer.addDocument(doc2); 30 //写出到磁盘,如果没有携带document,生成一个空的index文件 31 writer.commit(); 32 }
- 问题一:Store.yes和no的区别是什么?????
- Store,yes和no的区别在于,创建索引数据,非领导数据是否在输出到索引时存储到索引文件,按照类的类型进行计算分词,一些过大的数据,查询不需要的数据可以不存储在索引文件中(例如网页内容;计算不计算分词,和存储索引没有关系)
- 问题二:StringField和TextField的区别是什么
- 域的数据需要进行分词计算如果是字符串有两种对应的域类型
- 其中StringField表示不对数据进行分词计算,以整体形势计算索引
- TextField表示对数据进行分词计算,以词形势计算索引
- 问题三: 问题3:显然document中的不同域field应该保存不同的数据类型
- 数据中的类型不同,存储的数据计算逻辑也不同;
- int long double的数字数据如果使用字符串类型保存域
- 只能做到一件事--存储在索引文件上
- 以上几个Point类型的域会对数据进行二进制数字的计算;
- 范围查找,只要利用intPoint,longPoint对应域存储到document对象后
- 这种类型的数据在分词计算中就具有了数字的特性 > <
- intPoint只能存储数值,不存储数据
- 如果既想记性数字特性的使用,又要存储数据;需要使用StringField类型
5 Lucene索引的搜索
5.1词项查询
单域查询:查询条件封装指定的域,给定Term(词项),lucene调用搜索api可以根据指定的条件,将所有当前查询的这个域中的分词结果进行比对,如果比对成功指向document对象返回数据;
1 @Test 2 public void search() throws Exception{ 3 /* 4 * 1 指向索引文件 5 * 2 构造查询条件 6 * 3 执行搜索获取返回数据 7 * 4 从返回数据中获取document对象 8 */ 9 Path path = Paths.get("./index02"); 10 Directory dir=FSDirectory.open(path); 11 //获取与输入流reader,从这里生产查询的对象 12 IndexReader reader=DirectoryReader.open(dir); 13 IndexSearcher search=new IndexSearcher(reader); 14 //由于使用的是term查询,无需包装analyzer; 15 //构造查询条件; 16 Term term=new Term("title","三星"); 17 Query termQuery=new TermQuery(term); 18 //查询,获取数据 19 TopDocs docs = search.search(termQuery, 10); 20 //将docs转化成document的获取逻辑 21 ScoreDoc[] scoreDoc=docs.scoreDocs; 22 for (ScoreDoc sd : scoreDoc) { 23 //没循环一次,都可以获取document对象一个 24 Document doc=search.doc(sd.doc); 25 System.out.println("author:"+doc.get("author")); 26 System.out.println("content:"+doc.get("content")); 27 System.out.println("address:"+doc.get("address")); 28 System.out.println("title:"+doc.get("title")); 29 System.out.println("image:"+doc.get("image")); 30 System.out.println("price:"+doc.get("price")); 31 System.out.println("rate:"+doc.get("rate")); 32 System.out.println("desc:"+doc.get("desc"));}}
多域查询:指定的查询多个field,传递参数的字符串会被先进行分词计算,利用分词计算的结果(多个词项),比对所有的域中的词项,只要满足一个与对应一个词项的最小要求就可以拿到当前的document范围.
1 @Test 2 public void multiQuery() throws Exception{ 3 //使用parser,转化查询条件,需要传递analyzer,查询的字符串需要计算分词 4 Path path=Paths.get("./index02"); 5 Directory dir=FSDirectory.open(path); 6 IndexReader reader=DirectoryReader.open(dir); 7 IndexSearcher search=new IndexSearcher(reader); 8 //用到分词器计算查询的条件,必须和创建索引时用的分词一致; 9 Analyzer analyzer=new IKAnalyzer6x(); 10 //准备查询的2个域desc title 11 String[] fields={"desc","title"}; 12 //获取转化器,将查询的字符串进行分词计算,获取多于查询的对象query 13 MultiFieldQueryParser parser= 14 new MultiFieldQueryParser(fields,analyzer); 15 Query multiFieldQuery=parser.parse("爆");//三星,爆炸 16 TopDocs docs=search.search(multiFieldQuery, 10); 17 ScoreDoc[] scoreDocs=docs.scoreDocs; 18 for (ScoreDoc scoreDoc : scoreDocs) { 19 Document doc=search.doc(scoreDoc.doc); 20 System.out.println("author:"+doc.get("author")); 21 System.out.println("content:"+doc.get("content")); 22 System.out.println("address:"+doc.get("address")); 23 System.out.println("title:"+doc.get("title")); 24 System.out.println("image:"+doc.get("image")); 25 System.out.println("price:"+doc.get("price")); 26 System.out.println("rate:"+doc.get("rate")); 27 System.out.println("desc:"+doc.get("desc"));}}
布尔查询:可以封装多个查询条件的对象query,由布尔查询条件实现多个其他查询的逻辑关系 MUST必须包含 MUST_NOT必须不包含.
对应一个布尔查询条件,一个没有must条件的布尔查询可以有一个或者多个should,有must条件的布尔查询,should不起作用;
MUST:匹配结果必须包含这个条件
MUST_NOT:匹配结果必须不包含这个条件
SHOULD:没有must的booleanClause中,可以有1个或者多个should,一旦有must条件,should就没有作用了
FILTER:和must效果一样,必须包含,但是查询过程不参加评分计算.
1 @Test 2 public void booleanQuery() throws Exception{ 3 Path path=Paths.get("./index02"); 4 Directory dir=FSDirectory.open(path); 5 IndexReader reader=DirectoryReader.open(dir); 6 IndexSearcher search=new IndexSearcher(reader); 7 //设置多个查询的query,可以使任何类型,TermQuery 8 //准备查询的2个域desc title 9 Analyzer analyzer=new IKAnalyzer6x(); 10 String[] fields={"desc","title"}; 11 //获取转化器,将查询的字符串进行分词计算,获取多于查询的对象query 12 MultiFieldQueryParser parser= 13 new MultiFieldQueryParser(fields,analyzer); 14 Query multiFieldQuery=parser.parse("三星爆炸");//三星,爆炸 15 Query query1=new TermQuery(new Term("title","三星")); 16 Query query2=new TermQuery(new Term("desc","爆炸")); 17 //构造一个布尔的查询条件 先构造查询的逻辑对象 18 BooleanClause bc1=new BooleanClause(query1,Occur.MUST); 19 //BooleanClause bc2=new BooleanClause(query2,Occur.MUST_NOT); 20 BooleanClause bc2=new BooleanClause(multiFieldQuery,Occur.FILTER); 21 BooleanQuery boolQuery= 22 new BooleanQuery.Builder().add(bc1).add(bc2).build(); 23 TopDocs docs=search.search(boolQuery, 10); 24 ScoreDoc[] scoreDocs=docs.scoreDocs; 25 for (ScoreDoc scoreDoc : scoreDocs) { 26 Document doc=search.doc(scoreDoc.doc); 27 System.out.println("author:"+doc.get("author")); 28 System.out.println("content:"+doc.get("content")); 29 System.out.println("address:"+doc.get("address")); 30 System.out.println("title:"+doc.get("title")); 31 System.out.println("image:"+doc.get("image")); 32 System.out.println("price:"+doc.get("price")); 33 System.out.println("rate:"+doc.get("rate")); 34 System.out.println("desc:"+doc.get("desc")); 35 System.out.println("文档评分:"+scoreDoc.score); 36 } 37 }
范围查询:对查询条件进行范围的定义,查询某个域的数据范围,只能对INTPOINT LONGPOINT DOUBLEPOINT FLOATPOINT类型的域做查询;
Query rangeQuery=IntPoint.newRangeQuery("rate", 200, 1000);
前缀查询:非常类似数据库中的like"三星%",查询条件表示前缀,只要当前的域满足前缀的内容,就能够查询document;
//构造前缀的词项
Term term=new Term("desc","爆");
Query query=new PrefixQuery(term);
前缀查询中,前缀本身必须是索引文件的词项,否则无法查到
模糊查询
Term term=new Term("name","tramp");
FuzzyQuery query=new FuzzyQuery(term);
使用term中的词项,但是不在进行精确的匹配,可以查到具有trump词项;
曰和日, 晶和品
通配符查询
WildcardQuery query= new WildcardQuery(new Term("name","爆?")) //效率不高,小范围的遍历
?匹配所有内容,可以补充前缀查询中使用Term的问题;