Curator是Netflix公司开源的一个Zookeeper客户端,目前是apache顶级项目。与Zookeeper提供的原生客户端相比,Curator的抽象层次更高,简化了Zookeeper客户端的开发量,相当于netty之于socket编程。提供了一套易用性和可读性更强的Fluent风格的客户端API框架。官网为 http://curator.apache.org/
除此之外,Curator中还提供了Zookeeper各种应用场景(Recipe,如共享锁服务、Master选举机制和分布式计算器等)的抽象封装。所以说啊,不管是做底层库还是应用,用户体验真的很重要。
一、关于zookeeper的java客户端
Zookeeper的官方客户端提供了基本的操作,比如,创建会话、创建节点、读取节点、更新数据、删除节点和检查节点是否存在等。但对于开发人员来说,Zookeeper提供的基本操纵还是有一些不足之处。典型的缺点为:
(1)Zookeeper的Watcher是一次性的,每次触发之后都需要重新进行注册;
(2)Session超时之后没有实现重连机制;
(3)异常处理繁琐,Zookeeper提供了很多异常,对于开发人员来说可能根本不知道该如何处理这些异常信息;
(4)只提供了简单的byte[]数组的接口,没有提供针对对象级别的序列化;
(5)创建节点时如果节点存在抛出异常,需要自行检查节点是否存在;
(6)删除节点无法实现级联删除;
因此,产生了两款主流的三方zk客户端,ZkClient和Curator。第一个主流的三方zk客户端是ZkClient,由Datameer的工程师开发,对Zookeeper的原生API进行了包装,实现了超时重连、Watcher反复注册等功能。像dubbo等框架对其也进行了集成使用。
虽然ZkClient对原生API进行了封装,但也有它自身的不足之处:
- 几乎没有参考文档;
- 异常处理简化(抛出RuntimeException);
- 重试机制比较难用;
- 没有提供各种使用场景的实现;
注:除此之外,很多依赖zookeeper的中间件或大数据组件都配备了与之相适应的zookeeper客户端,例如hbase、hadoop、fabric8等。
因此,除了早期集成外,目前新的框架和系统很少使用ZkClient,因此本文详细解析curator。
二、Curator项目组件及与Zookeeper版本的对应关系

# maven依赖:
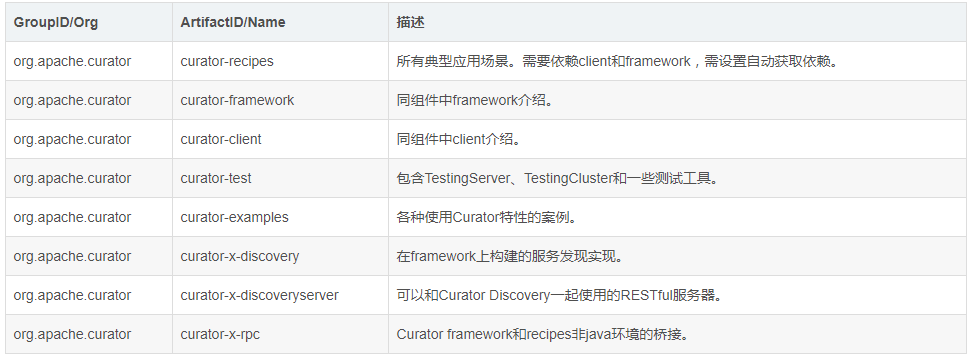
# Curator与Zookeeper的版本关系
目前Curator2.x.x和3.x.x两个系列的版本,支持不同版本的Zookeeper。其中Curator 2.x.x兼容Zookeeper的3.4.x和3.5.x。而Curator 3.x.x只兼容Zookeeper 3.5.x,并且提供了一些诸如动态重新配置、watch删除等新特性。
Curator4.0十分依赖Zookeeper3.5.X。
Curator4.0在软兼容模式下支持Zookeeper3.4.X,但是需要依赖排除zookeeper。
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>${curator-version}</version> <exclusions> <exclusion> <groupId>org.apache.zookeeper</groupId> <artifactId>zookeeper</artifactId> </exclusion> </exclusions> </dependency>
同时必须加入Zookeeper3.4.X的依赖,并且呢,因为是软兼容模式,一些3.4.X不具备的新特性是不能使用的。
我这里的Zookeeper版本是zookeeper-3.4.13,那我就选择Curator2.x.x的最高版本。依赖内容如下:
<dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-recipes</artifactId> <version>2.13.0</version> </dependency> <!-- 高级API,大大简化了ZooKeeper的使用 --> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-framework</artifactId> <version>2.13.0</version> </dependency> <!-- 底层 API--> <dependency> <groupId>org.apache.curator</groupId> <artifactId>curator-client</artifactId> <version>2.13.0</version> </dependency>
三、典型的ZK场景
Client操作
创建会话(连接zookeeper)
Curator的创建会话方式与原生的API和ZkClient的创建方式区别很大。Curator创建客户端是通过CuratorFrameworkFactory工厂类来实现的。其中,此工厂类提供了三种创建客户端的方法。 前两种方法是通过newClient来实现,仅参数不同而已。
public static CuratorFramework newClient(String connectString, RetryPolicy retryPolicy) public static CuratorFramework newClient(String connectString, int sessionTimeoutMs, int connectionTimeoutMs, RetryPolicy retryPolicy)
使用上面方法创建出一个CuratorFramework之后,需要再调用其start()方法完成会话创建。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181",retryPolicy); client.start();
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client = CuratorFrameworkFactory.newClient("127.0.0.1:2181", 5000,1000,retryPolicy); client.start();
其中参数RetryPolicy提供重试策略的接口,可以让用户实现自定义的重试策略。默认提供了以下实现,分别为ExponentialBackoffRetry、BoundedExponentialBackoffRetry、RetryForever、RetryNTimes、RetryOneTime、RetryUntilElapsed。
进一步查看源代码可以得知,其实这两种方法内部实现一样,只是对外包装成不同的方法。它们的底层都是通过第三个方法builder来实现的。
RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client =CuratorFrameworkFactory.builder() .connectString("127.0.0.1:2181") .retryPolicy(retryPolicy) .sessionTimeoutMs(6000) .connectionTimeoutMs(3000) .build(); client.start();
观察上面的实例,我们可以看到此处已经使用了Fluent风格的编码。其中namespace(“demo”)这项设置用来定义此会话的独立命名空间,随后的相应操作都是在此命名空间下进行操作。
# 重试策略
上面的例子中使用到了ExponentialBackoffRetry重试策略实现。此策略先给定一个初始化sleep时间baseSleepTimeMs,在此基础上结合重试次数,通过以下代码计算当前需要的sleep时间:
long sleepMs = baseSleepTimeMs * Math.max(1, random.nextInt(1 << (retryCount + 1))); if ( sleepMs > maxSleepMs ){ sleepMs = maxSleepMs; }
随着重试次数的增加,计算出的sleep时间也会越来越大。如果超过maxSleepMs则使用maxSleepMs的时间。其中maxRetries限制了最大的尝试次数。
① 单机模式
String zkAddress = "127.0.0.1:2181"; String zkPath = "/zktest"; // 同步创建zk示例,原生api是异步的 CuratorFramework client = CuratorFrameworkFactory.newClient( zkAddress, new RetryNTimes(10, 5000) ); client.start(); System.out.println("zk client start successfully!");
② 集群模式
String zkAddress = "127.0.0.1:2181,127.0.0.1:2182,127.0.0.1:2183"; String zkPath = "/zktest"; RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000, 5); String node = "test_data"; CuratorFramework client = CuratorFrameworkFactory.builder() .connectString(zkAddress) .sessionTimeoutMs(10 * 1000) .connectionTimeoutMs(20 * 1000) .namespace(node) //命名空间。 .retryPolicy(retryPolicy) .build(); // 建立连接通道。 client.start(); System.out.println("zk cluster started successfully");
创建节点
Curator创建节点的方法也是基于Fluent风格编码,原生API中的参数很多都转化为一层层的方法调用来进行设置。下面简单介绍一下常用的几个节点创建场景。
① 创建一个初始内容为空的节点
client.create().forPath(path);
Curator默认创建的是持久节点,内容为空。
② 创建一个包含内容的节点
client.create().forPath(path,"我是内容".getBytes());
Curator和ZkClient不同的是依旧采用Zookeeper原生API的风格,内容使用byte[]作为方法参数。
③ 创建临时节点,并递归创建父节点
client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath(path);
此处Curator和ZkClient一样封装了递归创建父节点的方法。在递归创建父节点时,父节点为持久节点。
删除节点
删除节点的方法也是基于Fluent方式来进行操作,不同类型的操作调用新增不同的方法调用即可。
① 删除一个子节点
client.delete().forPath(path);
② 删除节点并递归删除其子节点
client.delete().deletingChildrenIfNeeded().forPath(path);
③ 指定版本进行删除
client.delete().withVersion(1).forPath(path);
如果此版本已经不存在,则删除异常。
④ 强制保证删除一个节点
client.delete().guaranteed().forPath(path);
只要客户端会话有效,那么Curator会在后台持续进行删除操作,直到节点删除成功。比如遇到一些网络异常的情况,此guaranteed的强制删除就会很有效果。
读取数据
读取节点数据内容API相当简单,Curator提供了传入一个Stat,使用节点当前的Stat替换到传入的Stat的方法,查询方法执行完成之后,Stat引用已经执行当前最新的节点Stat。
// 普通查询 client.getData().forPath(path); // 包含状态查询 Stat stat = new Stat(); client.getData().storingStatIn(stat()).forPath(path);
更新数据
更新数据,如果未传入version参数,那么更新当前最新版本,如果传入version则更新指定version,如果version已经变更,则抛出异常。
// 普通更新 client.setData().forPath(path,"新内容".getBytes()); // 指定版本更新 client.setData().withVersion(1).forPath(path);
异步接口
在使用以上针对节点的操作API时,我们会发现每个接口都有一个inBackground()方法可供调用。此接口就是Curator提供的异步调用入口。对应的异步处理接口为BackgroundCallback。此接口指提供了一个processResult的方法,用来处理回调结果。其中processResult的参数event中的getType()包含了各种事件类型,getResultCode()包含了各种响应码。
重点说一下inBackground的以下接口:
public T inBackground(BackgroundCallback callback, Executor executor);
此接口就允许传入一个Executor实例,用一个专门线程池来处理返回结果之后的业务逻辑。
节点检查
原生API的提供4个相应的方法,通过这些方法,可以检查节点是否存在,返回节点Stat信息,对节点进行注册监听事件等操作。
public Stat exists(final String path, Watcher watcher) public Stat exists(String path, boolean watch) public void exists(final String path, Watcher watcher, StatCallback cb, Object ctx) public void exists(String path, boolean watch, StatCallback cb, Object ctx)
参数说明:
- path:操作节点路径
- watcher:注册Watcher,用于监听节点创建、节点删除、节点更新事件。
- watch:是否使用默认watcher
- cb:注册一个回调函数
- ctx:传递上下文信息
无论节点是否存在使用exists方法都可以进行监听注册。节点不存在时注册监听之后,当节点被创建则会通知客户端。 2、指定节点的子节点的变化不会通知客户端。
指定节点的子节点的变化不会通知客户端。
监听器
Curator提供了三种Watcher(Cache)来监听结点的变化:
- Path Cache:监视一个路径下孩子结点的创建、删除,以及结点数据的更新。产生的事件会传递给注册的PathChildrenCacheListener。
- Node Cache:监视一个结点的创建、更新、删除,并将结点的数据缓存在本地。
- Tree Cache:Path Cache和Node Cache的“合体”,监视路径下的创建、更新、删除事件,并缓存路径下所有孩子结点的数据。
注:以下实例默认节点“/p1”已经被创建切存在于Zookeeper服务器上的。
① 监听方式一
利用Watcher来对节点进行监听操作,但此监听操作只能监听一次,与原生API并无太大差异。如有典型业务场景需要使用可考虑,但一般情况不推荐使用。下面是具体的使用案例。
public class CuratorListenerTest1{ public static void main(String[] args) { CuratorFramework client = getClient(); String path = "/p1"; try { byte[] content = client.getData().usingWatcher(new Watcher() { @Override public void process(WatchedEvent watchedEvent) { System.out.println("监听器watchedEvent:" + watchedEvent); } }).forPath(path); System.out.println("监听节点内容:" + new String(content)); // 第一次变更节点数据 client.setData().forPath(path,"new content".getBytes()); // 第二次变更节点数据 client.setData().forPath(path,"second content".getBytes()); Thread.sleep(Integer.MAX_VALUE); } catch (Exception e) { e.printStackTrace(); client.close(); } finally { client.close(); } } private static CuratorFramework getClient(){ RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString("127.0.0.0:2181") .retryPolicy(retryPolicy) .sessionTimeoutMs(6000) .connectionTimeoutMs(3000) .namespace("demo") .build(); client.start(); return client; } }
执行此程序之后,首先会对节点/p1注册一个Watcher监听事件,同时返回当前节点的内容信息。随后改变节点内容为“new content”,此时触发监听事件,并打印出监听事件信息。但当第二次改变节点内容时,监听已经失效,无法再次获得节点变动事件。
② 监听方式二
CuratorListener监听,此监听主要针对background通知和错误通知。使用此监听器之后,调用inBackground方法会异步获得监听,而对于节点的创建或修改则不会触发监听事件。具体实例代码如下:
public class CuratorListenerTest1 { public static void main(String[] args) { CuratorFramework client = getClient(); String path = "/p1"; try { CuratorListener listener = new CuratorListener() { @Override public void eventReceived(CuratorFramework client, CuratorEvent event) throws Exception { System.out.println("监听事件触发,event内容为:" + event); } }; client.getCuratorListenable().addListener(listener); // 异步获取节点数据 client.getData().inBackground().forPath(path); // 变更节点内容 client.setData().forPath(path,"123".getBytes()); Thread.sleep(Integer.MAX_VALUE); } catch (Exception e) { e.printStackTrace(); client.close(); } finally { client.close(); } } private static CuratorFramework getClient(){ RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString("127.0.0.1:2181") .retryPolicy(retryPolicy) .sessionTimeoutMs(6000) .connectionTimeoutMs(3000) .namespace("demo") .build(); client.start(); return client; } }
其中两次触发监听事件,第一次触发为注册监听事件时触发,第二次为getData异步处理返回结果时触发。而setData的方法并未触发监听事件。
③ 监听方式三
Curator引入了Cache来实现对Zookeeper服务端事件监听,Cache事件监听可以理解为一个本地缓存视图与远程Zookeeper视图的对比过程。Cache提供了反复注册的功能。Cache分为两类注册类型:节点监听和子节点监听。
# NodeCache
用于监听数据节点本身的变化。提供了两个构造方法:
public NodeCache(CuratorFramework client, String path) public NodeCache(CuratorFramework client, String path, boolean dataIsCompressed)
其中参数dataIsCompressed表示是否对数据进行压缩,而第一个方法内部实现为调用第二个方法,且dataIsCompressed默认设为false。
对节点的监听需要配合回调函数来进行处理接收到监听事件之后的业务处理。NodeCache通过NodeCacheListener来完成后续处理。具体代码示例如下:
public class CuratorNodeCacheTest { public static void main(String[] args) throws Exception { CuratorFramework client = getClient(); String path = "/p1"; final NodeCache nodeCache = new NodeCache(client,path); nodeCache.start(); nodeCache.getListenable().addListener(new NodeCacheListener() { @Override public void nodeChanged() throws Exception { System.out.println("监听事件触发"); System.out.println("重新获得节点内容为:" + new String(nodeCache.getCurrentData().getData())); } }); client.setData().forPath(path,"456".getBytes()); client.setData().forPath(path,"789".getBytes()); client.setData().forPath(path,"123".getBytes()); client.setData().forPath(path,"222".getBytes()); client.setData().forPath(path,"333".getBytes()); client.setData().forPath(path,"444".getBytes()); Thread.sleep(15000); } private static CuratorFramework getClient(){ RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString("127.0.0.1:2181") .retryPolicy(retryPolicy) .sessionTimeoutMs(6000) .connectionTimeoutMs(3000) .namespace("demo") .build(); client.start(); return client; } }
NodeCache的start方法有一个带Boolean参数的方法,如果设置为true则在首次启动时就会缓存节点内容到Cache中。
经过试验,发现注册监听之后,如果先后多次修改监听节点的内容,部分监听事件会发生丢失现象。其他版本未验证,此版本此处需特别留意。
NodeCache不仅可以监听节点内容变化,还可以监听指定节点是否存在。如果原本节点不存在,那么Cache就会在节点被创建时触发监听事件,如果该节点被删除,就无法再触发监听事件。
# PathChildrenCache
PathChildrenCache用于监听数据节点子节点的变化情况。当前版本总共提供了7个构造方法,其中2个已经不建议使用了。
public PathChildrenCache(CuratorFramework client, String path, boolean cacheData) public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, boolean dataIsCompressed, final CloseableExecutorService executorService) public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, boolean dataIsCompressed, final ExecutorService executorService) public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, boolean dataIsCompressed, ThreadFactory threadFactory) public PathChildrenCache(CuratorFramework client, String path, boolean cacheData, ThreadFactory threadFactory)
其中cacheData表示是否把节点内容缓存起来,如果为true,那么接收到节点列表变更的同时会将获得节点内容。
ExecutorService 和threadFactory提供了通过线程池的方式来处理监听事件。
PathChildrenCache使用PathChildrenCacheListener来处理监听事件。具体使用方法见代码实例:
public class CuratorPathChildrenCacheTest { public static void main(String[] args) throws Exception { CuratorFramework client = getClient(); String parentPath = "/p1"; PathChildrenCache pathChildrenCache = new PathChildrenCache(client,parentPath,true); pathChildrenCache.start(PathChildrenCache.StartMode.POST_INITIALIZED_EVENT); pathChildrenCache.getListenable().addListener(new PathChildrenCacheListener() { @Override public void childEvent(CuratorFramework client, PathChildrenCacheEvent event) throws Exception { System.out.println("事件类型:" + event.getType() + ";操作节点:" + event.getData().getPath()); } }); String path = "/p1/c1"; client.create().withMode(CreateMode.PERSISTENT).forPath(path); Thread.sleep(1000); // 此处需留意,如果没有现成睡眠则无法触发监听事件 client.delete().forPath(path); Thread.sleep(15000); } private static CuratorFramework getClient(){ RetryPolicy retryPolicy = new ExponentialBackoffRetry(1000,3); CuratorFramework client = CuratorFrameworkFactory.builder() .connectString("127.0.0.1:2181") .retryPolicy(retryPolicy) .sessionTimeoutMs(6000) .connectionTimeoutMs(3000) .namespace("demo") .build(); client.start(); return client; } }
PathChildrenCache不会对二级子节点进行监听,只会对子节点进行监听。看上面的实例会发现在创建子节点和删除子节点两个操作中间使用了线程睡眠,否则无法接收到监听事件,这也是在使用过程中需要留意的一点。
分布式协调
一般我们称分布式锁的时候,指的是短时的分布式锁,因此一般采用redis实现,而zk下的称之为分布式协调更合理,因为它通常时间更长。比如分布式编程时,比如最容易碰到的情况就是应用程序在线上多机部署,于是当多个应用同时访问某一资源时,就需要某种机制去协调它们。例如,现在一台应用正在rebuild缓存内容,要临时锁住某个区域暂时不让访问;又比如调度程序每次只想一个任务被一台应用执行等等。大多数的分布式协调采用临时节点+watch机制实现。除了直接采用原始的监听器自己实现外,curator实现了分布式的IPM(进程间锁)。Curator的机制为:使用我们提供的lock路径的结点作为全局锁,这个结点的数据类似这种格式:[_c_64e0811f-9475-44ca-aa36-c1db65ae5350-lock-0000000005],每次获得锁时会生成这种串,释放锁时清空数据。由于内部采用zookeeper的临时顺序节点特性,一旦客户端失去连接后,则就会自动清除该节点,redis则只能等待超时。
public class CuratorDistrLockTest { /** Zookeeper info */ private static final String ZK_ADDRESS = "192.168.1.100:2181"; private static final String ZK_LOCK_PATH = "/zktest"; public static void main(String[] args) throws InterruptedException { // 1.Connect to zk CuratorFramework client = CuratorFrameworkFactory.newClient( ZK_ADDRESS, new RetryNTimes(10, 5000) ); client.start(); System.out.println("zk client start successfully!"); Thread t1 = new Thread(() -> { doWithLock(client); }, "t1"); Thread t2 = new Thread(() -> { doWithLock(client); }, "t2"); t1.start(); t2.start(); } private static void doWithLock(CuratorFramework client) { InterProcessMutex lock = new InterProcessMutex(client, ZK_LOCK_PATH); try { if (lock.acquire(10 * 1000, TimeUnit.SECONDS)) { System.out.println(Thread.currentThread().getName() + " hold lock"); Thread.sleep(5000L); System.out.println(Thread.currentThread().getName() + " release lock"); } } catch (Exception e) { e.printStackTrace(); } finally { try { lock.release(); } catch (Exception e) { e.printStackTrace(); } } } }
当然实际中会更加复杂,比如只是某些接口需要全局单点,但是服务的粒度又没有拆分到独立的微服务。另外,客户端宕机后锁是否自动释放也是要考虑的,否则其他节点就无法接管。
转自:https://www.cnblogs.com/zhjh256/archive/2004/01/13/9251061.html