作者:RednaxelaFX
链接:https://www.zhihu.com/question/287945354/answer/458761494
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ZGC所采用的算法就是Azul Systems很多年前提出的Pauseless GC
而实现上它介乎早期Azul VM的Pauseless GC与后来Zing VM的C4之间。
虽然Oracle出的各种介绍资料上都完全没有提及ZGC与Azul的Pauseless GC(下面简称Azul PGC)之间的关系,而且我们从外部也无法证实或否认Oracle GC团队在研发ZGC的时候是否参考了Azul的论文,所以还不至于扣上抄袭啊克隆啊之类的帽子,但就结果来看ZGC确实就是换了一通术语、纯软件实现的Azul PGC。
这周在Oracle的Santa Clara园区(旧Sun园区)刚开了JVMLS 2018,我也找机会跟ZGC的领队Per大大聊了下,抽样问了若干设计点细节之后更加确认了ZGC与Azul PGC之间的对应性——核心算法没有差异,所以想要了解原理的话只要读上面的Azul论文即可。
Azul PGC简单来说是:它是一个mark-compact GC,但是GC过程中所有的阶段都设计为可以并发的,包括移动对象的阶段,所以GC正常工作的时候除了会在自己的线程上吃点CPU之外并不会显著干扰应用的运行。为了实现上方便,PGC虽然算法上可以做成完全并发,Azul PGC在Azul VM里的实现还是有三个非常短暂的safepoint,其中第一个是做根集合(root set)扫描,包括全局变量啊线程栈啊啥的里面的对象指针,但不包括GC堆里的对象指针,所以这个暂停就不会随着GC堆的大小而变化(不过会根据线程的多少啊、线程栈的大小之类的而变化)。另外两个暂停也同样不会随着堆大小而变化。
这样,Azul一般在宣称PGC / C4的时候会很保守地说“暂停不会超过10ms”,实际上维持在最大暂停时间1ms并不是难事。注意是最大暂停时间,而不是平均、90%、99%。
ZGC采用了同样的原理,于是也拥有相似的特性。
这种并发算法的核心思想就是:
- 在标记阶段,与其说是标记对象(记录对象是否已经被标记),不如说是标记指针(记录GC堆里的每个指针是否已经被标记)。这就与传统的三色标记对象的GC算法有非常大的区别,虽然两者从收敛性上看是等价的——最终所有对象以及所有指针都会被遍历过。
- 在标记和移动对象的阶段,每次从GC堆里的对象的引用类型字段里读取一个指针的时候,这个指针都会经过一个“Loaded Value Barrier”(LVB)。这是一种“Read Barrier”(读屏障),会在不同阶段做不同的事情。最简单的事情就是,在标记阶段它会把指针标记上并把堆里的这个指针给“修正”到新的标记后的值;而在移动对象的阶段,这个屏障会把读出的指针更新到对象的新地址上,并且把堆里的这个指针“修正”到原本的字段里。这样就算GC把对象移动了,读屏障也会发现并修正指针,于是应用代码就永远都会持有更新后的有效指针,而不需要通过stop-the-world这种最粗粒度的同步方式来让GC与应用之间同步。
- LVB中有一点很重要,就是“self healing”性质:如果堆上有指针当前处于“尚未更新”的状态,一旦经过LVB之后就会被就地更新,于是在同一个GC周期内再次访问这个字段的话就不需要再修正了。这样LVB带来的性能开销(吞吐量的下降)就是非常短暂的,而不像Shenandoah GC所使用的Brooks indirection pointer那样一直都慢。
Azul PGC 与 Azul Zing VM里的C4 GC之间最大的区别就是,前者不分代,而后者是分两代的pauseless GC。在Zing的内部代码里,其实C4是叫做GPGC——Generational Pauseless GC。C4的New Generation与Old Generation采用的是完全一样的Pauseless算法,两代都同样(几乎)不暂停,New GC并不会导致完全stop-the-world。这跟HotSpot VM里的分代式GC实现们很不一样——那些Young GC都是会stop-the-world的。这是因为在Zing的应用场景里,New Generation可能就已经有几十GB了,如果完全stop-the-world那根本受不了。
ZGC目前不分代,所以跟Azul PGC更相似,而离C4还有距离。
至于为何ZGC目前不分代,有什么技术上的考量,在JVMLS 2018的ZGC Workshop里Per大大也给出了明确的回答:因为分代实现起来麻烦,想先实现出比较简单可用的版本;后续正在考量是添加分代版ZGC好还是添加一个Thread-Local GC作为ZGC的“前端”好,目前还在探索中。Per大大毫无遮掩地表示当前的ZGC如果遇到非常高的对象分配速率(allocation rate)的话会跟不上,目前唯一有效的“调优”方式就是增大整个GC堆的大小来让ZGC有更大的喘息空间。而添加分代或者Thread-Local GC则可以有效降低这种情况下对堆大小(喘息空间)的需求。
大概能猜出来,缩短时长的策略几乎都是从串行改为并行,那就看并行的话,困难在哪里
最重要一点从传统的write barrier转换到read barrier,在zgc里面叫做load barrier
其他的gc策略,需要write barrier,不需要read barrier,zgc则相反
因为并行gc的策略,read barrier是必需的,而write barrier则不是必需的
但是每一次程序access对象的时候,都需要将该屏障插入一次,cache中所有read的操作全部被kick out
这能解释为什么吞吐会比g1下降不到15%
为什么低延迟,请听我慢慢道来。
现代垃圾收集器的演进大部分都是往减少停顿方向发展。
像 CMS 就是分离出一些阶段使得应用线程可以和垃圾回收线程并发,当然还有利用回收线程的并行来减少停顿的时间。
基本上 STW 阶段都是利用多线程并行来减少停顿时间,而并发阶段不会有太多的回收线程工作,这是为了不和应用线程争抢 CPU,反正都并发了慢就慢点(不过还是得考虑内存分配速率)。
而 G1 可以认为是打开了另一个方向的大门:只回收部分垃圾来减少停顿时间。
不过为了达到只回收部分 reigon,每个 region 都需要 RememberSet 来记录各 region 之间的引用。这个内存的开销其实还是挺大的,可能会占据整堆的20%或以上。
并且 G1 还有写屏障的开销,虽说用了 logging wtire barrier,但也还是有开销的。
当然 CMS 也用了写屏障,不过逻辑比较简单,啥都没判断就单纯的记录。
其实 G1 相对于 CMS 只有在大堆的场景下才有优势,CMS 比较伤的是 remark 阶段,如果堆太大需要扫描的东西太多。
而 G1 在大堆的时候可以选择部分收集,所以停顿时间有优势。
今天的主角 ZGC 和 G1 一样是基于 reigon 的,几乎所有阶段都是并发的,整堆扫描,部分收集。
而且 ZGC 还不分代,就是没分新生代和老年代。
那它为啥比 G1 要牛皮?今天咱们就来盘一盘。
本文会先介绍 ZGC 的特性,或者说几个关键点,然后再简述下整体回收流程。
基本上看下来对 ZCG 心中就有数了,作为普通的 Javaer,了解到这个程度就差不多了。
好了,让我们进入今天的正题!
ZGC 的目标
垃圾收集器设计出来都有目标的,有些是为了更高的吞吐,有些是为了更低的延迟。
所以我们先看看 ZGC 的目标:


可以看到它的目标就是低延迟,保证最大停顿时间在几毫秒之内,不管你堆多大或者存活的对象有多少。
可以处理 8MB-16TB 的堆。
咱们就按 openjdk 的 wiki 来展开今天的内容。


关键字:并发、基于Region、整理内存、支持NUMA、用了染色指针、用了读屏障,对了 ZGC 用的是 STAB。
Concurrent
这个 Concurrent 的意思是和应用线程并发执行,ZGC 一共分了 10 个阶段,只有 3 个很短暂的阶段是 STW 的。
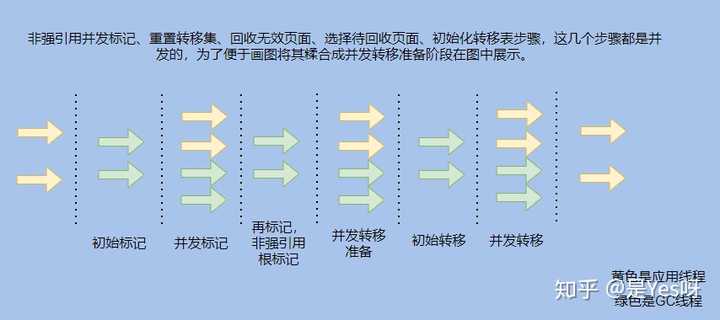
可以看到只有初始标记、再标记、初始转移阶段是 STW 的。
初始标记就扫描 GC Roots 直接可达的,耗时很短,重新标记一般而言也很短,如果超过 1ms 会再次进入并发标记阶段再来一遍,所以影响不大。
初始转移阶段也是扫描 GC Roots 也很短,所以可以认为 ZGC 几乎是并发的。
而且之所以说停顿时间不会随着堆的大小和存活对象的数量增加而增加,是因为 STW 几乎只和 GC Roots 集合大小有关,和堆大小没啥关系。
这其实就是 ZGC 超过 G1 很关键的一个地方, G1 的对象转移需要 STW 所以堆大需要转移对象多,停顿的时间就长了,而 ZGC 有并发转移。
不过并发回收有个情况就是回收的时候应用线程还是在产生新的对象,所以需要预留一些空间给并发时候生成的新对象。
如果对象分配过快导致内存不够,在 CMS 中是发生 Full gc,而 ZGC 则是阻塞应用线程。
所以要注意 ZGC 触发的时间。
ZGC 有自适应算法来触发也有固定时间触发,所以可以根据实际场景来修改 ZGC 触发时间,防止过晚触发而内存分配过快导致线程阻塞。
还有设置 ParallelGCThreads 和 ConcGCThreads,分别是 STW 并行时候的线程数和并发阶段的线程数来加快回收的速度。
不过 ConcGCThreads 数量需要注意,因为此阶段是和应用线程并发,如果线程数过多会影响应用线程。
其实 ZGC 的每个阶段都是串行的,所以理论上其实可以不需要分两类线程,那为什么分了这两类线程?
就是为了灵活设置。分成两类就可以通过配置来调优,达到性能最大值。
对了上面提到 ZGC 的 STW 和 GC Roots 集合大小有关系,所以如果在会生成很多线程、动态加载很多 ClassLoader 等情况下会增加 ZGC 的停顿时间。
这点需要注意。
Region-based
为了能更细粒度的控制内存的分配,和 G1 一样 ZGC 也将堆划分成很多分区。
分了三种:2MB、32MB 和 X*MB(受操作系统控制)。
下图为源码中的注释:


对于回收的策略是优先收集小区,中、大区尽量不回收。
Compacting
和 G1 一样都分区了所以肯定从整体来看像是标记-复制算法,所以也是会整理的。
因此 ZGC 也不会产生内存碎片。
具体的流程下文再做分析。
链接:https://www.zhihu.com/question/287945354/answer/2179263839
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
3、ZGC 原理
讲到这,开始正式进入主题:为什么 ZGC 能够做到低延时?
咱们看图说话:

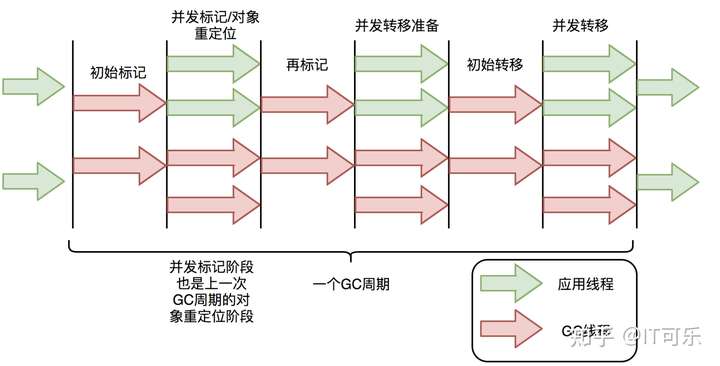
低延时结论:
ZGC在标记、转移和重定位阶段几乎都是并发。
在【初始标记】、【再标记】、【初始转移】这三个阶段只有 GC 线程,这就表示这三个阶段是 STW 的。其中,初始标记和初始转移分别都只需要扫描所有GC Roots,其处理时间和GC Roots的数量成正比,一般情况耗时非常短;再标记阶段STW时间很短,最多1ms,超过1ms则再次进入并发标记阶段。即,ZGC几乎所有暂停都只依赖于GC Roots集合大小,停顿时间不会随着堆的大小或者活跃对象的大小而增加。
关键技术
ZGC通过着色指针和读屏障技术,解决了转移过程中准确访问对象的问题,实现了并发转移。
GC 线程在转移对象的过程中,假设不是 STW,这也是 G1 垃圾收集器慢的原因(G1这个阶段会 STW),那么应用线程也在不断的访问对象,假设对象转移,但对象地址没有及时更新,就会造成访问旧地址的错误。
在ZGC中,应用线程访问对象将触发“读屏障”,如果发现对象被移动了,那么“读屏障”会把读出来的指针更新到对象的新地址上,这样应用线程始终访问的都是对象的新地址。那么,JVM是如何判断对象被移动过呢?就是利用对象引用的地址,即着色指针。
关于“读屏障”和“着色指针”的概念,我这里就不做过多的描述了。

4、ZGC 缺点
ZGC 快是快,特别是对于大堆和即时响应的系统特别有用,但是还是存在缺点的:
①、并发标记阶段是全堆标记,如果回收速度跟不上对象分配速度,会导致对象分配停顿。
②、GC线程并发导致 CPU 飙高。
怎么用大家做好取舍。