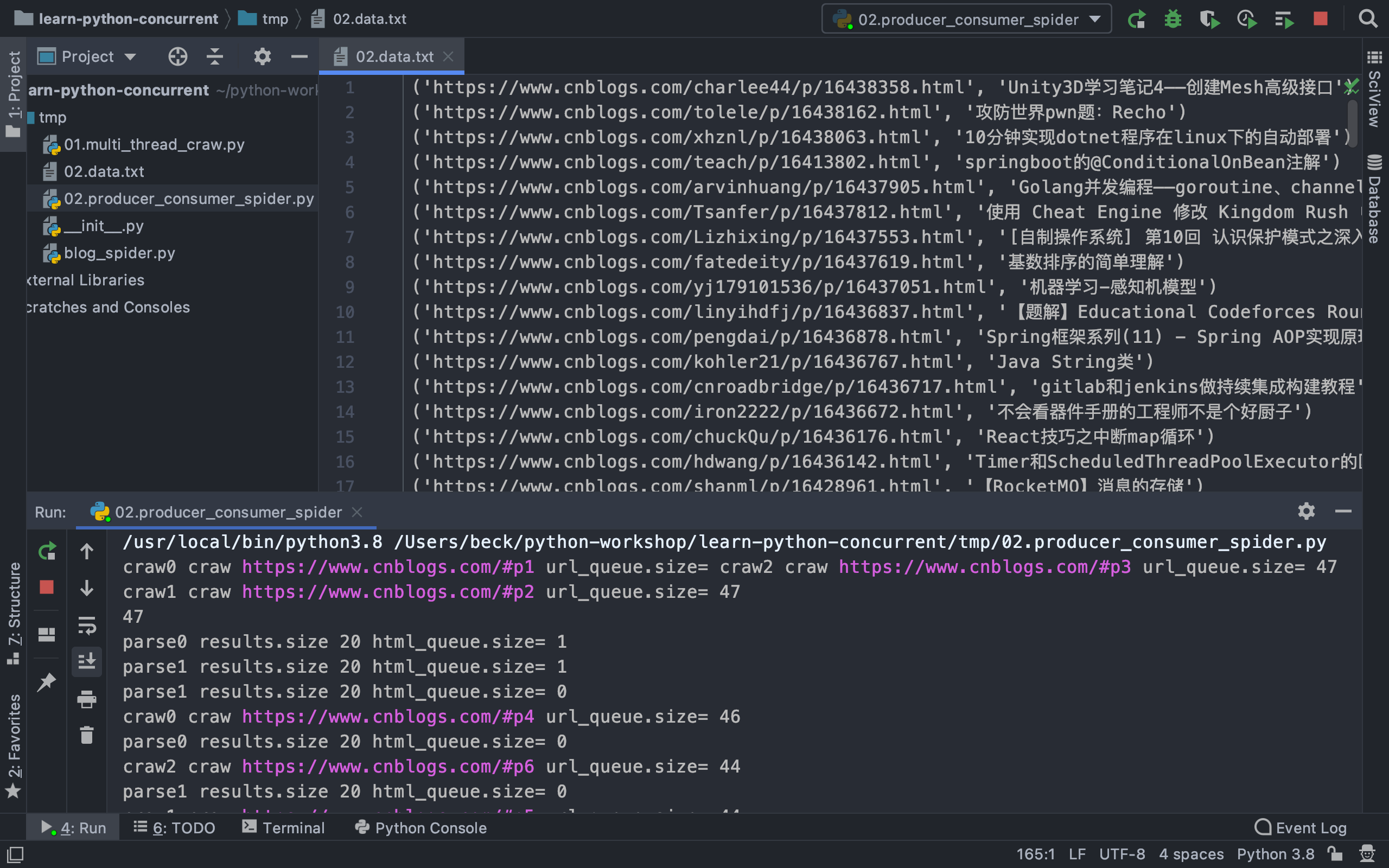
多组建的pipline技术架构
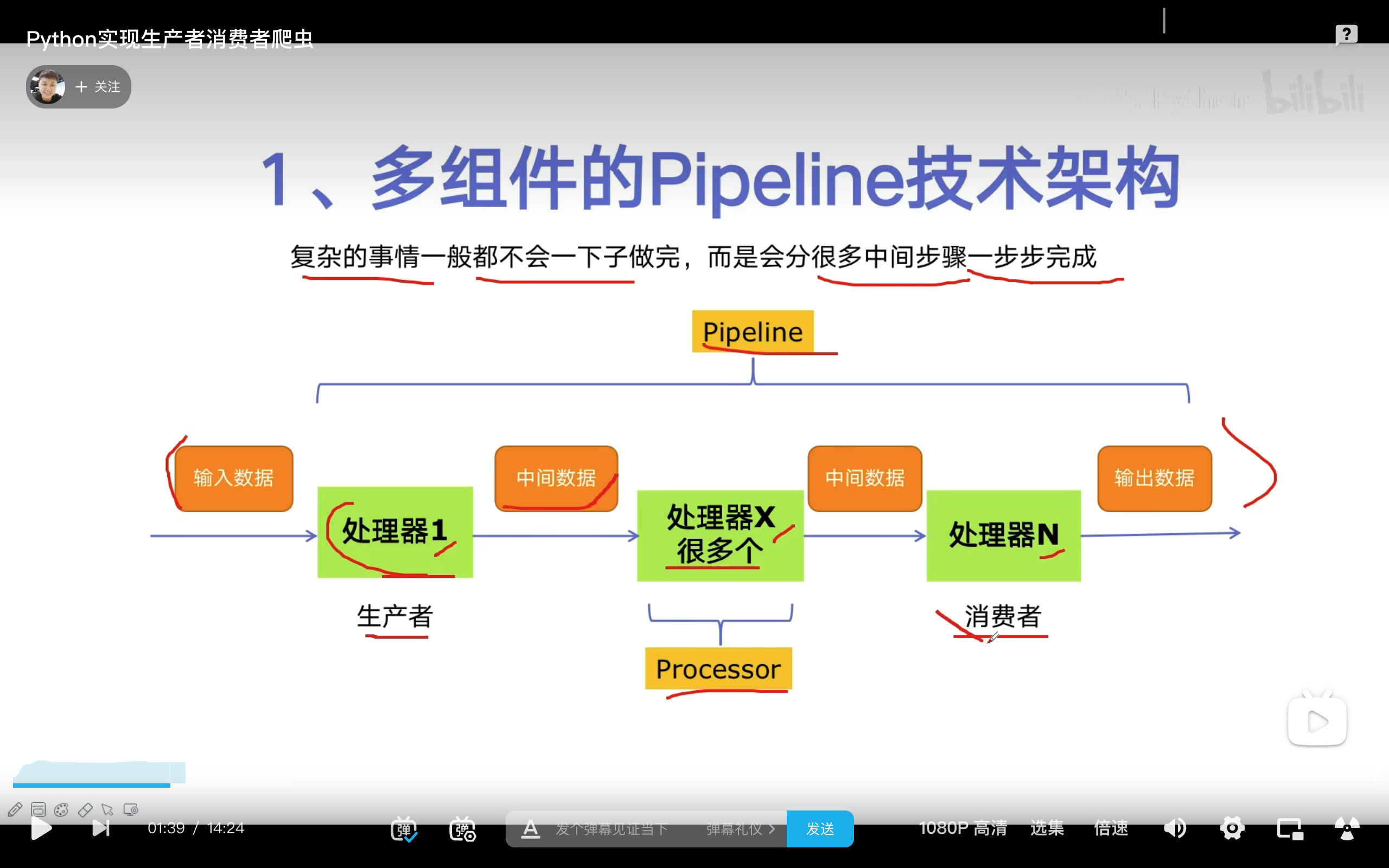
生产者消费者爬虫的架构
多进程数据通信的queue.Queue

线程安全:指的是多个线程不会冲突
get和put方法是阻塞的:当里面没有数据的时候,q.get()会卡住,直到里面有了数据把它取出来,q.put()当队列满了以后会卡住,直到有一个空闲的位置才能put进去
代码实现
tmp/blog_spider.py
import requests
from bs4 import BeautifulSoup
urls = [
f"https://www.cnblogs.com/#p{page}"
for page in range(1, 50+1)
]
def craw(url):
r = requests.get(url)
return r.text
def parse(html):
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all("a", class_="post-item-title")
return [(link["href"], link.get_text()) for link in links]
if __name__ == '__main__':
for result in parse(craw(urls[2])):
print(result)
tmp/02.producer_consumer_spider.py
import queue
import blog_spider
import time, random
import threading
#生产者
def do_craw(url_queue: queue.Queue, html_queue: queue.Queue):
while True:
url = url_queue.get()
html = blog_spider.craw(url)
html_queue.put(html)
print(threading.current_thread().name + f" craw {url}",
"url_queue.size=", url_queue.qsize())
time.sleep(random.randint(1, 2))
#消费者
def do_parse(html_queue: queue.Queue, fout):
while True:
html = html_queue.get()
results = blog_spider.parse(html)
for result in results:
fout.write(str(result) + "\n")
print(threading.current_thread().name + " results.size", len(results),
"html_queue.size=", html_queue.qsize())
time.sleep(random.randint(1, 2))
if __name__ == '__main__':
url_queue = queue.Queue()
html_queue = queue.Queue()
for url in blog_spider.urls:
url_queue.put(url)
for idx in range(3):
t = threading.Thread(target=do_craw, args=(url_queue, html_queue),
name=f"craw{idx}")
t.start()
fout = open("02.data.txt", "w")
for idx in range(2):
t = threading.Thread(target=do_parse, args=(html_queue, fout),
name=f"parse{idx}")
t.start()
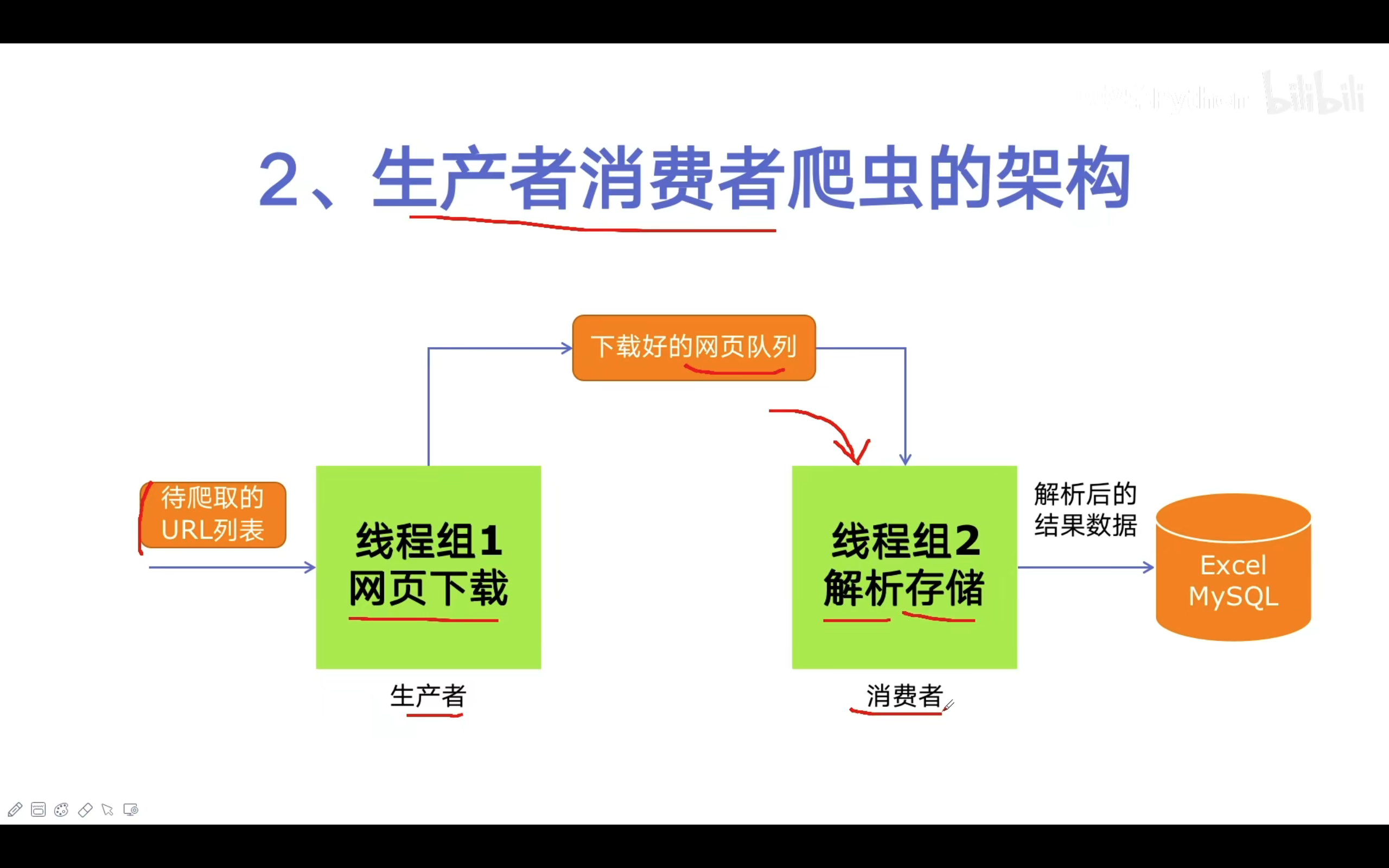
爬取结果