1、GC 日志输出
JVM 的参数配置其实变化也很大。就拿 GC 日志这一块来说,Java 9 几乎是推翻重来。
这个时候,再去看 jstat 已经来不及了,我们需要保留现场。
那在实践中,要怎么用呢?请看下面命令行。
Java 8
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintTenuringDistribution -Xloggc:/tmp/logs/gc_%p.log -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log -XX:-OmitStackTraceInFastThrow
然后我们来解释一下这些参数:
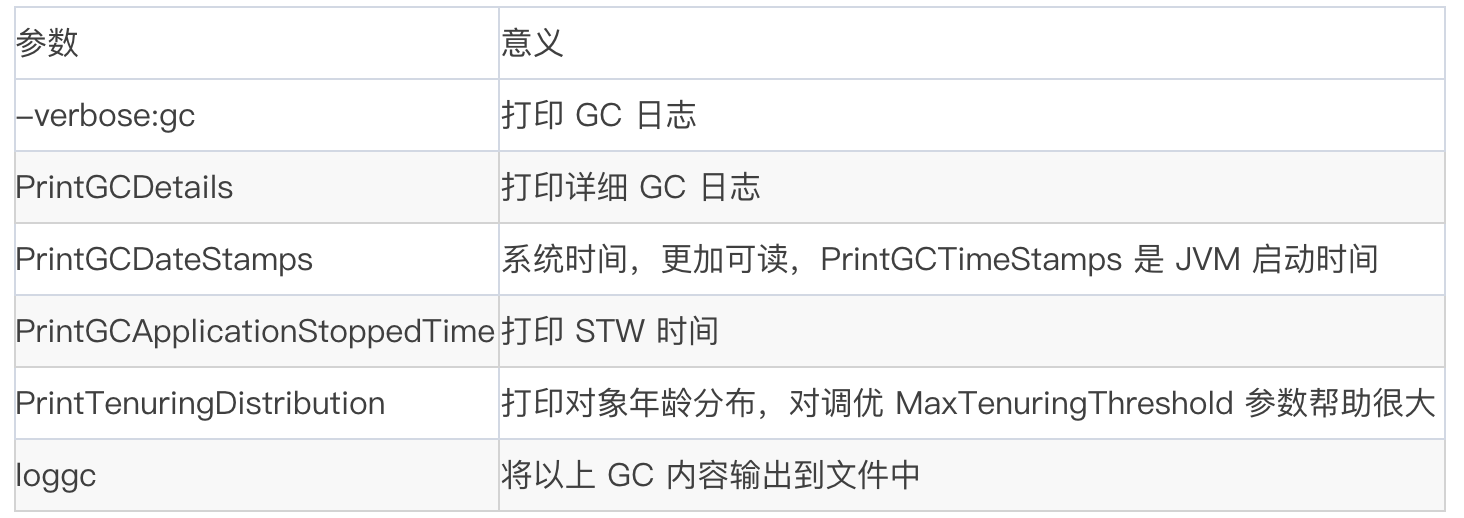
再来看下 OOM 时的参数:
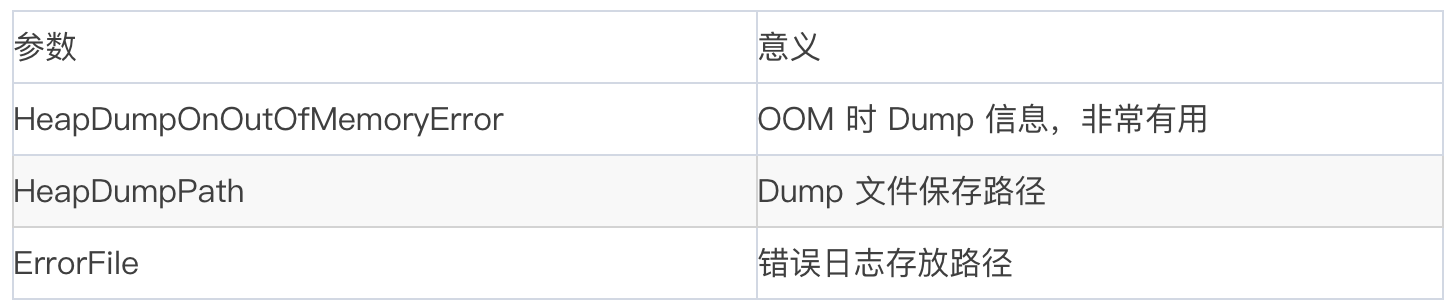
注意到我们还设置了一个参数 OmitStackTraceInFastThrow,这是 JVM 用来缩简日志输出的。
开启这个参数之后,如果你多次发生了空指针异常,将会打印以下信息。
java.lang.NullPointerException
java.lang.NullPointerException
java.lang.NullPointerException
java.lang.NullPointerException
在实际生产中,这个参数是默认开启的,这样就导致有时候排查问题非常不方便(很多研发对此无能为力),我们这里把它关闭,但这样它会输出所有的异常堆栈,日志会多很多。
-verbose:gc -Xlog:gc,gc+ref=debug,gc+heap=debug,gc+age=trace:file=/tmp/logs/gc_%p.log:tags,uptime,time,level -Xlog:safepoint:file=/tmp/logs/safepoint_%p.log:tags,uptime,time,level -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/logs -XX:ErrorFile=/tmp/logs/hs_error_pid%p.log -XX:-OmitStackTraceInFastThrow
可以看到 GC 日志的打印方式,已经完全不一样,但是比以前的日志参数规整了许多。
我们除了输出 GC 日志,还输出了 safepoint 的日志。这个日志对我们分析问题也很重要,那什么叫 safepoint 呢?
- safepoint 是 JVM 中非常重要的一个概念,指的是可以安全地暂停线程的点。
- 当发生 GC 时,用户线程必须全部停下来,才可以进行垃圾回收,这个状态我们可以认为 JVM 是安全的(safe),整个堆的状态是稳定的。
- 如果在 GC 前,有线程迟迟进入不了 safepoint,那么整个 JVM 都在等待这个阻塞的线程,会造成了整体 GC 的时间变长。
- 并不是只有 GC 会挂起 JVM,进入 safepoint 的过程也会。
如果面试官问起你在项目中都使用了哪些打印 GC 日志的参数,上面这些信息肯定是不很好记忆。你需要进行以下总结。比如:
“我一般在项目中输出详细的 GC 日志,并加上可读性强的 GC 日志的时间戳。特别情况下我还会追加一些反映对象晋升情况和堆详细信息的日志,用来排查问题。另外,OOM 时自动 Dump 堆栈,我一般也会进行配置”。
2、GC 日志的意义
我们首先看一段日志,然后简要看一下各个阶段的意义。
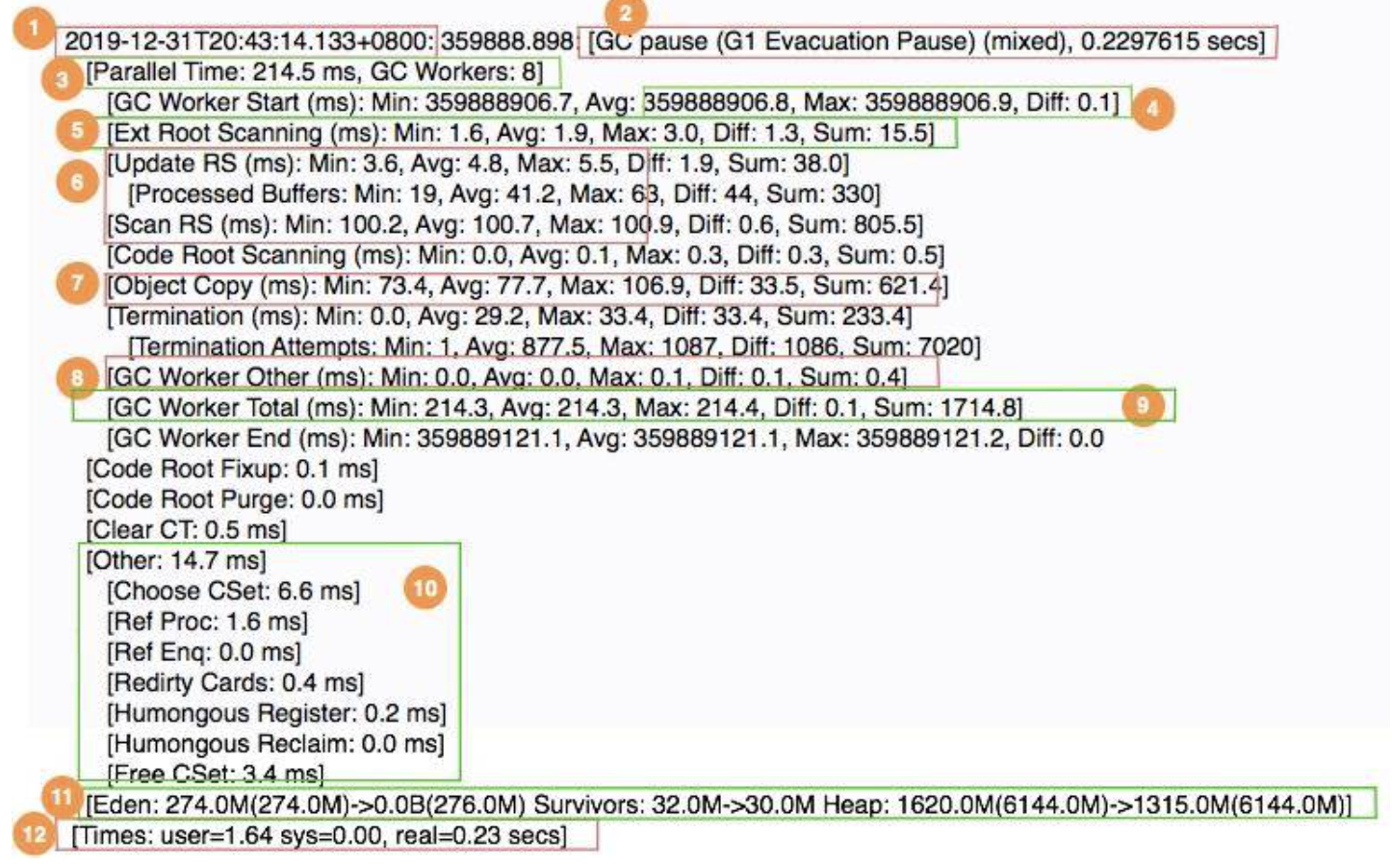
说明:
1、 表示 GC 发生的时间,一般使用可读的方式打印;
2、 表示日志表明是 G1 的“转移暂停: 混合模式”,停顿了约 223ms;
3、 表明由 8 个 Worker 线程并行执行,消耗了 214ms;
4、 表示 Diff 越小越好,说明每个工作线程的速度都很均匀;
5、 表示外部根区扫描,外部根是堆外区。JNI 引用,JVM 系统目录,Classloaders 等;
6、 表示更新 RSet 的时间信息;
7、 表示该任务主要是对 CSet 中存活对象进行转移(复制);
8、 表示花在 GC 之外的工作线程的时间;
9、 表示并行阶段的 GC 总时间;
10、表示其他清理活动;
11、表示收集结果统计;
12、表示时间花费统计。
- real 实际花费的时间,指的是从开始到结束所花费的时间。比如进程在等待 I/O 完成,这个阻塞时间也会被计算在内;
- user 指的是进程在用户态(User Mode)所花费的时间,只统计本进程所使用的时间,注意是指多核;
- sys 指的是进程在核心态(Kernel Mode)花费的 CPU 时间量,指的是内核中的系统调用所花费的时间,只统计本进程所使用的时间。
例如: [Times: user=0.42 sys=0.03, real=7.62 secs] 从日志可以看到在 GC 时用户态只停顿了 420ms,但真实的停顿时间却有 7.62 秒。
3、GC 日志 IO
ElasticSearch 的速度是非常快的,我们为了压榨它的性能,对磁盘的读写几乎是全速的。
它在后台做了很多 Merge 动作,将小块的索引合并成大块的索引。还有 TransLog 等预写动作,都是 I/O 大户。
使用 iostat -x 1 可以看到具体的 I/O 使用状况。
问题是,我们有一套 ES 集群,在访问高峰时,有多个 ES 节点发生了严重的 STW 问题。有的节点竟停顿了足足有 7~8 秒。
[Times: user=0.42 sys=0.03, real=7.62 secs] 从日志可以看到在 GC 时用户态只停顿了 420ms,但真实的停顿时间却有 7.62 秒。
盘点一下资源,唯一超额利用的可能就是 I/O 资源了(%util 保持在 90 以上),GC 可能在等待 I/O。
通过搜索,发现已经有人出现过这个问题,这里直接说原因和结果。
原因就在于:写 GC 日志的 write 动作,是统计在 STW 的时间里的。在我们的场景中,由于 ES 的索引数据,和 GC 日志放在了一个磁盘,GC 时写日志的动作,就和写数据文件的动作产生了资源争用。
解决方式:把 ES 的日志文件,单独放在一块普通 HDD 磁盘上就可以了。