awk也是用来处理文本的,awk语言可以从文件或字符串中基于指定规则浏览和抽取信息,可以实现数据查找、抽取文件中的数据、创建管道流命令等功能。
awk模式匹配
第一种方法打印空白行
将空白行打印出来,并输出this is a blank line.(有几行空白行就打印几行this is a blank line.)
awk '/^$/{print "this is a blank line."}' dim_ia_test.log
第二种方法调用awk打印空白行
cat scr.awk
/^$/{print "this is a blank line."}
执行命令:
awk -f scr.awk dim_ia_test.log
命令结果:

第三种方法打印空白行
cat scr1.awk
#!/bin/awk -f
/^$/{print "this is a blank line."}
将执行权限赋予脚本:chmod u+x scr1.awk
执行命令:
./scr1.awk dim_ia_test.log
执行结果:

awk之记录和域
将第二列、第一列、第四列、第三列打印出来(默认以空格分割)
awk '{print $2,$1,$4,$3}' dim_ia_test2.log
将全部列都打印出来(默认以空格分割)
awk '{print $0}' dim_ia_test2.log
将第三列内容打印出来(默认以空格分割)
awk 'BEGIN {one=1;two=2}{print $(one+two)}' dim_ia_test2.log
等价
awk '{print $3}' dim_ia_test2.log
-F为改变分隔符为-,将第三列内容打印出来
awk -F"-" '{print $3}' dim_ia_test2.log
awk关系运算符及其意义
< --小于
> --大于
<= --小于等于
>= --大于等于
== --等于
!= --不等于
~ --匹配正则表达式
!~ --不匹配正则表达式
awk 'BEGIN {FS=":"} $1~/Job/' dim_ia_test.log
全部域匹配05,并将含有05的行打印出来
awk 'BEGIN {FS=":"} $0~/05/' dim_ia_test.log
以:分割,如果满足第一个域小于第二个域,则打印该行的全部域
awk 'BEGIN {FS=":"}{if($1<$2) print $0}' dim_ia_test.log
|| --逻辑或
&& --逻辑与
! --逻辑非
awk 'BEGIN {FS=":"}{if($1<$2||$2>$3) print $0}' dim_ia_test.log
多条件模糊匹配,以:分割,如果满足第一个域含有数字3或者第二个域含有数字3,则打印该行的全部域
awk 'BEGIN {FS=":"}{if($1~3||$2~3) print $0}' dim_ia_test.log
awk算术运算符及其意义
+ --加
- --减
* --乘
/ --除
% --模
^或** --乘方
++x --在返回x值之前,x变量加1
x++ --在返回x值之后,x变量加1
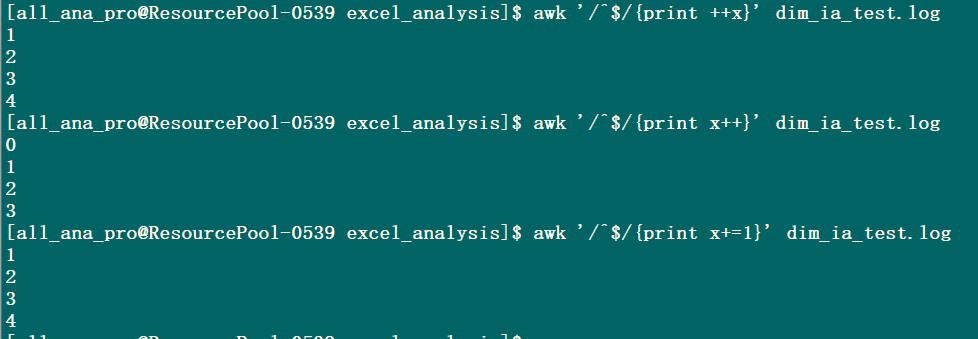
统计空白行,并以1,2,3,4………的形式打印出来
awk '/^$/{print x+=1}' dim_ia_test.log
统计空白行,并以0,1,2……的形式打印出来
awk '/^$/{print x++}' dim_ia_test.log
统计空白行,并以1,2……的形式打印出来
awk '/^$/{print ++x}' dim_ia_test.log
li ming,68,75,89,90 fang tianyi,60,90,70,80 fang xiaolong,81,72,64,95 fang tianxin,80,70,69,95
cat scr2.awk --awk脚本
#!/bin/awk -f
BEGIN {FS=","}
{total=$2+$3+$4+$5
avg=total/4
print $1,total,avg}
赋给脚本执行权限
chmod u+x scr2.awk
执行脚本
./scr2.awk sturecord
执行结果:
li ming 322 80.5 fang tianyi 300 75 fang xiaolong 312 78 fang tianxin 314 78.5
awk之系统变量
awk环境变量及其意义
$n --当前记录的第n个域,域间由FS分隔
$0 --记录的所有域
ARGC --命令行参数的数量
ARGIND --命令行中当前文件的位置(以0开始标号)
ARGV --命令行参数的数组
CONVFMT --数字转换格式
ENVIRON --环境变量关联数组
ERRNO --最后一个系统错误的描述
FIELDWIDTHS --字段宽度列表,以空格键分隔
FILENAME --当前文件名
FNR --浏览文件的记录数
FS --字段分隔符,默认是空格键
IGNORECASE --布尔变量,如果是真,则进行忽略大小写的匹配
NF --当前记录中的域数量
NR --当前记录数
OFMT --数字的输出格式
OFS --输出域分隔符,默认是空格键
ORS --输出记录分隔符,默认是换行符
RLENGHT --由math函数所匹配的字符串长度
RS --记录分隔符,默认是空格键
RSTART --由math函数所匹配的字符串的第一个位置
SUBSEP --数组下标分隔符,默认值是�34
以,号分隔,输出记录中的域数量,当前记录数,以及记录的所有域
awk 'BEGIN {FS=","} {print NF,NR,$0} ' sturecord
5 1 li ming,68,75,89,90 5 2 fang tianyi,60,90,70,80 5 3 fang xiaolong,81,72,64,95 5 4 fang tianxin,80,70,69,95
以,号分隔,输出记录中的域数量,当前记录数,以及记录的所有域,最后输出当前文件名
awk 'BEGIN {FS=","} {print NF,NR,$0} END {print FILENAME}' sturecord
5 1 li ming,68,75,89,90 5 2 fang tianyi,60,90,70,80 5 3 fang xiaolong,81,72,64,95 5 4 fang tianxin,80,70,69,95 sturecord
printf修饰符及其意义
- --左对齐
width --域的步长
.prec --小数点右边的位数
%c --ASCII字符
%d --整数型
%e --浮点数,科学记数法
%f --浮点数
%o --八进制数
%s --字符串
%x --十六进制数
以,号分隔,格式化输出第一列(字符串格式)、第二列(整型),第一列与第二列之间以tab间分隔,每行打印完即回车
awk 'BEGIN {FS=","} {printf("%s %d ",$1,$2)}' sturecord
li ming 68 fang tianyi 60 fang xiaolong 81 fang tianxin 80
awk 'BEGIN {FS=","} {printf("%s %f ",$1,$2)}' sturecord
li ming 68.800000 fang tianyi 60.600000 fang xiaolong 81.300000 fang tianxin 80.600000
将65转换为ASCII字符
awk 'BEGIN {printf("%c
",65)}'
A
以,号分隔,格式化输出第一列(字符串格式)、第二列(整型),这里第一列做了一个处理,-15表示该字符串长度控制在15位,并且左对齐,若字符串不足15位则用空格补全,第一列与第二列之间以tab间分隔,每行打印完即回车
awk 'BEGIN {FS=","} {printf("%-15s %f
",$1,$2)}' sturecord
li ming 68.800000 fang tianyi 60.600000 fang xiaolong 81.300000 fang tianxin 80.600000
以,号分隔,格式化输出第一列(字符串格式)、第二列(整型),我们在输出域上加了解释语言,第一列做了一个处理,-15表示该字符串长度控制在15位,并且左对齐,若字符串不足15位则用空格补全,第一列与第二列之间以tab间分隔,每行打印完即回车
awk 'BEGIN {FS=",";print "NAME MATHSCORE"} {printf("%-15s %f
",$1,$2)}' sturecord
NAME MATHSCORE li ming 68.800000 fang tianyi 60.600000 fang xiaolong 81.300000 fang tianxin 80.600000
以,号分隔,格式化输出第一列(字符串格式)、第二列(浮点型,浮点型保留一位小数),第一列与第二列之间以tab间分隔,每行打印完即回车
awk 'BEGIN {FS=","} {printf("%s %.1f
",$1,$2)}' sturecord
li ming 68.8 fang tianyi 60.6 fang xiaolong 81.3 fang tianxin 80.6
以,号分隔,格式化输出第一列(字符串格式)、第二列(浮点型,浮点型保留两位小数),第一列与第二列之间以tab间分隔,每行打印完即回车
awk 'BEGIN {FS=","} {printf("%s %.2f
",$1,$2)}' sturecord
li ming 68.80 fang tianyi 60.60 fang xiaolong 81.30 fang tianxin 80.60
以,号分隔,格式化输出第一列(字符串格式)、第二列(浮点型,浮点型保留两位小数,该浮点数长度控制在10位,且为右对齐),第一列与第二列之间以tab间分隔,每行打印完即回车
awk 'BEGIN {FS=","} {printf("%s %10.2f
",$1,$2)}' sturecord
li ming 68.80 fang tianyi 60.60 fang xiaolong 81.30 fang tianxin 80.60
总结printf修饰符的一版形式:%-width.prec格式控制符
awk之内置字符串函数
awk字符串函数及其意义
gsub(r,s) --在输入文件中用s替换r
gsub(r,s,t) --在t中用s替换r
index(s,t) --返回s中字符串第一个t的位置
length(s) --返回s的长度
match(s,t) --测试s是否包含匹配t的字符串
split(r,s,t) --在t上将r分成序列s
sub(r,s,t) --将t中第一次出现的r替换为s
substr(r,s) --返回字符串r中从s开始的后缀部分
substr(r,s,t) --返回字符串r中从s开始长度为t的后缀部分
首先指定域分隔符为",",输出的域分隔符为":",然后将第一个域中的fang替换为yuan,最后输出全部域,将含有yuan的所有行显示出来
awk 'BEGIN {FS=",";OFS=":"} gsub(/fang/,"yuan",$1) {print $0}' sturecord
yuan tianyi:60.6:90:70:80 yuan xiaolong:81.3:72:64:95 yuan tianxin:80.6:70:69:95
ph在gridsphere中第六位开始出现
awk 'BEGIN {print index("gridsphere","ph")}'
6
gridsphere的长度是10
awk 'BEGIN {print length("gridsphere")}'
10
测试D是否包含匹配字符串gridsphere,返回0为不包含
awk 'BEGIN {print match("gridsphere",/D/)}'
0
忽略大小写后,测试D是否包含匹配字符串gridsphere,返回4说明包含,d出现在第四个位置
awk 'BEGIN {IGNORECASE=1;print match("gridsphere",/D/)}'
4
先定义str变量,使用sub函数将第一次出现的pro定义成PRO
awk 'BEGIN {str="multiprocessor programming";sub(/pro/,"PRO",str);printf("%s
",str)}'
multiPROcessor programming
将sturecord中第一号域与fang匹配的记录中的第一次出现的60改成99
awk 'BEGIN {FS=","}{$1~fang sub(/80/,"99",$0);print $0}' sturecord
li ming,68.8,75,89,90 fang tianyi,60.6,90,70,99 fang xiaolong,81.3,72,64,95 fang tianxin,99.6,70,69,95
截取str从第六个字符开始的后缀部分
awk 'BEGIN {str="multiprocessor programming";print substr(str,6)}'
processor programming
截取str从第六个字符开始的长度为9的后缀部分
awk 'BEGIN {str="multiprocessor programming";print substr(str,6,9)}'
processor
向awk脚本传递参数
cat pass.awk
#!/bin/awk -f
NF!=MAX
{print ("The line "NR" does not have "MAX" filds.")}
赋权 chmod u+x pass.awk
执行命令:./pass.awk MAX=3 FS="," sturecord
li ming,68.8,75,89,90 The line 1 does not have 3 filds. fang tianyi,60.6,90,70,80 The line 2 does not have 3 filds. fang xiaolong,81.3,72,64,95 The line 3 does not have 3 filds. fang tianxin,80.6,70,69,95 The line 4 does not have 3 filds.
输出sturecord的所有记录,每行记录前加上其行号,重新定义OFS的值,改变输出域的分隔符
awk 'BEGIN {FS=","} {print NR,$0}' OFS=";" sturecord
1;li ming,68.8,75,89,90 2;fang tianyi,60.6,90,70,80 3;fang xiaolong,81.3,72,64,95 4;fang tianxin,80.6,70,69,95
条件语句if的语法
if(条件表达式)
动作1
[else
动作2]
样例
awk 'BEGIN {if (x==y) print "x与y相等"}' x=1 ;y=1
while(条件表达式)
动作
动作
while(条件表达式)
动作
awk之数组
将原始定义的数组打印出来
awk 'BEGIN{data[10.15]="1200";printf("<%s>
",data[10.15])}'
关键字in用于判断元素10.15是否在数组中,如果存在,则输出found element!
awk 'BEGIN{data[10.15]="1200";if("10.15" in data) print "found element!"}'
将abc/def/lih分成3个元素存储在数组str中
awk 'BEGIN{print split("abc/def/lih",str,"/")}'
3
将第一个域按空格拆分,存到name数组中
awk 'BEGIN{FS=","}{print split($1,name," ")}' sturecord
2 2 2 2
演示split所生成的数组
查看脚本:cat array.awk
#!/bin/awk -f
BEGIN {FS=","}
{split($1,name," ");
for(i in name) print name[i]}
赋权: chmod u+x array.awk
执行:./array.awk sturecord
li ming fang tianyi fang xiaolong fang tianxin
等价于:awk 'BEGIN{FS=","}{split($1,name," ");for(i in name)print name[i]}' sturecord