【ElasticSearch(一)】ElasticSearch简介和基本概念
一、什么是 Elasticsearch
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。
Elasticsearch 在 Apache Lucene 的基础上开发而成,由 Elasticsearch N.V.(即现在的 Elastic)于 2010 年首次发布。Elasticsearch 以其简单的 REST 风格 API、分布式特性、速度和可扩展性而闻名,是 Elastic Stack 的核心组件;Elastic Stack 是适用于数据采集、充实、存储、分析和可视化的一组开源工具。人们通常将 Elastic Stack 称为 ELK Stack(代指 Elasticsearch、Logstash 和 Kibana),目前 Elastic Stack 包括一系列丰富的轻量型数据采集代理,这些代理统称为 Beats,可用来向 Elasticsearch 发送数据。
官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/7.14/getting-started.html
二、MySql与ElasticSearch
MySql专攻于数据的持久化存储与管理,也就是CRUD。
ElasticSearch更善于百万数据量的检索,mysql在这样的场景下检索太慢。
三、Elasticsearch 的用途是什么
Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
- 应用程序搜索
- 网站搜索
- 企业搜索
- 日志处理和分析
- 基础设施指标和容器监测
- 应用程序性能监测
- 地理空间数据分析和可视化
- 安全分析
- 业务分析
四、底层实现
Elastic的底层是开源库 Lucene,但是你没法直接用 scene,必须自己写代码去调用它的接口。 Elastic是 Lucene的封装,提供了 REST API的操作接口,开箱即用。
REST API:天然的跨平台。
五、基本概念
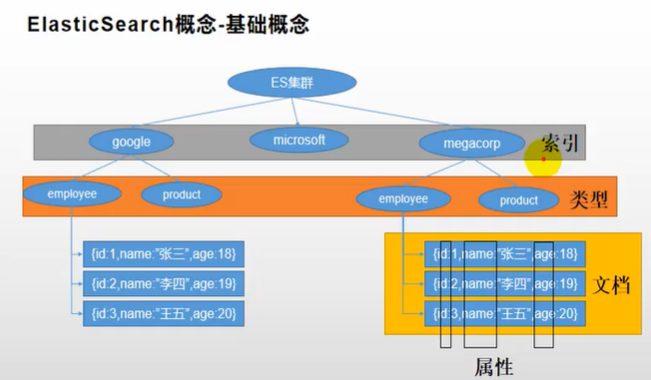
- 索引(index)
动词,相当于MySQL的insert
名词,相当于MySQL的Datebase
- 类型(Type)
在 Index(索引)中,可以定义一个或多个类型。类似于 MySQL中的 Table;每一种类型的数据放在一起;
- PS:在ES 7中Type已经废除了,所有文档直接存在索引下。
- 文档(Document)
保存在某个索引(Index)下,某种类型(Type)的一个文档(Document),文档是 JSON格式的。一个Document就像是 MySQL中的某个 Table里面的一条数据。
六、倒排索引
为什么ElasticSearch得以在百万数据量中快速检索出我们想要的内容呢?
就是因为在ES中,存储数据的同时,维护了一张倒排索引表。
如何得到倒排索引表,并在其中搜索的,过程如下:
-
得到倒排索引表,需要先分词:将要保存的记录拆分为单词
-
得到一张倒排索引表
-
将要检索的整句也拆分为单词,在刚刚得到的倒排索引表中匹配
-
根据相关性得分进行结果排序,选取得分最高的
相关性得分:整句1被拆分为4个单词,匹配到了2个,2/4。句子2被拆分为2个单词,匹配到了2个,2/2。那么,整句2相关性更高。
举个例子:
-
现在保存以下记录
1-红海行动
2-探索红海行动
3-红海特别行动
4-红海记录篇
5-特工红海特别探索
得到这样一张倒排索引表:

-
要检索关键字:红海行动
拆分为了单词:红海、行动
-
相关记录有1,3,4,5
选取相关性得分最高的:1相关性2/2,3相关性2/3,4相关性1/2,5相关性2/4。所以1相关性最高。