前言:
作为Hadoop生态系统中重要的一员, HBase作为分布式列式存储, 在线实时处理的特性, 备受瞩目, 将来能在很多应用场景, 取代传统关系型数据库的江湖地位. 本篇主要讲述面向时间序列/面检索的应用场景时, 如何利用HBase的特性去处理和优化.
构造应用场景
某气象局对各个站点的信息进行采集和汇总, 这些信息包括站点id, 时间点, 采集要素(要素特别多). 然后对这些采集的数据, 提出如下检索需求:
1). 时间序列检索(检索出该站点的在某个时间范围内的全要素信息)
2). 面检索(检索出在某个时间点, 各个站点在具体时间点的某要素信息)
而其数据信息的特别如下:
1). 要素种类多, 气象涉及的观测元素多(湿度, 温度, 风向等等)
2). 每个站点收集部分信息, 每个站点各司其职(观测点的重新不一样)
由此可见数据的分布是呈现大宽表的形式, 列多且稀疏的方式分布.
存储选型
对比传统关系型数据和HBase, 对照的衡量参数如下:
| 存储选型 | 可扩展性 | 索引支持 | 事务支持 | 存储模式 | 应用场景 |
| Oracle/DB2(CA) | 不支持水平扩容 | 多索引支持 | 支持事务 | 行式存储(固定的schema, 对稀疏的列数据支持差) | 银行金融机构(对数据一致性要求高的场所) |
| Mysql Cluster(AP) | 支持水平扩容(分库分表, hash型) | 多索引支持 | 不支持事务(跨库) | 行式存储(固定的schema, 对稀疏的列数据支持差) | 互联网/移动互联网(追求高并发/高性能) |
| HBase(CP) | 支持水平扩容(按key范围来划分region, 区间型) | 无索引, 基于key/value | 不支持事务 | 列式存储(不固定的schema, 对稀疏的列数据支持好) | 大数据领域 |
评注: CAP理论, 任何的分布式系统中, 只能最多满足CAP(一致性/高可用性/分区容忍性)中的两种.
由以上图数据, 对比, 我们可以发现, 传统关系型数据库很难满足大宽表(列多且稀疏)的数据存储, 因此我们就选用HBase作为我们的存储模型.
检索分析
HBase作为分布式列式存储, 对列多且稀疏分布的数据支持非常的好. 而对于实时检索, HBase借助rowkey来实现, 其支持key的范围/前缀搜索, 检索性能非常好. 因此要应用好hbase, 其rowkey的设计成为至关重要的一环. 根据实战的经验, rowkey由多个字段构成且支持key前缀检索, 这有点类似与传统关系型数据库的复合索引. 但不足的方面是, hbase表只有一个rowkey, 换句话说就是只有一个索引, 同时多个字段组成的rowkey, 需要等宽字节来构建它. 这些因素就对上述的检索需求产生了影响.
回到最初的应用场景, 其检索需求有时间序列检索和面检索, rowkey设计方案如下:
1). rowkey格式: timestamp:site_id:others, 其把时间字段作为rowkey的前缀, 对面检索(检索某个时间点, 列出各个站点的要素信息)友好, 而对时间序列检索(检索该站点在某个时间范围的要素检索)不友好. 前者利用到了rowkey前缀, 后者利用不到, 因此扫描范围变大, 效率迅速降低.
2). rowkey格式: site_id:timestamp:others, 把站点id放在rowkey的前缀, 则结果恰好于上相反.
由此可见, 两种rowkey设计方案, 都无法同时满足时间序列检索和面检索. 那我们该这么办?
数据双写, 采用数据冗余的方式, 构建两张表. 一张表采用timestamp:site_id:others作为rowkey的设计方案, 另一张则采用site_id:timestamp:others作为rowkey的设计方案. 同时这两张表的数据内容完全一样, 这样就能满足上述的时间序列检索和面检索的需求了. 这种冗余方案, 在分布式mysql集群中, 被广泛的运用.
评注: 数据双写, 是作为HA(高可用性)的一种方案, 常用的HA策略有主从备份(存在单点故障).
写优化
尽管数据双写方案解决了上述检索需求(读性能高), 但以tiemstamp作为rowkey前缀的hbase表, 存在写入热点问题. 因为hbase的region是按rowkey的范围来划分的, 而数据的时间密集性很高, 导致几乎所有的数据都搁在同一个region上, 导致写热点问题. 因此我们需要对数据双写方案进行补充, 使得能够解决数据写入热点问题.
rowkey前缀加salt, 采用随机/hash(站点)的方式生成salt, 这样分散了写入, 避免了热点问题. 当然加salt是有代价的, 它加大读取数据的难度, 因为原本连续的数据被分散到了不同region上.
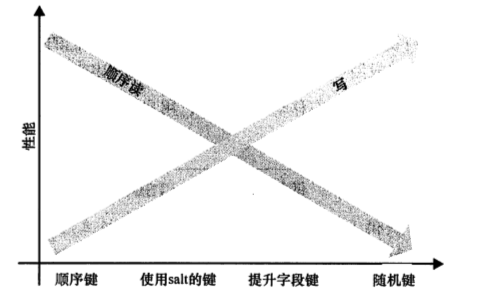
该图取之书籍<<hbase权威指南>>, 表明了不同的salt选择对读写性能的影响.
最终方案:
针对该应用场景, 采用HBase作为底层储存方案.
1). 数据双写的模式, 构建两张表, 数据冗余.
2). 表A以hash(site_id):timestamp:site_id:others作为rowkey, hash(site_id)表示对站点id取模作为salt.
3). 表B以site_id:timestamp:others作为rowkey, 站点(site_id)个数较多, 分散性好.