一: 常用sql语句:
sql顺序:select [distinct] * from 表名
[where
group by
having
order by
limit];
查询某段时间内的数据: https://www.cnblogs.com/benefitworld/p/5832897.html
1.查询当天的数据: SELECT * from 表名 where to_days(时间字段名) = to_days(now());
2.查询昨天的数据: SELECT * FROM 表名 WHERE TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) <= 1 and TO_DAYS( NOW( ) ) - TO_DAYS( 时间字段名) > 0;
3.查询近7天的数据: SELECT * FROM 表名 where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(时间字段名);
4.查询本周的数据: SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now());
5.查询上周的数据: SELECT name,submittime FROM enterprise WHERE YEARWEEK(date_format(submittime,'%Y-%m-%d')) = YEARWEEK(now())-1;
6.查询本月的数据: SELECT * FROM 表名 WHERE DATE_FORMAT( 时间字段名, '%Y%m' ) = DATE_FORMAT( CURDATE( ) , '%Y%m' );
7.查询上个月的数据: SELECT * FROM 表名 WHERE PERIOD_DIFF( date_format( now( ) , '%Y%m' ) , date_format( 时间字段名, '%Y%m' ) ) =1;
8.查询本季度的数据: SELECT * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(now());
9.查询上季度的数据: SELECT * from `ht_invoice_information` where QUARTER(create_date)=QUARTER(DATE_SUB(now(),interval 1 QUARTER));
10.查询本年的数据: SELECT * from `ht_invoice_information` where YEAR(create_date)=YEAR(NOW());
11.查询上年的数据: SELECT * from `ht_invoice_information` where year(create_date)=year(date_sub(now(),interval 1 year));
12.查询距离现在6个月的数据: SELECT name,submittime from enterprise where submittime between date_sub(now(),interval 6 month) and now();
1.查询每天的数据量: SELECT DATE_FORMAT(create_time,'%Y-%m-%d') create_time, count(1) num from core_user GROUP BY DATE_FORMAT(create_time,'%Y-%m-%d');
2.查询近7天内每天的数据量: SELECT DATE_FORMAT(create_time,'%Y-%m-%d') create_time, count(1) num from core_user where DATE_SUB(CURDATE(), INTERVAL 7 DAY) <= date(create_time) GROUP BY DATE_FORMAT(create_time,'%Y-%m-%d');
3.查询一天中每个小时记录的数量: SELECT HOUR(e.time)as Hour, COUNT(*) as Count FROM error_log e WHERE e.date = '2017-09-02' GROUP BY HOUR(e.time) ORDER BY Hour(e.time);
4.查询一天中每半个小时记录的数量: SELECT HOUR(e.time)as Hour,FLOOR(MINUTE(e.time)/30) as M, COUNT(*) as Count FROM error_log e WHERE e.date = '2017-09-02' GROUP BY FLOOR(MINUTE(e.time)/30),HOUR(e.time) ORDER BY Hour(e.time);
5.查询近七天,没有数据则补0:https://blog.csdn.net/ouyang111222/article/details/77638826
1. 使用group by后显示每个组中所包含的某个字段的所有值,使用group_concat(字段名),可以将多个值拼接为一个值:
select dept,group_concat(name) from emp group by dept;
2. 计算每个部门每个岗位的平均工资: select dept,job,avg(salary) from emp group by dept,job;
3. 查询岗位平均薪资高于6000的岗位名称和平均薪资: select job,avg(salary) from emp group by job having avg(salary) > 6000;
4. 多个字段去重:distinct colum1, colum2 具体可看:https://www.cnblogs.com/rainman/archive/2013/05/03/3058451.html
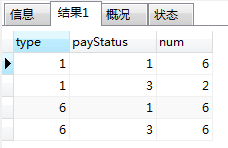
5. group by 多个字段:select `type`, pay_status payStatus, count(1) num from pay_record group by `type`, pay_status
结果,先根据第一个字段分组,然后依次往后再进行细分组,如下图:
6. sql查询不为空不为null的值:SELECT * FROM 表名 WHERE 字段名 IS NOT NULL AND 字段名 <> '';
7. sql查询去重某一字段(下划线代表,且重复数量大于1):select * from table group by name having count(name) >1
二:遇到的bug
1. mybatis中对于特殊字符的处理,如“<”, 会报错,此时可以用 <![CDATA[<]]> 对特殊字符进行处理
<if test="applyTime1 != null and applyTime1 != ''"> AND cbi.apply_time <![CDATA[>=]]> '${applyTime1} 00:00:00' </if>
2. case when ... then ... when .. then .. end as ..
3. 批量更新foreach
<if test="ids != null and ids != ''"> AND id in <foreach collection="ids" item="id" open="(" separator="," close=")"> #{id} </foreach> </if>
4. 在用mybatis时没有用实体作为返回(用的是Map) 因此出现了 在返回参数为null的时候 不会返回字段 https://blog.csdn.net/zkd12344/article/details/53261253
解决方法: 在mybatis-config.xml中配置
<settings>
<setting name="cacheEnabled" value="true"/>
<setting name="callSettersOnNulls" value="true"/>
</settings>

5. 排序更改问题:要求,更改一个排序后,其他的排序做相应改变,如,原第五现在改为第三,则原来的三四则变为四五;
添加排序字段:查询时,按照排序字段进行排序,排序改动时,改变相应的排序字段的值即可
(1) 改变其它受影响的记录的排序字段值:
UPDATE menu_table SET order_number = order_number + #{num} where user_id = #{userId} and type = #{type} and `status` = 1 <if test="startOrder != null and startOrder != ''"> and order_number <![CDATA[>=]]> #{startOrder} </if> <if test="endOrder != null and endOrder != ''"> and order_number <![CDATA[<=]]> #{endOrder} </if>
(2) 改变被改变顺序的记录的排序字段值:
UPDATE menu_table SET order_number = #{newOrder} where user_id = #{userId}
6. mybatis中 模糊查询 like拼接问题(concat函数)
<!-- 使用concat(str1,str2)函数将两个参数连接 -->
<if test="mobile != null and mobile != ''"> and cu.user_name like concat(concat("%",#{mobile}),"%") </if>
三:mysql优化:https://www.cnblogs.com/jimoer/p/10226952.html
1. 在设计表时要遵循几个基本原则:
a. 线上业务尽量避免使用外键、存储过程、分区表、触发器等。
b. 不在数据库中存储图片、文件等大数据。
c. 尽量避免使用TEXTBLOB等类型的大字段。
d. 拆分大字段和访问频率低的字段,分离冷热数据。
e. 不同的业务使用不同的数据库,禁止混合使用。
2. 索引优化:
a. 主键原则:
(1) 表必须有主键。
(2) 不使用更新频繁的列。
(3) 忌用字符串列做主键。
(4) 不使用UUID/MD5等生成的随机数做主键。
(5) 推荐用独立于业务的AUTO_INCREMENT列或全局ID生成器做代理主键。
b. 最左前缀原则

c. 索引数据控制
(1) 单张表索引数量建议不超过5个。
(2) 单个索引中的字段建议不超过5个。
(3) 字符串适度使用前缀索引。
(4) 索引不是越多越好,能不添加的索引尽量不要添加。
d. 索引禁忌
(1) 不在低区分度的列上建立索引,例如:“性别”。
(2) 尽量避免%前导查询,如like "%ab"。
(3) 尽量避免负向查询,如not in /like。
(4) 避免全表扫描以及频繁的回表操作
3. sql优化:
a. 基本原则
(1) SQL尽可能简单,线上尽可能少使用大SQL,使用简单小SQL。
(2) 尽可能少使用存储过程/触发器/函数,减少MySQL端的数学运算和逻辑判断。(不易于扩展)
(3) 使用预编译语句,降低SQL注入概率。
(4) 尽量少用select * ,只取需要的数据列。(可降低磁盘I/O,有机会只走复合索引,缓存使用降低。)
b. 避免隐式转换
(1) where条件比较,字段类型和传入值必须保证:数字对数字,字符对字符。
实例:`remark` varchar(50) NOT NULL COMMENT '备注,默认为空',
SELECT id, gift_ code FROM gift Where deal_ id = 640 AND remark=115127; 1 row in set (0.14 sec)
SELECT id, gift_ code FROM pool gift Where deal_ id = 640 AND remark='115127' ;1 row in set (0.005 sec)
当remark传入int类型的值后,查询时间0.14秒,传入字符类型后只需要0.005秒。
c. 不在索引列进行数学运算和函数运算。(索引字段慎用函数运算,MySQL的优化器对函数运算识别不出来时会直接走全表扫描。)
d. 分页优化
传统查询时: limit 10000,10; 偏移量越大则越慢。查询的时候要一步一步遍历到第10010条记录,然后取后10条记录,前面的全部抛弃掉。
sql优化: select * from table where id>=(select id from table limit 10000,1) limit 10;
验证:
传统查询: select * from table_test limit 500000, 10; --2.740s 优化后: select * from table_test where id >= (select id from table_test limit 500000, 1) limit 10; --0.172s
以上仅为本人后续回忆大纲,具体优化请参考上边提到的文章:https://www.cnblogs.com/jimoer/p/10226952.html