- 尽量不要将 secondarynamede 和 namenode 放在同一台机器上。
1. NameNode
NameNode 主要是用来保存 HDFS 的元数据(metadata,描述数据的数据)信息,比如命名空间信息,块信息等。当它运行的时候,这些信息是存在内存中的。但是这些信息也可以持久化到磁盘上。
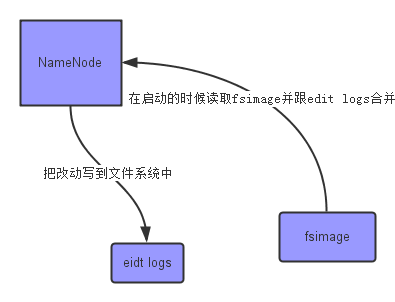
上面的这张图片展示了 NameNode 怎么把元数据保存到磁盘上的。这里有两个不同的文件:
- fsimage - 它是在 NameNode 启动时对整个文件系统的快照
- edit logs - 它是在 NameNode 启动后,对文件系统的改动序列
只有在 NameNode 重启时,edit logs才会合并到 fsimage 文件中,从而得到一个文件系统的最新快照。但是在产品集群中 NameNode 是很少重启的,这也意味着当NameNode运行了很长时间后,edit logs文件会变得很大。在这种情况下就会出现下面一些问题:
- edit logs 文件会变的很大,怎么去管理这个文件是一个挑战。
- NameNode 的重启会花费很长时间,因为有很多改动[笔者注:在edit logs中]要合并到 fsimage 文件上。
- 如果NameNode挂掉了,那我们就丢失了很多改动因为此时的 fsimage 文件非常旧。[笔者注: 笔者认为在这个情况下丢失的改动不会很多, 因为丢失的改动应该是还在内存中但是没有写到 edit logs 的这部分。]
因此为了克服这个问题,我们需要一个易于管理的机制来帮助我们减小edit logs文件的大小和得到一个最新的 fsimage 文件,这样也会减小在NameNode上的压力。这跟 Windows 的恢复点(restore point)是非常像的,Windows 的恢复点机制允许我们对 OS 进行快照(snapshot),这样当系统发生问题时,我们能够回滚到最新的一次恢复点上。
SecondaryNameNode 就是来帮助解决上述问题的,它的职责是合并 NameNode 的 edit logs 到 fsimage(FileSystem 镜像)文件中。
1. Secondary NameNode: 它究竟有什么作用?
在Hadoop中,有一些命名不好的模块,Secondary NameNode 便是其中之一。从名字上看,它给人的感觉就像是 NameNode 的备份。但它实际上却不是。很多 Hadoop 的初学者都很疑惑,Secondary NameNode究竟是做什么的,而且它为什么会出现在 HDFS 中。因此,在这篇文章中,我想要解释下Secondary NameNode 在 HDFS中所扮演的角色。
从它的名字来看,你可能认为它跟 NameNode 有点关系。没错,你猜对了。
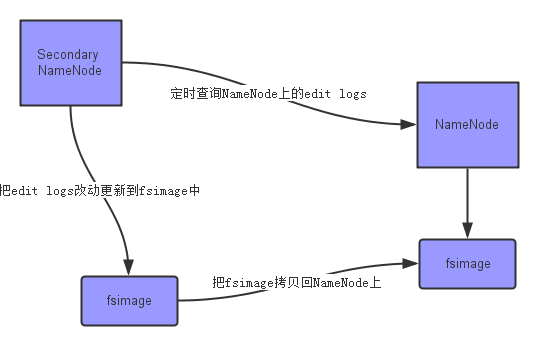
上面的图片展示了 Secondary NameNode 是怎么工作的。
首先,它定时到 NameNode 去获取edit logs,并更新到 fsimage 上。[笔者注:Secondary NameNode自己的fsimage]
一旦它有了新的 fsimage 文件,它将其拷贝回 NameNode 中。
NameNode 在下次重启时会使用这个新的 fsimage 文件,从而减少重启的时间。
Secondary NameNode 的整个目的是在 HDFS 中提供一个检查点。它只是NameNode 的一个助手节点。这也是它在社区内被认为是检查点节点的原因。
现在,我们明白了 Secondary NameNode所做的不过是在文件系统中设置一个检查点来帮助 NameNode 更好的工作。它不是要取代掉 NameNode 也不是 NameNode 的备份。所以从现在起,让我们养成一个习惯,称呼它为检查点节点吧。