在多线程编程中必须考虑到不同的线程对同一个变量进行读写访问引起的数据竞争问题。如果线程间没有互斥机制,则不同线程对同一变量的访问顺序是不确定的,有可能导致错误的执行结果。
OpenMP中有两种不同类型的线程同步机制,一种是互斥机制,一种是事件同步机制。
互斥锁机制的设计思路是对一块共享的存储空间进行保护,保证任何时候最多只能有一个线程对这块存储空间进行访问,从而保证数据的完整性,这块存储空间称为“临界区”。可以通过critical、atomic等制导指令以及API中的互斥函数来实现。
事件同步机制的设计思路是控制线程的执行顺序,可以通过设置barrier同步路障、ordered定序区段、matser主线程执行等实现。
互斥锁之critical定义临界区
使用critical定义临界区的格式如下:
#pragma omp critical {需要被保护的代码块}
例如如下示例:
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
int sum = 0;
#pragma omp parallel for
for (int i = 0; i < 10000; i++)
{
#pragma omp critical
{
sum += i;
}
}
cout << sum << endl;
system("pause");
}加上critical之后可以保证每次执行结果总是正确的,值为49995000,但如果不加critical语句,结果可能不确定,某次执行的结果为:46932347。
互斥锁之atomic原子操作
制导指令critical可以定义一个任意大小的代码块作为临界区保护,atomic原子操作应用在单条赋值语句中。
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
int sum = 0;
#pragma omp parallel for
for (int i = 0; i < 10000; i++)
{
{
#pragma omp atomic
sum += i;
}
}
cout << sum << endl;
system("pause");
}事件同步之barrier(同步路障)
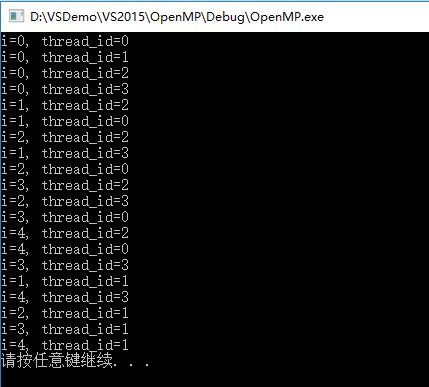
barrier是OpenMP中线程同步的一种方法,在多线程代码块中插入barrier,则先完成计算任务的线程到达此处会等待,直到最后一个线程也完成了计算任务。barrier相当于设置了一个线程的集合点,所有线程都到达之后才能继续往下执行。
#include<iostream>
#include"omp.h"
using namespace std;
int sum = 0;
void Initialization()
{
for (int i = 0; i < 5; i++)
{
sum += i;
}
}
void main()
{
#pragma omp parallel
{
Initialization();
#pragma omp barrier
printf("i=%d, thread_id=%d
", sum, omp_get_thread_num());
}
system("pause");
}输出:
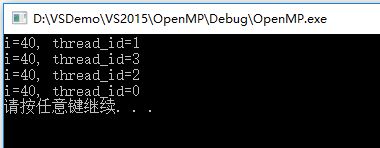
如果没有添加barrier,由于不同的线程可能同时访问sum变量,存在数据竞争问题,导致输出的sum结果值不确定,其中一次输出为:
事件同步之ordered顺序制导
在循环代码中某些代码的执行需要按规定的顺序执行,比如在一个循环中,一部分的工作可以并行执行,而特定的部分需要按照串行的工作流程依次执行。
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel for ordered
for (int i = 0; i < 5; i++)
{
#pragma omp ordered
printf("i=%d, thread_id=%d
", i, omp_get_thread_num());
}
system("pause");
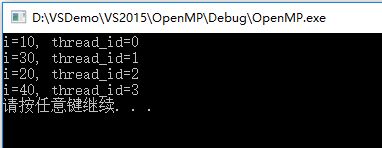
}输出:
输出是按照i从小到达的次序依次执行的,如果不加ordered,其中一次输出为:
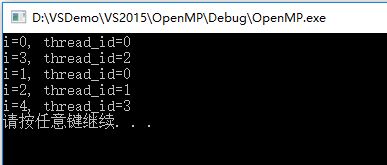
事件同步之master主线程执行
master制导指令用于指定一个代码块是交由主线程执行,这个代码块虽然位于parallel的并行域中,但是并不会被多个线程执行。
#include<iostream>
#include"omp.h"
using namespace std;
void main()
{
#pragma omp parallel
{
#pragma omp master
for (int i = 0; i<5; i++)
{
printf("i=%d, thread_id=%d
", i, omp_get_thread_num());
}
}
system("pause");
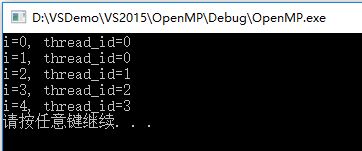
}输出:
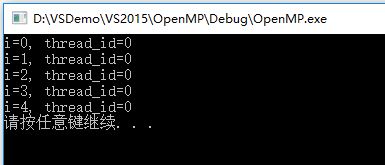
只有线程0,即主线程执行了该语句,如果不加master指令,其中一次输出为: