AlexNet包含5个卷积层和3个全连接层,模型示意图:

精简版结构:
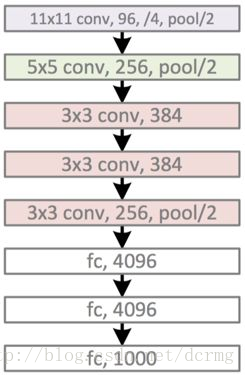
conv1阶段
输入数据:227×227×3
卷积核:11×11×3;步长:4;数量(也就是输出个数):96卷积后数据:55×55×96 (原图N×N,卷积核大小n×n,卷积步长大于1为k,输出维度是(N-n)/k+1)
relu1后的数据:55×55×96
Max pool1的核:3×3,步长:2
Max pool1后的数据:27×27×96
norm1:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:27×27×96
AlexNet采用了Relu激活函数,取代了之前经常使用的S函数和T函数,Relu函数也很简单:
ReLU(x) = max(x,0)
AlexNet另一个创新是LRN(Local Response Normalization) 局部响应归一化,LRN模拟神经生物学上一个叫做 侧抑制(lateral inhibitio)的功能,侧抑制指的是被激活的神经元会抑制相邻的神经元。LRN局部响应归一化借鉴侧抑制的思想实现局部抑制,使得响应比较大的值相对更大,提高了模型的泛化能力。
LRN只对数据相邻区域做归一化处理,不改变数据的大小和维度。
LRN概念是在AlexNet模型中首次提出,在GoogLenet中也有应用,但是LRN的实际作用存在争议,如在2015年Very Deep Convolutional Networks for Large-Scale Image Recognition 论文中指出LRN基本没什么用。
conv2阶段
输入数据:27×27×96
卷积核:5×5;步长:1;数量(也就是输出个数):256卷积后数据:27×27×256 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu2后的数据:27×27×256
Max pool2的核:3×3,步长:2
Max pool2后的数据:13×13×256 ((27-3)/2+1=13 )
norm2:local_size=5 (LRN(Local Response Normalization) 局部响应归一化)
最后的输出:13×13×256
在AlexNet的conv2中使用了same padding,保持了卷积后图像的宽高不缩小。
conv3阶段
输入数据:13×13×256
卷积核:3×3;步长:1;数量(也就是输出个数):384卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu3后的数据:13×13×384
最后的输出:13×13×384
conv3层没有Max pool层和norm层
conv4阶段
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):384卷积后数据:13×13×384 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu4后的数据:13×13×384
最后的输出:13×13×384
conv4层也没有Max pool层和norm层
conv5阶段
输入数据:13×13×384
卷积核:3×3;步长:1;数量(也就是输出个数):256卷积后数据:13×13×256 (做了Same padding(相同补白),使得卷积后图像大小不变。)
relu5后的数据:13×13×256
Max pool5的核:3×3,步长:2
Max pool2后的数据:6×6×256 ((13-3)/2+1=6 )
最后的输出:6×6×256
conv5层有Max pool,没有norm层
fc6阶段
输入数据:6×6×256
全连接输出:4096×1relu6后的数据:4096×1
drop out6后数据:4096×1
最后的输出:4096×1
AlexNet在fc6全连接层引入了drop out的功能。dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率(一般是50%,这种情况下随机生成的网络结构最多)将其暂时从网络中丢弃(保留其权值),不再对前向和反向传输的数据响应。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而相当于每一个mini-batch都在训练不同的网络,drop out可以有效防止模型过拟合,让网络泛化能力更强,同时由于减少了网络复杂度,加快了运算速度。还有一种观点认为drop out有效的原因是对样本增加来噪声,变相增加了训练样本。
fc7阶段
输入数据:4096×1
全连接输出:4096×1relu7后的数据:4096×1
drop out7后数据:4096×1
最后的输出:4096×1
fc8阶段
输入数据:4096×1
全连接输出:1000
fc8输出一千种分类的概率。
AlexNet与在其之前的神经网络相比改进:
1. 数据增广(Data Augmentation增强)
常用的数据增强的方法有 水平翻转、随机裁剪、平移变换、颜色、光照、对比度变换
有效防止过拟合。
用ReLU代替了传统的S或者T激活函数。
参考了生物学上神经网络的侧抑制的功能,做了临近数据归一化,提高来模型的泛化能力,这一功能的作用有争议。
重叠池化减少了系统的过拟合,减少了top-5和top-1错误率的0.4%和0.3%。
6. 多GPU并行训练
AlexNet将网络分成了上下两部分,两部分的结构完全一致,这两部分由两块不同的GPU来训练,提高了训练速度。AlexNet大约有6000万个参数。