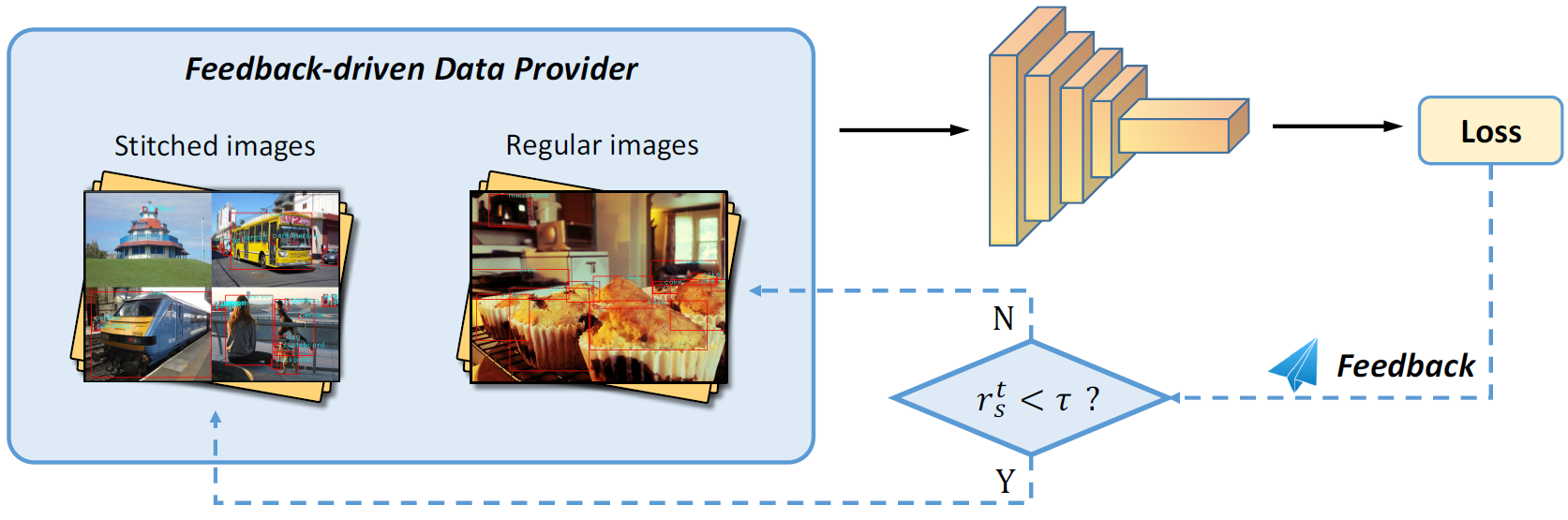
现有的目标检测器对小目标的检测效果不好,针对这种情况,作者提出了Feedback-driven Data Provider,根据训练过程中小对象对损失值的的贡献率,提供小对象训练数据的方法.Stitcher就是把多张图片(一般是4张)缩小后拼接在一起,从而产生更多小对象.
作者以Faster RCNN为例,统计了迭代中小目标对损失值的贡献率,发现在Baseline超过50%的迭代中,小目标对损失值的贡献率低于10%,再使用Stitcher以后,损失值的分布得到了均衡.

作者研究了MS COCO数据集上各种目标所占的比例,以及含有各种目标的图片的比例,发现虽然小目标占了所有目标的41.4%,但是只有52.3%的图片包含小目标,低于中目标的70.7%和大目标的83.0%.

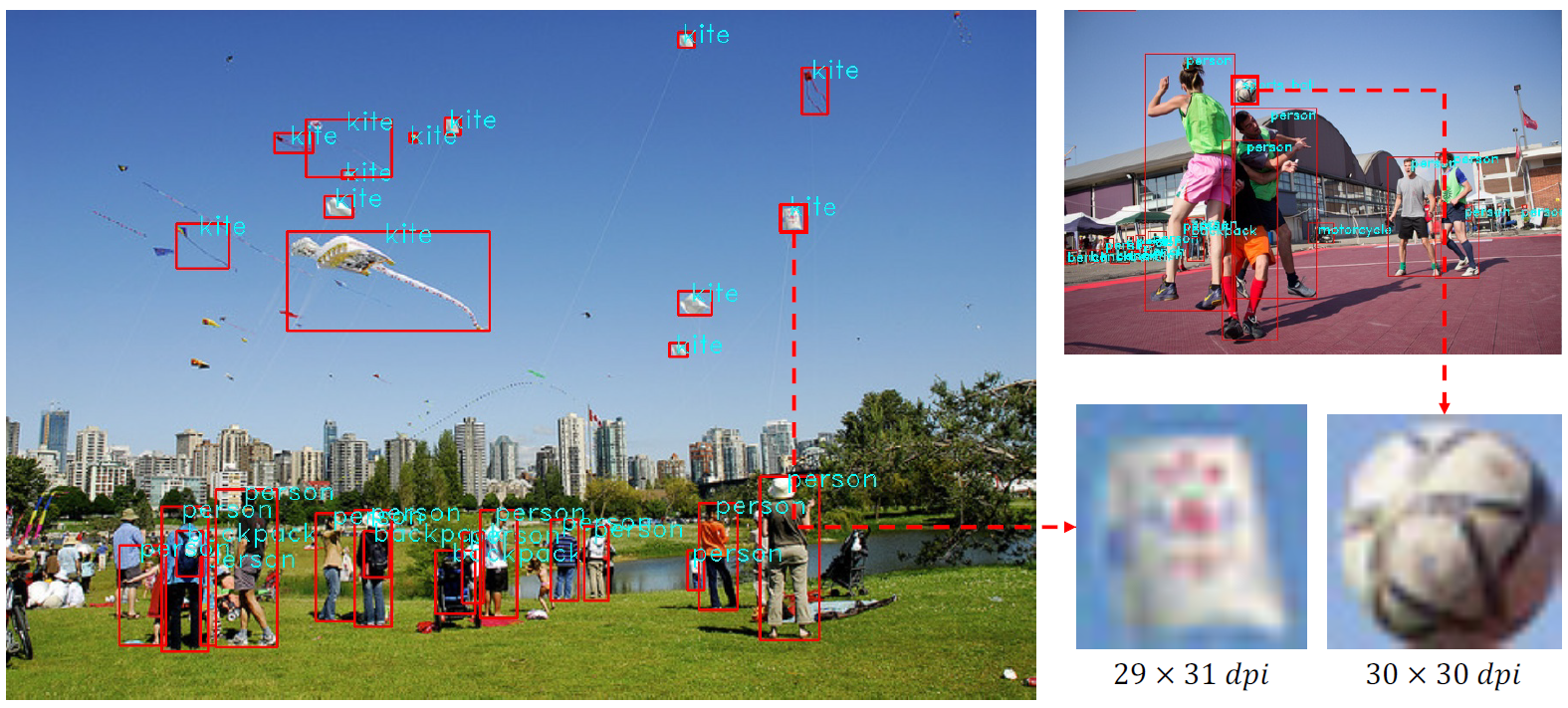
为了解决包含小目标的图片过少的问题,作者提出了将4张图resize到以前的1/4,再拼接起来构成1张图,从而产生更多的小目标,并且通过resize新产生的小目标更加清晰.
作者对比了常规图像和缝合图像,(a)是常规图像,tensor的shape是(n,c,h,w,),b是缝合图像,(b)是空间缝合,即将4张图缩小1/4后组成1张新的图,shape仍然是(n,c,h,w,),(c)是batch维度的缝合,即面积缩小为1/4,图片数量是以前的4倍,shape是(4n,c,h/2,w/2).
算法流程如下图所示,如果第t次迭代的损失值中,小目标的贡献率低于阈值,则第t+1次迭代采用Stitcher,否则仍然采用常规图片.
如何判断一个目标是否是小目标?严格的说,一个目标的面积要使用分割才能获得,然而在目标检测中,一般就采用box的面积作为目标的面积,小目标所占的比例rst用下面3个公式计算:
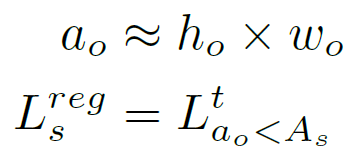
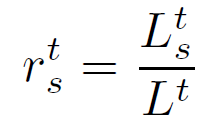
其中a0,h0,w0分别是目标的面积,长和宽,As是面积的阈值(一般为1024).
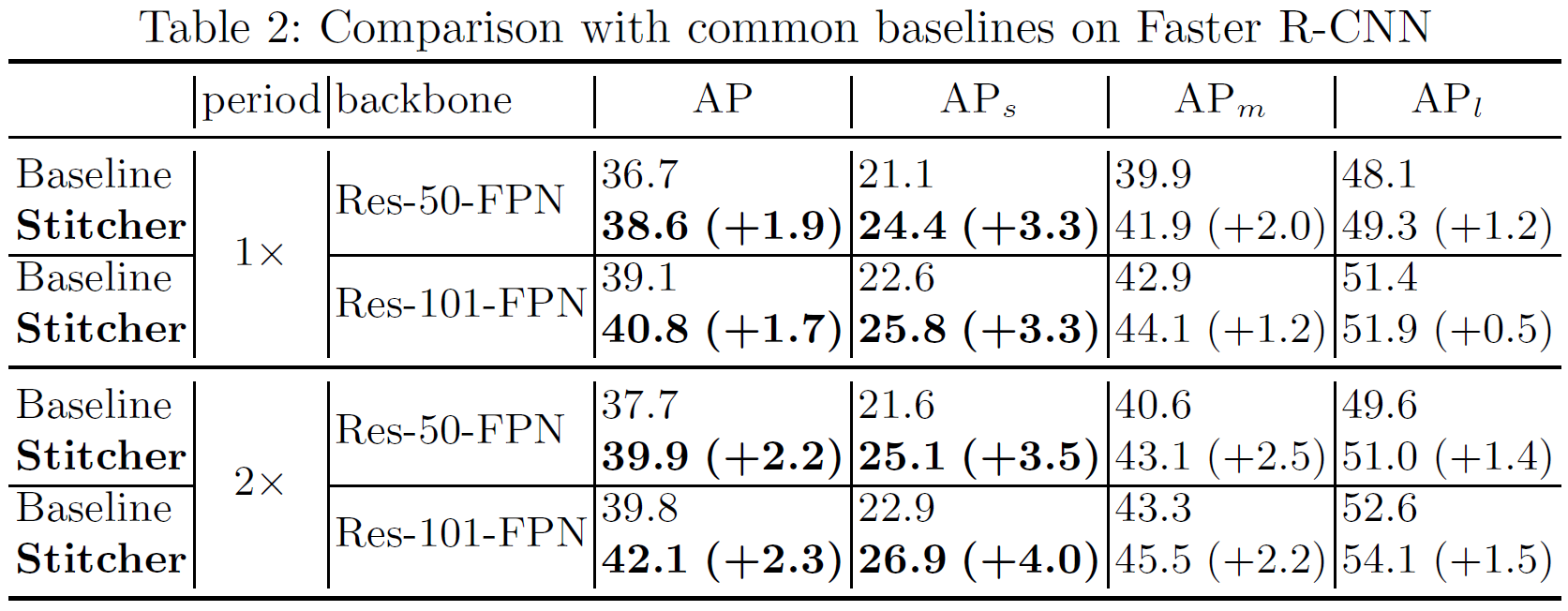
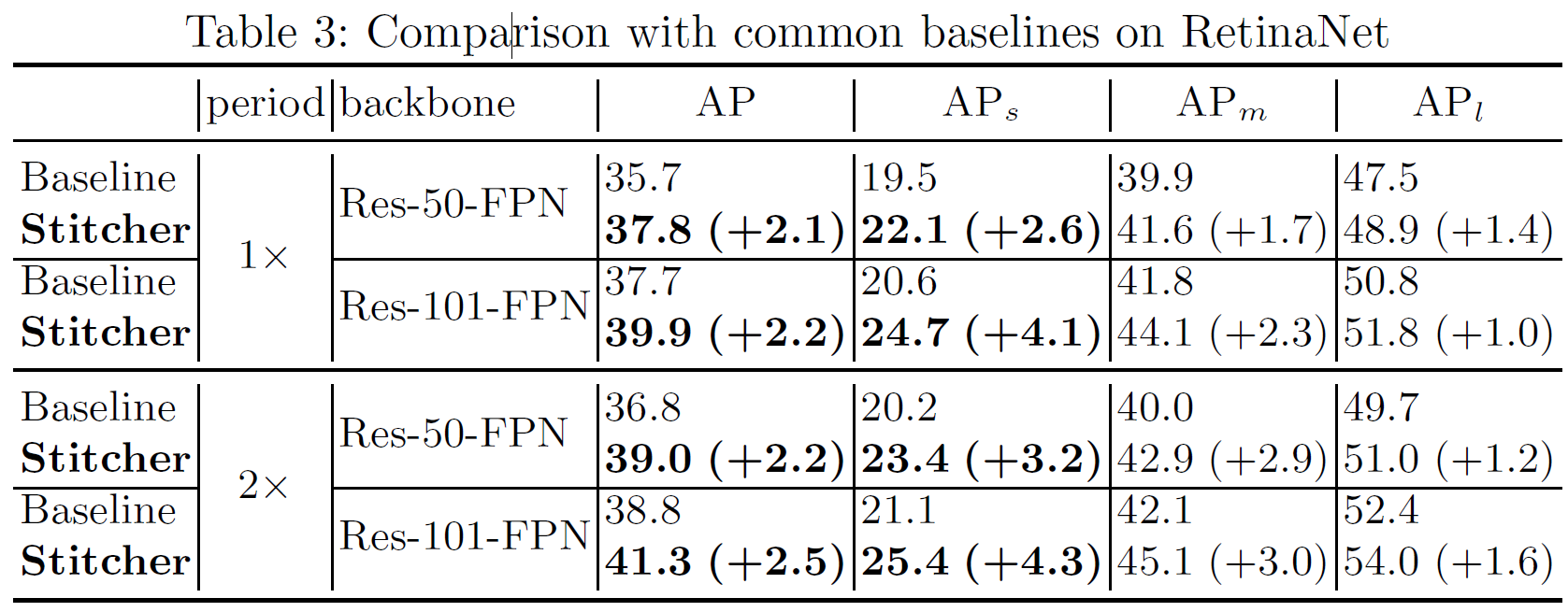
在Faster RCNN和RetinaNet中进行了实验,结果如下面的表所示,mAP提高了0.5~3个百分点.