[TOC]
rabbitmq 学习
实际项目中队列项目应用
- 应用解耦
项目中的应用:登录注册时候,使用队列进行解耦
2.流量削峰
QPS:每秒访问的次数
DAU:日活跃用户数
MAU:月活跃用户数
总用户数
(1).使用动态扩容,抗住并发请求流量
(2).秒杀活动,抢票活动,微博星轨
2.队列的产品
rabbitmq rocketmq kafaka
rabbitmq的使用
安装:
先opt (erland)下载,安装 再rabbitmq 下载,安装
切换到指定的安装目录下,cmd命令下,启动服务
rabbitmq-server
查看消息队列中的存在的信息
rabbitmqctl list_queues
基本使用
- 生产者
#生成者
import pika
#申请链接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#申请管道
channel = connection.channel()
#申请队列 名为test
channel.queue_declare(queue='test')
#发送到队列 exchange路由 队列的名字 test body 消息
channel.basic_publish(exchange='', routing_key='test', body='Hello World!')
print(" [x] Sent 'Hello World!'")
#关闭连接
connection.close()
- 消费者
import pika
#申请链接
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
#申请管道
channel = connection.channel()
#申请队列 名为test
channel.queue_declare(queue='test')
#处理消息队列取出消息的信息
def callback(ch,method,properties,body):
print(" [x] Received %r" % body)
#开始消费,队列中信息
channel.basic_consume(queue='test',on_message_callback = callback,auto_ack=True)
#auto_ack = True 不管消息是否被接受
print(' [*] Waiting for messages. To exit press CTRL+C')
#开始工作,阻塞的
channel.start_consuming()
如何保证rabbitmq数据不丢失?
- 在队列里设置
durable = True代表队列持久化
channel.queue_declare(queue = 'test',durable=True)
注意:队列必须在第一次声明的时候,就必须要持久化,途中设置回报错
- 在生产者端,设置
channel.basic_publish(exchange='mydirect',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
)
)
3.在消费者端
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(10)
print(" [x] Done")
print("method.delivery_tag",method.delivery_tag)
ch.basic_ack(delivery_tag=method.delivery_tag)
channel.basic_consume(queue='test',on_message_callback = callback,auto_ack=True)
exchange的三种类型
Exchange分发消息时根据类型的不同分发策略有区别,目前共四种类型:direct(组播),fanout(广播),topics(规则波),headers。headers比配消息的header头部字节,而不是路由键,此外headers交换器和direct交换器完全一致,但是性能差很多,目前几乎用不到。
fanout(广播):
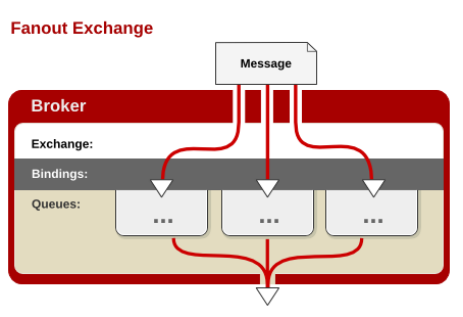
每个发到 fanout 类型交换器的消息都会分到所有绑定的队列上去。fanout 交换器不处理路由键,只是简单的将队列绑定到交换器上,每个发送到交换器的消息都会被转发到与该交换器绑定的所有队列上。很像子网广播,每台子网内的主机都获得了一份复制的消息。fanout 类型转发消息是最快的。
生产者
import pika import sys #申请链接 connection = pika.BlockingConnection(pika.ConnectionParameters('localhost')) #申请管道 channel = connection.channel() #声明路由 路由名 logs 路由类型 fanout channel.exchange_declare(exchange='logs', exchange_type='fanout') #命令行模式下,接受参数 message = ' '.join(sys.argv[1:]) or "info: Hello World!" #开始发送消息 通过logs路由 队列 所有队列 body 消息 channel.basic_publish(exchange='logs', routing_key='', body=message) print(" [x] Sent %r" % message) connection.close()
消费者
import pika connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() #声明路由 channel.exchange_declare(exchange='logs', exchange_type='fanout') #声明管道 所有队列,但是名字唯一 result = channel.queue_declare('', exclusive=True)#exclusive 排他的唯一的 #管道没有声明名字,但是需要绑定队列 queue_name = result.method.queue #队列绑定, 路由绑定 队列绑定 channel.queue_bind(exchange='logs', queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') #回调函数 def callback(ch, method, properties, body): print(" [x] %r" % body) #消费函数 channel.basic_consume( queue=queue_name, on_message_callback=callback, auto_ack=True) #开始消费 channel.start_consuming()
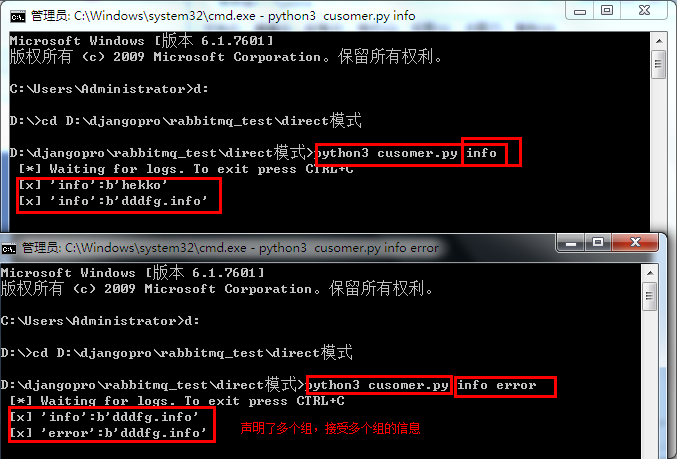
direct(组播)
生产者
import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() #声明路由 路由名 direct_logs 路由类型:direct 组播 channel.exchange_declare(exchange='direct_logs', exchange_type='direct') #输入第一个参数 是 路由的管道 severity = sys.argv[1] if len(sys.argv) > 1 else 'info' #输入的第二个参数数发送的消息 message = ' '.join(sys.argv[2:]) or 'Hello World!' #路由的关键字 channel.basic_publish( exchange='direct_logs', routing_key=severity, body=message) print(" [x] Sent %r:%r" % (severity, message)) connection.close()
消费者:
import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='direct_logs', exchange_type='direct') result = channel.queue_declare('', exclusive=True) queue_name = result.method.queue #可以接受多个组的信息 severities = sys.argv[1:] #没有组名,提示信息,退出 if not severities: sys.stderr.write("Usage: %s [info] [warning] [error] " % sys.argv[0]) sys.exit(1) #绑定组 for severity in severities: channel.queue_bind( exchange='direct_logs', queue=queue_name, routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume( queue=queue_name, on_message_callback=callback, auto_ack=True) channel.start_consuming()
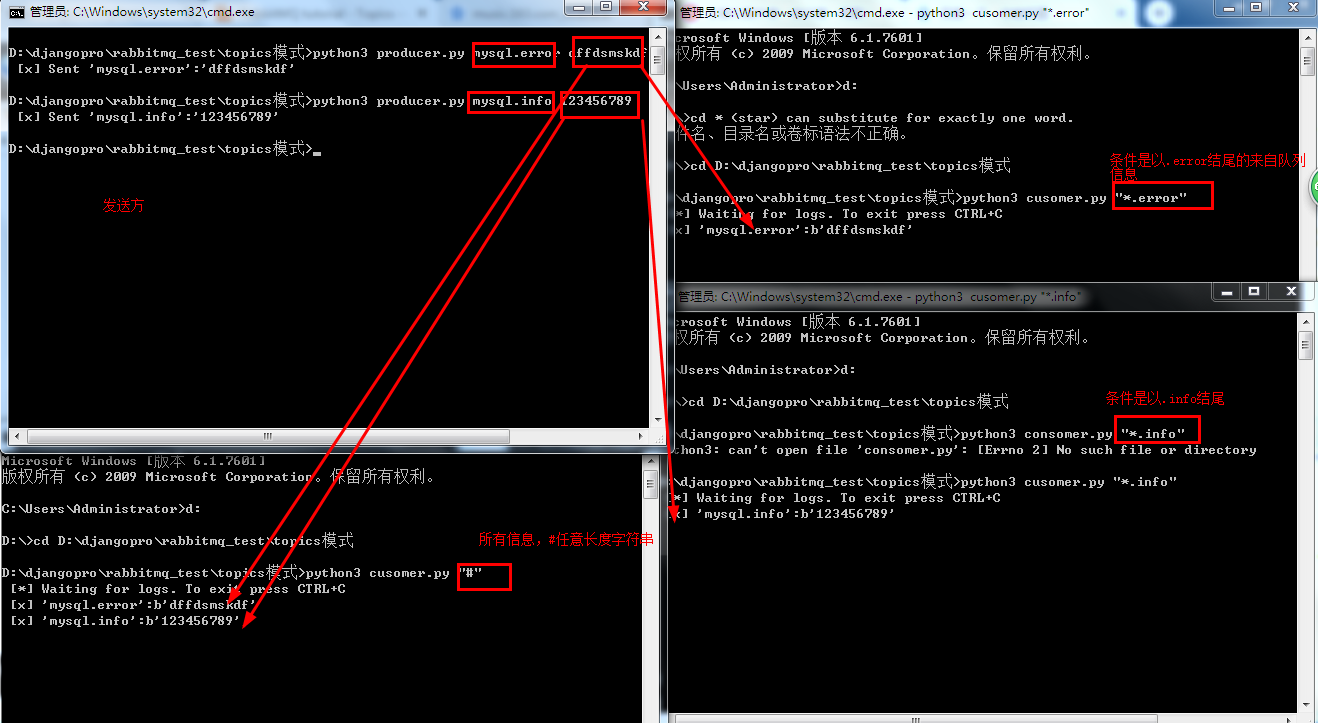
topic(规则波)
规则
-
* (star) can substitute for exactly one word.
*表示一个以及以上的字
-
# (hash) can substitute for zero or more words.
#表示0个或更多的字
生产者
import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic') routing_key = sys.argv[1] if len(sys.argv) > 2 else 'anonymous.info' message = ' '.join(sys.argv[2:]) or 'Hello World!' channel.basic_publish( exchange='topic_logs', routing_key=routing_key, body=message) print(" [x] Sent %r:%r" % (routing_key, message)) connection.close()
消费者
import pika import sys connection = pika.BlockingConnection( pika.ConnectionParameters(host='localhost')) channel = connection.channel() channel.exchange_declare(exchange='topic_logs', exchange_type='topic') result = channel.queue_declare('', exclusive=True) queue_name = result.method.queue binding_keys = sys.argv[1:] if not binding_keys: sys.stderr.write("Usage: %s [binding_key]... " % sys.argv[0]) sys.exit(1) for binding_key in binding_keys: channel.queue_bind( exchange='topic_logs', queue=queue_name, routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body): print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume( queue=queue_name, on_message_callback=callback, auto_ack=True) channel.start_consuming()