第一周学习总结
总结了近期学到的爬虫知识与echarts调用学习,每天的代码时间在2俩小时以上。
近期还会总结一下spark'得学习记录。
三、实验内容和要求
1.Spark SQL 基本操作
将下列 JSON 格式数据复制到 Linux 系统中,并保存命名为 employee.json。
{ "id":1 , "name":" Ella" , "age":36 }
{ "id":2, "name":"Bob","age":29 }
{ "id":3 , "name":"Jack","age":29 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":4 , "name":"Jim","age":28 }
{ "id":5 , "name":"Damon" }
{ "id":5 , "name":"Damon" }
为 employee.json 创建 DataFrame,并写出 Scala 语句完成下列操作:
(1) 查询所有数据;
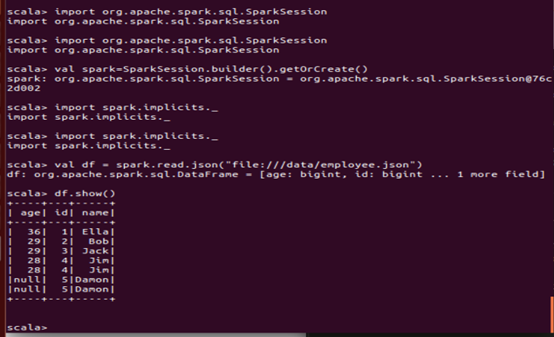
(2) 查询所有数据,并去除重复的数据;
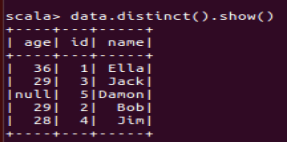
(3) 查询所有数据,打印时去除 id 字段;
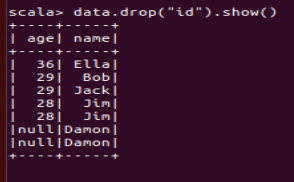
(4) 筛选出 age>30 的记录;
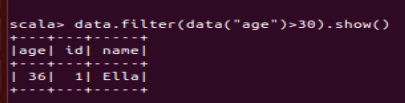
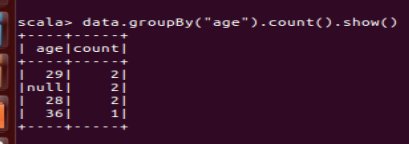
(5) 将数据按 age 分组;
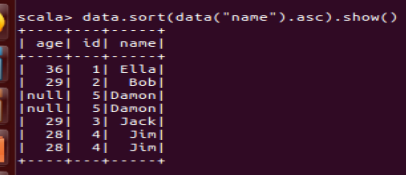
(6) 将数据按 name 升序排列;
(7) 取出前 3 行数据;

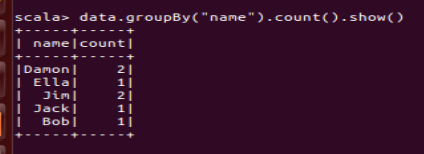
(8) 查询所有记录的 name 列,并为其取别名为 username;

(9) 查询年龄 age 的平均值; 20

(10) 查询年龄 age 的最小值。

下面的问题还未解决,总是报错,在网上有一些解法,但我还没做。
2.编程实现将 RDD 转换为 DataFrame
源文件内容如下(包含 id,name,age):
1,Ella,36
2,Bob,29
3,Jack,29
请将数据复制保存到 Linux 系统中,命名为 employee.txt,实现从 RDD 转换得到 DataFrame,并按“id:1,name:Ella,age:36”的格式打印出 DataFrame 的所有数据。请写出程序代码。
3. 编程实现利用 DataFrame 读写 MySQL 的数据
(1)在 MySQL 数据库中新建数据库 sparktest,再创建表 employee,包含如表 6-2 所示的 两行数据。
(2)配置 Spark 通过 JDBC 连接数据库 MySQL,编程实现利用 DataFrame 插入如表 6-3 所 示的两行数据到 MySQL 中,最后打印出 age 的最大值和 age 的总和。