Pre-trained models
| Model name | LFW accuracy | Training dataset | Architecture |
|---|---|---|---|
| 20180408-102900 | 0.9905 | CASIA-WebFace | Inception ResNet v1 |
| 20180402-114759 | 0.9965 | VGGFace2 | Inception ResNet v1 |
| Model name | LFW accuracy | Training dataset | Architecture |
|---|---|---|---|
| 20170511-185253 | 0.987 | CASIA-WebFace | Inception ResNet v1 |
| 20170512-110547 | 0.992 | MS-Celeb-1M | Inception ResNet v1 |
模型下载链接:https://pan.baidu.com/s/1aiSq7wGpdHIe6MUKPnXgrA 密码:4dcn
20170512-110547(MS-Celeb-1M数据集训练的模型文件,微软人脸识别数据库,名人榜选择前100万名人,搜索引擎采集每个名人100张人脸图片。预训练模型准确率0.993+-0.004)
Ram内存要求
| Neural Network Model | Task | Ram |
|---|---|---|
| MTCNN | Facenet#align() | 100MB |
| Facenet | Facenet#embedding() | 2GB |
Inception ResNet v1
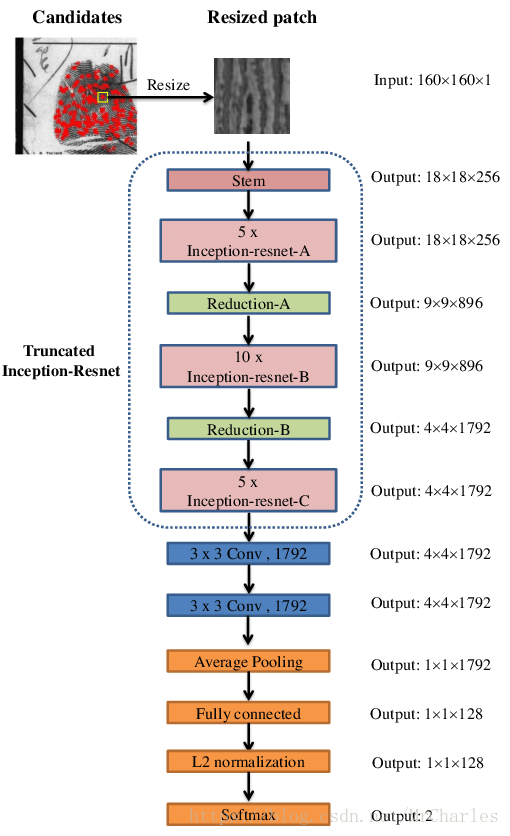
人脸识别数据库
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| CASIA-WebFace | 10k+人,约500K张图片 | 非限制场景 | 链接 |
| FaceScrub | 530人,约100k张图片 | 非限制场景 | 链接 |
| YouTube Face | 1,595个人 3,425段视频 | 非限制场景、视频 | 链接 |
| LFW | 5k+人脸,超过10K张图片 | 标准的人脸识别数据集 | 链接 |
| MultiPIE | 337个人的不同姿态、表情、光照的人脸图像,共750k+人脸图像 | 限制场景人脸识别 | 链接 需购买 |
| MegaFace | 690k不同的人的1000k人脸图像 | 新的人脸识别评测集合 | 链接 |
| IJB-A | 人脸识别,人脸检测 | 链接 | |
| CAS-PEAL | 1040个人的30k+张人脸图像,主要包含姿态、表情、光照变化 | 限制场景下人脸识别 | 链接 |
| Pubfig | 200个人的58k+人脸图像 | 非限制场景下的人脸识别 |
VGG2:
-- Total number of images : 3.31 Million.
-- Number of identities : 9131 (train: 8631, test: 500)
-- Number of male identities : 5452
-- Number of images per identity : 87/362.6/843 (min/avg/max)
-- Number of pose templates : list of pose template for 368 subjects (2 front templates, 2 three-quarter templates and 2 profile templates, each template containing 5 images)
-- Number of age templates : list of age template for 100 subjects (2 young templates and 2 mature templates, each template containing 5 images)
人脸检测
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| FDDB | 2845张图片中的5171张脸 | 标准人脸检测评测集 | 链接 |
| IJB-A | 人脸识别,人脸检测 | 链接 | |
| Caltech10k Web Faces | 10k+人脸,提供双眼和嘴巴的坐标位置 | 人脸点检测 | 链接 |
人脸表情
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| CK+ | 137个人的不同人脸表情视频帧 | 正面人脸表情识别 | 链接 |
人脸年龄
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| IMDB-WIKI | 包含:IMDb中20k+个名人的460k+张图片 和维基百科62k+张图片, 总共: 523k+张图片 | 名人年龄、性别 | 链接 |
| Adience | 包含2k+个人的26k+张人脸图像 | 人脸性别,人脸年龄段(8组) | 链接 |
| CACD2000 | 2k名人160k张人脸图片 | 人脸年龄 | 链接 |
人脸性别
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| IMDB-WIKI | 包含:IMDb中20k+个名人的460k+张图片 和维基百科62k+张图片, 总共: 523k+张图片 | 名人年龄、性别 | 链接 |
| Adience | 包含2k+个人的26k+张人脸图像 | 人脸性别,人脸年龄段(8组) | 链接 |
人脸关键点检测
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| 数据库 | 描述 | 用途 | 获取方法 |
人脸其它
| 数据库 | 描述 | 用途 | 获取方法 |
|---|---|---|---|
| CeleBrayA | 200k张人脸图像40多种人脸属性 | 人脸属性识别 | 获取方法 |
前提条件:已安装并配置好Tensorflow的运行环境。
第一步:准备facenet程序:
一、下载FaceNet源码。
下载地址:facenet源码
二、精简代码。作者在代码里实现了很多功能,但是对于初学者来说,很多代码是没有必要的,反倒找不到学习这个程序的入口。建议先精简一下代码,便于读懂代码:新建一个文件夹,取名:facenet,把源码中的src文件夹直接拷贝过来。
注:便于大家能够看懂代码,以上两步我已经完成,同时,自己运行程序之后,还对里边的代码做了详细的注释,如果想先了解facenet的源码,强烈建议下载这个,下载地址:facenet精简版
当然,大家别忘了顺手点个星哦~~~
第二步:下载预训练模型。
模型下载链接:https://pan.baidu.com/s/1aiSq7wGpdHIe6MUKPnXgrA 密码:4dcn
下载完成后,把预训练模型的文件夹拷贝在刚才的文件夹里。用pycharm打开这个工程文件如图:

第三步:运行人脸比对程序(compare.py)。
facenet可以直接比对两个人脸经过它的网络映射之后的欧氏距离。
-1、在compare.py所在目录下放入要比对的文件1.png和2.png。
-2、运行compare.py文件,但是会报错如下:
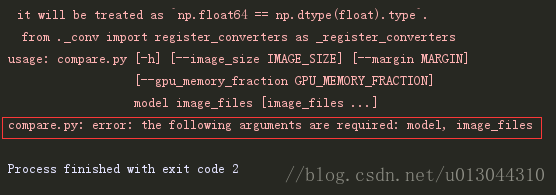
这是因为这个程序需要输入参数,在上方的工具栏里选择Run>EditConfigurations ,在Parameters中配置参数:20170512-110547 1.png 2.png。再次运行程序

可以看到,程序会算出这两个图片的差值矩阵

第四步:图片预处理——运行人脸对齐程序(alignalign_dataset_mtcnn.py)。
我们可以下载LFW数据集用来测试这个程序,也为后边的训练函数做好数据准备。
下载链接:http://vis-www.cs.umass.edu/lfw/。下载后解压在data文件夹中。
因为程序中神经网络使用的是谷歌的“inception resnet v1”网络模型,这个模型的输入时160*160的图像,而我们下载的LFW数据集是250*250限像素的图像,所以需要进行图片的预处理。
在运行时需要输入的参数:
input_dir:输入图像的文件夹(E:facenetdatalfw E:facenetdatalfw)
output_dir:输出图像的文件夹(E:facenetdatalfw E:facenetdatalfw_160)
指定裁剪后图片的大小:--image_size 160 --margin 32 --random_order(如果不指定,默认的裁剪结果是182*182像素的)
比如我的是:E:facenetdatalfw E:facenetdatalfw_160 --image_size 160 --margin 32 --random_order
如果在pycharm中运行,按照同样的方法配置以上参数如下:

第五步:运行训练程序:(train_tripletloss.py)。
前边已经下载并处理好了LFW的数据集,现在,可以进行训练了。
运行之前,要在train_tripletloss.py中把加载数据的路径改成自己的数据集所在路径,如下图:

注:train_tripletloss.py和train_softmax.py的区别:这是作者对论文做出的一个延伸,除了使用facenet里提到的train_tripletloss三元组损失函数来训练,还实现了用softmax的训练方法来训练。当然,在样本量很小的情况下,用softmax训练会更容易收敛。但是,当训练集中包含大量的不同个体(超过10万)时,最后一层的softmax输出数量就会变得非常大,但是使用train_tripletloss的训练仍然可以正常工作。
最后,附上原来的文件中各py文件的作用(持续更新):
一、主要函数
align/ :用于人脸检测与人脸对齐的神经网络
facenet :用于人脸映射的神经网络
util/plot_learning_curves.m:这是用来在训练softmax模型的时候用matlab显示训练过程的程序
二、facenet/contributed/相关函数:
1、基于mtcnn与facenet的人脸聚类
代码:facenet/contributed/cluster.py(facenet/contributed/clustering.py实现了相似的功能,只是没有mtcnn进行检测这一步)
主要功能:
① 使用mtcnn进行人脸检测并对齐与裁剪
② 对裁剪的人脸使用facenet进行embedding
③ 对embedding的特征向量使用欧式距离进行聚类
2、基于mtcnn与facenet的人脸识别(输入单张图片判断这人是谁)
代码:facenet/contributed/predict.py
主要功能:
① 使用mtcnn进行人脸检测并对齐与裁剪
② 对裁剪的人脸使用facenet进行embedding
③ 执行predict.py进行人脸识别(需要训练好的svm模型)
3、以numpy数组的形式输出人脸聚类和图像标签
代码:facenet/contributed/export_embeddings.py
主要功能:
① 需要对数据进行对齐与裁剪做为输入数据
② 输出embeddings.npy;labels.npy;label_strings.npy