https://blog.csdn.net/BlueCloudMatrix/article/details/29180095
假设让内核定期对设备进行轮询,以便处理设备,那会做非常多无用功,假设能让设备在须要内核时主动通知内核。会是一个聪明的方式,这便是中断。
在响应一个特定中断时。内核会运行一个函数——中断处理程序。中断处理程序与其它内核函数的差别在于。中断处理程序是被内核调用来响应中断的。而它们运行于我们称之为中断上下文的特殊上下文中。
我们期望让中断处理程序运行得快。并想让它完毕的工作量多,这两个目标相互制约,怎样解决——上下半部机制。
我们把中断处理切为两半。
我们用网卡来解释一下这两半。当网卡接受到数据包时,通知内核,触发中断。所谓的上半部就是,及时读取数据包到内存,防止由于延迟导致丢失,这是非常急迫的工作。
读到内存后。对这些数据的处理不再紧迫,此时内核能够去运行中断前运行的程序,而对网络数据包的处理则交给下半部处理。
我们先来看一下上半部的处理过程。
中断处理程序的注冊与注销
设备驱动程序利用request_irq()注冊中断处理程序,并激活给定的中断线。
int request_irq(unsigned int irq,
irq_handler_t handler,
unsigned long flags,
const char *name,
void *dev)irq表示中断号,handler是指向中断处理程序的指针。
request_irq()成功运行返回0,当返回非0值时,表示有发生错误。中断处理程序不会被注冊。
卸载设备驱动程序时,须要注销对应的中断处理程序。并释放中断线,这时须要调用free_irq——假设在给定的中断线上没有中断处理程序,则注销响应的处理程序。并禁用当中断线。
中断处理机制
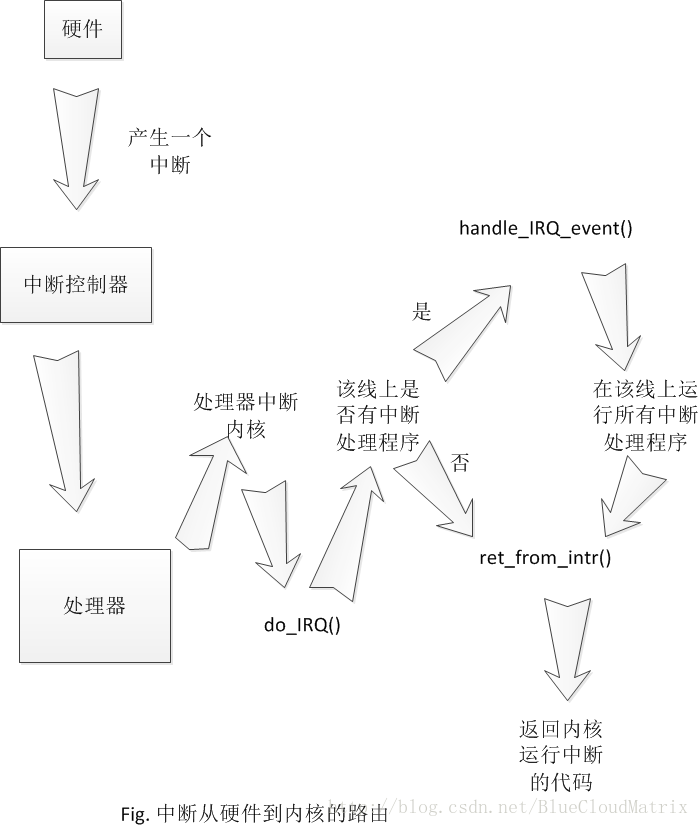
下半部严格来说不属于中断处理程序(由于中断返回后再运行下半部),它是中断处理程序用来缩减自身工作的分担者。
上下半部划分原则
(1)假设一个任务对时间非常敏感,将其放在中断处理程序中运行;
(2)假设一个任务和硬件有关,将其放在中断处理程序中运行。
(3)假设一个任务要保证不被其它中断打断。将其放在中断处理程序中运行;
(4)其它全部任务,考虑放置在下半部运行。
上下半部的意义
上半部简单高速。运行时禁止一些或者全部中断。下半部稍后运行。并且运行期间能够响应全部的中断。
这样的设计能够使系统处于中断屏蔽状态的时间尽可能的短,以此来提高系统的响应能力。
下半部实现机制之软中断
在中断处理程序中触发软中断是最常见的形式。在这样的情况下,中断处理程序运行硬件设备的相关操作。然后触发对应的软中断。最后退出。内核在运行完中断处理程序后,立即就会调用do_softirq()函数,于是软中断開始运行中断处理程序留给它去完毕的剩余任务。
软中断注冊方式例如以下:
open_softirq(NET_TX_SOFTIRQ, net_tx_action);
前面的參数是软中断的索引號,后面的是处理函数。
软中断处理程序运行时,同意响应中断,但它自己不能休眠。
下半部实现机制之tasklet
tasklet是通过软中断实现的。所以它本身也是软中断。
首先声明自己的tasklet,DECLARE_TASKLET(name, func, data),当该tasklet被调度后,给定的函数func会被运行。它的參数由data给出。接下来定义tasklet处理程序void tasklet_handler(unsigned long data),然后開始调度。tasklet由tasklet_schedule()和tasklet_hi_schedule()进行调度。
tasklet_schedule()的运行步骤:
(1)检查tasklet的状态是否为TASKLET_STATE_SCHED。假设是。说明tasklet已经被调度过了,函数立即返回。
(2)调用_tasklet_schedule()。
(3)保存中断状态,然后禁止本地中断。在我们运行tasklet代码时。这么做能够保证当tasklet_schedule()处理这些tasklet时。处理器上的数据不会弄乱。
(4)把须要调度的tasklet加到每一个处理器一个的tasklet_vec链表或tasklet_hi_vec链表的表头上。
(5)唤醒TASKLET_SOFTIRQ或HI_SOFTIRQ软中断,这样在下一次调用do_softirq()时就会运行该tasklet。
(6)恢复中断到原状态并返回。
下半部实现机制之工作队列(work queue)
假设推后运行的任务须要睡眠。那么就选择工作队列,假设不须要睡眠,那么就选择软中断或tasklet。
工作队列能运行在进程上下文。它将工作委托给一个内核线程。
我们用结构体workqueue_struct表示工作者线程,工作者线程是用内核线程实现的。而工作者线程是怎样运行被推后的工作——有这样一个链表,它由结构体work_struct组成,而这个work_struct则描写叙述了一个工作。一旦这个工作被运行完,对应的work_struct对象就从链表上移去,当链表上不再有对象时。工作者线程就会继续休眠。
这些逻辑是通过函数worker_thread()实现的:
(1)线程将自己设置为休眠状态。并把自己增加到等待队列中。
(2)假设工作链表是空的,线程调用schedule()函数进入休眠状态。
(3)假设链表中有对象,线程不会休眠。
相反,它会脱离等待队列。
(4)假设链表非空,调用run_workqueue()运行被推后的工作。
另外。cpu_workqueue_struct表示一个工作者线程,而workqueue_struct表示一类工作者线程。
创建工作者线程,DECLARE_WORK(name, void (*func) (void *), void *data)或INIT_WORK(struct work_struct *work, void (*func) (void *), void *data),前者是静态创建,后者在运行时通过指针创建。
工作者线程创建了,接下来应该定义它要运行的函数work_handler。
之后就是用schedule_work(&work)来调度工作线程的唤醒与休眠。