版权声明: https://blog.csdn.net/zdp072/article/details/25338221
一、题外篇
今天非常悲催啊。给用户数据做datapatch的时候,每一个月的数据多导入了一份。瞬间惊出一身冷汗... 这但是产品环境,要是被老板知道了可就死定了,赶紧去掉反复的记录,同一时候写下以下的文章以备后用。
二、准备篇
1. 先创建一张学生表student:
create table student(
id varchar(10) not null,
name varchar(10) not null,
age number not null
);2. 插入几条数据到表student:
insert into student values('1', 'zhangs', 20);
insert into student values('1', 'zhangs', 20);
insert into student values('2', 'zhangs', 20);
insert into student values('3', 'lisi', 20);
insert into student values('4', 'lisi', 30);
insert into student values('5', 'wangwu', 30);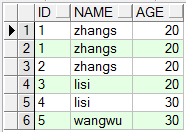
三、处理篇
1. 使用rowid
① 查询:
select *
from student s1
where rowid != (select max(rowid)
from student s2
where s1.id = s2.id
and s1.name = s2.name
and s1.age = s2.age)注: rowid是唯一标志记录物理位置的一个id, 括号里是查询出反复数据中rowid最大的一条.
② 删除:
delete from student s1
where rowid != (select max(rowid)
from student s2
where s1.id = s2.id
and s1.name = s2.name
and s1.age = s2.age)2. 使用 group by 和 having
① 查询:
select id, name, age, count(*)
from student
group by id, name, age
having count(*) > 1;② 删除:
delete from student
where rowid in (select min(rowid)
from student
group by id, name, age
having count(*) > 1)3. 使用distinct
create table stud_temp as select distinct * from student; -- 创建暂时表 stud_temp
truncate table student; -- 清空student表
insert into student select * from stud_temp; -- 将暂时表数据导入student表
drop table stud_temp; -- 删除暂时表注: distinct仅仅适用于对小表处理, 假设是千万级别数据的表, 请使用rowid, 由于它具有唯一性, 效率更高.