本文讲解Lucene中,创建索引、搜索等常用到的类API
搜索操作比索引操作重要的多,因为索引文件只被创建一次,却要被搜索多次。


索引过程的核心类:
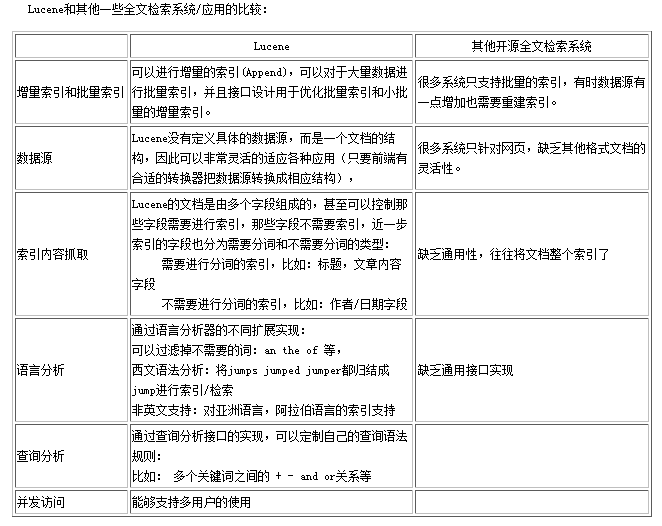
执行简单的索引过程需要如下几个类:IndexWriter, Directory, Analyzer, Document, Field

一、IndexWriter类
IndexWriter(写索引)是索引过程的核心组件。
负责创建新索引或者打开已有索引,以及向索引中添加、删除或更新被索引文档的信息。
它为你提供对索引文件的写入操作,但不能用于读取或搜索索引。IndexWriter需要开辟一定空间来存储索引,该功能可以由Directory完成。
二、Directory类
描述了Lucene索引的存放位置。是一个抽象类,它的子类负责具体指定索引的存储位置。
FSDirectory.open方法来获取真实文件在文件系统的存储路径,然后将它们依次传递给IndexWriter类构造方法。
Lucene包含大量有趣的Directory实现。IndexWriter不能直接索引文本,这需要先由Analyzer将文本分割成独立的单词才行。
三、Analyzer类
文件文件在被索引之前,需要经过Analyzer(分析器)处理。
Analyzer是由IndexWriter的构造方法来指定的,它负责从被索引文本文件中提取语汇单元,并提出剩下的无用信息。
如果被索引内容不是纯文本文件,那就需要先将其转换为文本文档。(Tika从常用的多媒体格式文件中提取文本内容)
Analyzer是一个抽象类,而Lucene提供了几个类实现它。这些类有的用于跳过停用词(stop words)(指一些常用的且不能帮助区分文档的词,如a, an,the, in,on等);有的用于把词汇单元转成小写形式,以使搜索过程能忽略大小写差别;除此之外,还有一些其他类。
Analyzer是Lucene很重要的一部分,它的用途远远不止过滤输入这一项。
分析器的分析对象为文档,该文档包含一些分离的能被索引的域。
四、Document
Document(文档)对象代表一些域(Field)的集合。可以将Document对象理解为虚拟文档——比如Web页面、E-mail信息或者文本文件——然后可以从中取回大量数据。
文档的域代表文档或者和文档相关的一些元数据。
文档的数据源(比如数据库记录、Word文档、书中的某章节等)对呀Lucene来说是无关紧要的。
Lucene只处理从二进制文档中提取的以Field实例形式出现的文本。
上述元数据(如作者、标题、主题和修改日期等)都作为文档的不同域单独存储并被索引。
Document对象的结构比较简单,为一个包含多个Field对象的容器;Field是指包含能被索引的文本内容的类。
五、Field类
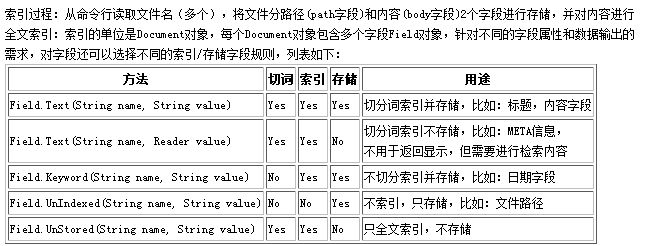
索引中的每个文档都包含一个或多个不同命名的域,这些域包含在Field类中。每个域都有一个域名和对应的域只,以及一组选项来精确控制Lucene索引操作各个域值。
搜索过程的核心类:
IndexSearcher, Term, Query, TermQuery, TopDocs
一、IndexSearcher类
IndexSearcher类用于搜索由IndexWriter类创建的索引:公开了几个搜索方法,它是连接索引的中心环节。
Donate捐赠
如果我的文章帮助了你,可以赞赏我 6.66 元给我支持,让我继续写出更好的内容)


(微信) (支付宝)
微信/支付宝 扫一扫