(涉及内容:面向对象,类的继承)
定义类并创建实例
在Python中,类通过 class 关键字定义。以 Person 为例,定义一个Person类如下:
class Person(object):
pass
按照 Python 的编程习惯,类名以大写字母开头,紧接着是(object),表示该类是从哪个类继承下来的。类的继承将在后面的章节讲解,现在我们只需要简单地从object类继承。
有了Person类的定义,就可以创建出具体的xiaoming、xiaohong等实例。创建实例使用 类名+(),类似函数调用的形式创建:
xiaoming = Person() xiaohong = Person()
创建实例属性
虽然可以通过Person类创建出xiaoming、xiaohong等实例,但是这些实例看上除了地址不同外,没有什么其他不同。在现实世界中,区分xiaoming、xiaohong要依靠他们各自的名字、性别、生日等属性。
如何让每个实例拥有各自不同的属性?由于Python是动态语言,对每一个实例,都可以直接给他们的属性赋值,例如,给xiaoming这个实例加上name、gender和birth属性:
xiaoming = Person() xiaoming.name = 'Xiao Ming' xiaoming.gender = 'Male' xiaoming.birth = '1990-1-1'
给xiaohong加上的属性不一定要和xiaoming相同:
xiaohong = Person() xiaohong.name = 'Xiao Hong' xiaohong.school = 'No. 1 High School' xiaohong.grade = 2
实例的属性可以像普通变量一样进行操作:
xiaohong.grade = xiaohong.grade + 1
初始化实例属性
虽然我们可以自由地给一个实例绑定各种属性,但是,现实世界中,一种类型的实例应该拥有相同名字的属性。例如,Person类应该在创建的时候就拥有 name、gender 和 birth 属性,怎么办?
在定义 Person 类时,可以为Person类添加一个特殊的__init__()方法,当创建实例时,__init__()方法被自动调用,我们就能在此为每个实例都统一加上以下属性:
class Person(object):
def __init__(self, name, gender, birth):
self.name = name
self.gender = gender
self.birth = birth
__init__() 方法的第一个参数必须是 self(也可以用别的名字,但建议使用习惯用法),后续参数则可以自由指定,和定义函数没有任何区别。
相应地,创建实例时,就必须要提供除 self 以外的参数:
xiaoming = Person('Xiao Ming', 'Male', '1991-1-1')
xiaohong = Person('Xiao Hong', 'Female', '1992-2-2')
有了__init__()方法,每个Person实例在创建时,都会有 name、gender 和 birth 这3个属性,并且,被赋予不同的属性值,访问属性使用.操作符:
print xiaoming.name # 输出 'Xiao Ming' print xiaohong.birth # 输出 '1992-2-2'
要特别注意的是,初学者定义__init__()方法常常忘记了 self 参数:
>>> class Person(object):
... def __init__(name, gender, birth):
... pass
...
>>> xiaoming = Person('Xiao Ming', 'Male', '1990-1-1')
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: __init__() takes exactly 3 arguments (4 given)
这会导致创建失败或运行不正常,因为第一个参数name被Python解释器传入了实例的引用,从而导致整个方法的调用参数位置全部没有对上。
要定义关键字参数,使用 **kw;
除了可以直接使用self.name = 'xxx'设置一个属性外,还可以通过 setattr(self, 'name', 'xxx') 设置属性。
参考代码:
class Person(object):
def __init__(self, name, gender, birth, **kw):
self.name = name
self.gender = gender
self.birth = birth
for k, v in kw.iteritems():
setattr(self, k, v)
xiaoming = Person('Xiao Ming', 'Male', '1990-1-1', job='Student')
print xiaoming.name
print xiaoming.job
访问限制
我们可以给一个实例绑定很多属性,如果有些属性不希望被外部访问到怎么办?
Python对属性权限的控制是通过属性名来实现的,如果一个属性由双下划线开头(__),该属性就无法被外部访问。看例子:
class Person(object):
def __init__(self, name):
self.name = name
self._title = 'Mr'
self.__job = 'Student'
p = Person('Bob')
print p.name
# => Bob
print p._title
# => Mr
print p.__job
# => Error
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: 'Person' object has no attribute '__job'
可见,只有以双下划线开头的"__job"不能直接被外部访问。
但是,如果一个属性以"__xxx__"的形式定义,那它又可以被外部访问了,以"__xxx__"定义的属性在Python的类中被称为特殊属性,有很多预定义的特殊属性可以使用,通常我们不要把普通属性用"__xxx__"定义。
以单下划线开头的属性"_xxx"虽然也可以被外部访问,但是,按照习惯,他们不应该被外部访问。
创建类属性
类是模板,而实例则是根据类创建的对象。
绑定在一个实例上的属性不会影响其他实例,但是,类本身也是一个对象,如果在类上绑定一个属性,则所有实例都可以访问类的属性,并且,所有实例访问的类属性都是同一个!也就是说,实例属性每个实例各自拥有,互相独立,而类属性有且只有一份。
定义类属性可以直接在 class 中定义:
class Person(object):
address = 'Earth'
def __init__(self, name):
self.name = name
因为类属性是直接绑定在类上的,所以,访问类属性不需要创建实例,就可以直接访问:
print Person.address # => Earth
对一个实例调用类的属性也是可以访问的,所有实例都可以访问到它所属的类的属性:
p1 = Person('Bob')
p2 = Person('Alice')
print p1.address
# => Earth
print p2.address
# => Earth
由于Python是动态语言,类属性也是可以动态添加和修改的:
Person.address = 'China' print p1.address # => 'China' print p2.address # => 'China'
因为类属性只有一份,所以,当Person类的address改变时,所有实例访问到的类属性都改变了。
类属性和实例属性名字冲突怎么办
修改类属性会导致所有实例访问到的类属性全部都受影响,但是,如果在实例变量上修改类属性会发生什么问题呢?
class Person(object):
address = 'Earth'
def __init__(self, name):
self.name = name
p1 = Person('Bob')
p2 = Person('Alice')
print 'Person.address = ' + Person.address
p1.address = 'China'
print 'p1.address = ' + p1.address
print 'Person.address = ' + Person.address
print 'p2.address = ' + p2.address
结果如下:
Person.address = Earth p1.address = China Person.address = Earth p2.address = Earth
我们发现,在设置了 p1.address = 'China' 后,p1访问 address 确实变成了 'China',但是,Person.address和p2.address仍然是'Earch',怎么回事?
原因是 p1.address = 'China'并没有改变 Person 的 address,而是给 p1这个实例绑定了实例属性address ,对p1来说,它有一个实例属性address(值是'China'),而它所属的类Person也有一个类属性address,所以:
访问 p1.address 时,优先查找实例属性,返回'China'。
访问 p2.address 时,p2没有实例属性address,但是有类属性address,因此返回'Earth'。
可见,当实例属性和类属性重名时,实例属性优先级高,它将屏蔽掉对类属性的访问。
当我们把 p1 的 address 实例属性删除后,访问 p1.address 就又返回类属性的值 'Earth'了:
del p1.address print p1.address # => Earth
可见,千万不要在实例上修改类属性,它实际上并没有修改类属性,而是给实例绑定了一个实例属性。
定义实例方法
一个实例的私有属性就是以__开头的属性,无法被外部访问,那这些属性定义有什么用?
虽然私有属性无法从外部访问,但是,从类的内部是可以访问的。除了可以定义实例的属性外,还可以定义实例的方法。
实例的方法就是在类中定义的函数,它的第一个参数永远是 self,指向调用该方法的实例本身,其他参数和一个普通函数是完全一样的:
class Person(object):
def __init__(self, name):
self.__name = name
def get_name(self):
return self.__name
get_name(self) 就是一个实例方法,它的第一个参数是self。__init__(self, name)其实也可看做是一个特殊的实例方法。
调用实例方法必须在实例上调用:
p1 = Person('Bob')
print p1.get_name() # self不需要显式传入# => Bob
在实例方法内部,可以访问所有实例属性,这样,如果外部需要访问私有属性,可以通过方法调用获得,这种数据封装的形式除了能保护内部数据一致性外,还可以简化外部调用的难度。
方法也是属性
我们在 class 中定义的实例方法其实也是属性,它实际上是一个函数对象:
class Person(object):
def __init__(self, name, score):
self.name = name
self.score = score
def get_grade(self):
return 'A'
p1 = Person('Bob', 90)
print p1.get_grade
# => <bound method Person.get_grade of <__main__.Person object at 0x109e58510>>
print p1.get_grade()
# => A
也就是说,p1.get_grade 返回的是一个函数对象,但这个函数是一个绑定到实例的函数,p1.get_grade() 才是方法调用。
因为方法也是一个属性,所以,它也可以动态地添加到实例上,只是需要用 types.MethodType() 把一个函数变为一个方法:
import types
def fn_get_grade(self):
if self.score >= 80:
return 'A'
if self.score >= 60:
return 'B'
return 'C'
class Person(object):
def __init__(self, name, score):
self.name = name
self.score = score
p1 = Person('Bob', 90)
p1.get_grade = types.MethodType(fn_get_grade, p1, Person)
print p1.get_grade()
# => A
p2 = Person('Alice', 65)
print p2.get_grade()
# ERROR: AttributeError: 'Person' object has no attribute 'get_grade'
# 因为p2实例并没有绑定get_grade
给一个实例动态添加方法并不常见,直接在class中定义要更直观。
定义类方法
和属性类似,方法也分实例方法和类方法。
在class中定义的全部是实例方法,实例方法第一个参数 self 是实例本身。
要在class中定义类方法,需要这么写:
class Person(object):
count = 0
@classmethod
def how_many(cls):
return cls.count
def __init__(self, name):
self.name = name
Person.count = Person.count + 1
print Person.how_many()
p1 = Person('Bob')
print Person.how_many()
通过标记一个 @classmethod,该方法将绑定到 Person 类上,而非类的实例。类方法的第一个参数将传入类本身,通常将参数名命名为 cls,上面的 cls.count 实际上相当于 Person.count。
因为是在类上调用,而非实例上调用,因此类方法无法获得任何实例变量,只能获得类的引用。
继承一个类
如果已经定义了Person类,需要定义新的Student和Teacher类时,可以直接从Person类继承:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
定义Student类时,只需要把额外的属性加上,例如score:
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
一定要用 super(Student, self).__init__(name, gender) 去初始化父类,否则,继承自 Person 的 Student 将没有 name 和 gender。
函数super(Student, self)将返回当前类继承的父类,即 Person ,然后调用__init__()方法,注意self参数已在super()中传入,在__init__()中将隐式传递,不需要写出(也不能写)。
判断类型
函数isinstance()可以判断一个变量的类型,既可以用在Python内置的数据类型如str、list、dict,也可以用在我们自定义的类,它们本质上都是数据类型。
假设有如下的 Person、Student 和 Teacher 的定义及继承关系如下:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
class Teacher(Person):
def __init__(self, name, gender, course):
super(Teacher, self).__init__(name, gender)
self.course = course
p = Person('Tim', 'Male')
s = Student('Bob', 'Male', 88)
t = Teacher('Alice', 'Female', 'English')
当我们拿到变量 p、s、t 时,可以使用 isinstance 判断类型:
>>> isinstance(p, Person) True # p是Person类型 >>> isinstance(p, Student) False # p不是Student类型 >>> isinstance(p, Teacher) False # p不是Teacher类型
这说明在继承链上,一个父类的实例不能是子类类型,因为子类比父类多了一些属性和方法。
我们再考察 s :
>>> isinstance(s, Person) True # s是Person类型 >>> isinstance(s, Student) True # s是Student类型 >>> isinstance(s, Teacher) False # s不是Teacher类型
s 是Student类型,不是Teacher类型,这很容易理解。但是,s 也是Person类型,因为Student继承自Person,虽然它比Person多了一些属性和方法,但是,把 s 看成Person的实例也是可以的。
这说明在一条继承链上,一个实例可以看成它本身的类型,也可以看成它父类的类型。
多态
类具有继承关系,并且子类类型可以向上转型看做父类类型,如果我们从 Person 派生出 Student和Teacher ,并都写了一个 whoAmI() 方法:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
def whoAmI(self):
return 'I am a Person, my name is %s' % self.name
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
def whoAmI(self):
return 'I am a Student, my name is %s' % self.name
class Teacher(Person):
def __init__(self, name, gender, course):
super(Teacher, self).__init__(name, gender)
self.course = course
def whoAmI(self):
return 'I am a Teacher, my name is %s' % self.name
在一个函数中,如果我们接收一个变量 x,则无论该 x 是 Person、Student还是 Teacher,都可以正确打印出结果:
def who_am_i(x):
print x.whoAmI()
p = Person('Tim', 'Male')
s = Student('Bob', 'Male', 88)
t = Teacher('Alice', 'Female', 'English')
who_am_i(p)
who_am_i(s)
who_am_i(t)
运行结果:
I am a Person, my name is Tim I am a Student, my name is Bob I am a Teacher, my name is Alice
这种行为称为多态。也就是说,方法调用将作用在 x 的实际类型上。s 是Student类型,它实际上拥有自己的 whoAmI()方法以及从 Person继承的 whoAmI方法,但调用 s.whoAmI()总是先查找它自身的定义,如果没有定义,则顺着继承链向上查找,直到在某个父类中找到为止。
由于Python是动态语言,所以,传递给函数 who_am_i(x)的参数x 不一定是 Person 或 Person 的子类型。任何数据类型的实例都可以,只要它有一个whoAmI()的方法即可:
class Book(object):
def whoAmI(self):
return 'I am a book'
这是动态语言和静态语言(例如Java)最大的差别之一。动态语言调用实例方法,不检查类型,只要方法存在,参数正确,就可以调用。
多重继承
除了从一个父类继承外,Python允许从多个父类继承,称为多重继承。
多重继承的继承链就不是一棵树了,它像这样:
class A(object):
def __init__(self, a):
print 'init A...'
self.a = a
class B(A):
def __init__(self, a):
super(B, self).__init__(a)
print 'init B...'
class C(A):
def __init__(self, a):
super(C, self).__init__(a)
print 'init C...'
class D(B, C):
def __init__(self, a):
super(D, self).__init__(a)
print 'init D...'
看下图:
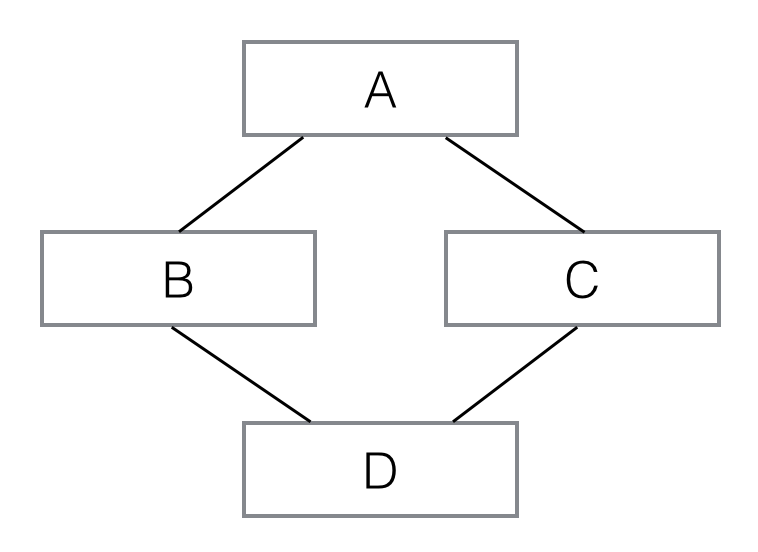
像这样,D 同时继承自 B 和 C,也就是 D 拥有了 A、B、C 的全部功能。多重继承通过 super()调用__init__()方法时,A 虽然被继承了两次,但__init__()只调用一次:
>>> d = D('d')
init A...
init C...
init B...
init D...
多重继承的目的是从两种继承树中分别选择并继承出子类,以便组合功能使用。
举个例子,Python的网络服务器有TCPServer、UDPServer、UnixStreamServer、UnixDatagramServer,而服务器运行模式有 多进程ForkingMixin 和 多线程ThreadingMixin两种。
要创建多进程模式的 TCPServer:
class MyTCPServer(TCPServer, ForkingMixin)
pass
要创建多线程模式的 UDPServer:
class MyUDPServer(UDPServer, ThreadingMixin):
pass
如果没有多重继承,要实现上述所有可能的组合需要 4x2=8 个子类。
获取对象信息
拿到一个变量,除了用 isinstance() 判断它是否是某种类型的实例外,还有没有别的方法获取到更多的信息呢?
例如,已有定义:
class Person(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
class Student(Person):
def __init__(self, name, gender, score):
super(Student, self).__init__(name, gender)
self.score = score
def whoAmI(self):
return 'I am a Student, my name is %s' % self.name
首先可以用 type() 函数获取变量的类型,它返回一个 Type 对象:
>>> type(123)
<type 'int'>
>>> s = Student('Bob', 'Male', 88)
>>> type(s)
<class '__main__.Student'>
其次,可以用 dir() 函数获取变量的所有属性:
>>> dir(123) # 整数也有很多属性... ['__abs__', '__add__', '__and__', '__class__', '__cmp__', ...] >>> dir(s) ['__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__hash__', '__init__', '__module__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'gender', 'name', 'score', 'whoAmI']
对于实例变量,dir()返回所有实例属性,包括`__class__`这类有特殊意义的属性。注意到方法`whoAmI`也是 s 的一个属性。
如何去掉`__xxx__`这类的特殊属性,只保留我们自己定义的属性?回顾一下filter()函数的用法。
dir()返回的属性是字符串列表,如果已知一个属性名称,要获取或者设置对象的属性,就需要用 getattr() 和 setattr( )函数了:
>>> getattr(s, 'name') # 获取name属性 'Bob' >>> setattr(s, 'name', 'Adam') # 设置新的name属性 >>> s.name 'Adam' >>> getattr(s, 'age') # 获取age属性,但是属性不存在,报错: Traceback (most recent call last): File "<stdin>", line 1, in <module> AttributeError: 'Student' object has no attribute 'age' >>> getattr(s, 'age', 20) # 获取age属性,如果属性不存在,就返回默认值20: 20