一、xpath库使用:
1、基本规则:
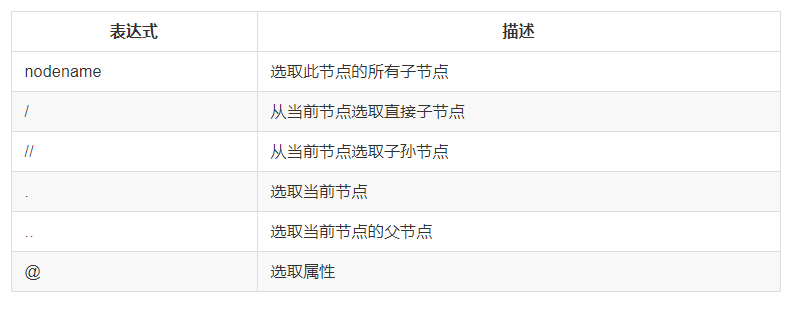
2、将文件转为HTML对象:
1 html = etree.parse('./test.html', etree.HTMLParser()) 2 result = etree.tostring(html) 3 print(result.decode('utf-8'))
3、属性多值匹配:
//a[contains(@class,'li')]
4、多属性匹配:
//a[@class="a" and @font="red"]
5、按序选择:

二、beautifulsoup库学习:
1、基本初始化:
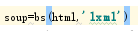
将HTML字符串用lxml格式来解析,并补全标签,创建html处理对象。
2、获取信息:
(1)获取title的name属性:
soup.title.name
(2)获取多属性:
(3)children返回孩子节点:
(4)find_all函数:查找所有的节点。
·通过节点名称来查找:
soup.find_all(name='li')
·通过属性名来查找:
soup.find_all(attrs={'id':'link1'})
··通过文本来查找:
soup.find_all(text='') 用来匹配网页节点中的文本内容。
3、css选择器:
.select() 方法。参数内容和jquery相似。
返回内容为列表,类型是tag类型。
三、pyquery库:
1、初始化:
·通过HTML字符串
·通过url
·通过文件名。需要指出文件名。
2、常用函数:
(1)find() 方法
(2)children()查找子结点
(3)查找父节点: parent()
(4)查找祖先节点:
parents()
(5)兄弟节点:
siblings() 方法
(6)对查找结果进行遍历:
.items()返回每一个节点。
(7) 获取节点信息:
·获取属性:
.attrs(‘属性名’)