
源码地址:https://github.com/ultralytics/yolov5
上一节,我们介绍了YOLOv5的配置和简单使用,本节我们重在解决自己场景的实际问题,进一步了解代码的组成。
源码结构
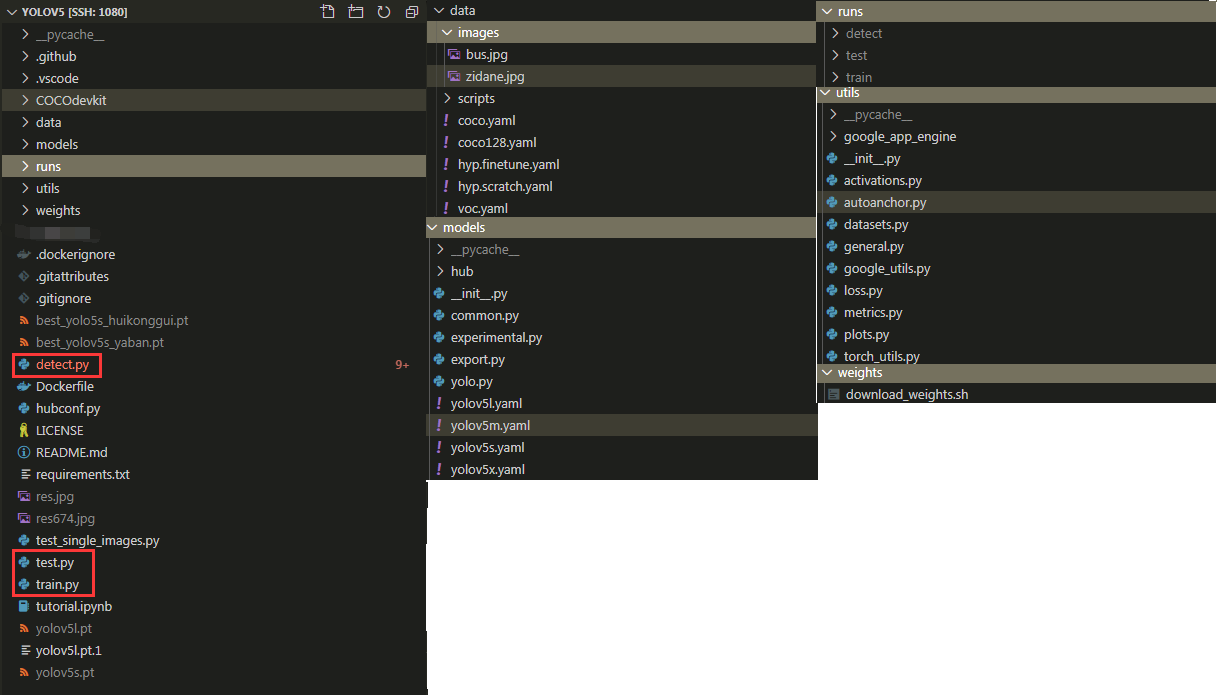
Pytorch版本的YOLOv5 源码结构如下图所示。
- train.py / test.py / detect.py:
- train.py : 训练
- test.py: 测试COCO指标
- detect.py : 批量检测图片并生成检测图像;
- data文件夹:包含自带验证的两张图像和相应训练数据地址,类别数量,类别名称等配置,可以类比Darknet中的voc.data;
- models文件夹: 包含网络结构的yaml文件以及网络实现所需的脚本文件;
- runs文件夹: 包含每次执行detect.py / test.py / train.py 的结果;
- utils文件夹: 包含网络训练、验证、测试所需要的脚本文件;
- weights文件夹: 下载预训练脚本的.sh文件。
整体流程
类比于Darknetyolov3/v4的配置,Pytorch版本YOLOv5在训练自己的数据集时需要包含以下步骤。

准备自己的数据集
本文采用与Darknet相似的处理方式进行数据集的放置,即将数据集统一放在COCOdevkit文件夹下(由于所使用的标注文件是json,不是xml的VOC)。大致结构如下图所示。

- 左图为数据集的基本结构以及准备过程生成的文件;
- 划分后的图像images
- 划分后的labels (txt格式)
- 汇总的txt文件
- 生成的anchor
- 中图为COCOdevikit的目录结构
- 右图为准备过程所需要的代码文件
- remove_img_without_jsonlabel.py : 去除没有标注文件的图像,并将不同文件夹下的图像和标注文件分别汇总到同一个文件夹下;
- show_labels.py : 显示标注文件中可能包含的标签(对于类型较多,例如标注名称包含状态类的,需要汇总标注名称的情况,对于标注类型较少情况可以跳过该脚本的执行)
- create_txt.py : 划分数据集为训练、验证和测试;生成对应的txt文件(包含每张图像的txt和训练、验证、测试汇总的txt文件),其中包含类型的映射;
- kmeans.py : Darknet YOLOv3中的anchor聚类脚本, 运行此脚本需要包含已经生成的汇总的txt文件。
整体流程与Darknet YOLOv3/v4的过程相似,具体如下图所示:

remove_img_without_jsonlabel.py
由于标注过程中图像和标注文件可能会分布在不同的文件夹下,并且可能会包含部分图像中没有待标注的目标(不存在标注文件),因此,需要将不同文件夹下的图像和标注文件汇总到各自的目录下,并去除没有标注文件的图像,使图像和标注文件统一。
使用下述代码需要修改图像的路径path,以及目标图像路径move_path_img和标注路径move_path_anno:
remove_img_without_jsonlabel.py
# -*- coding: utf-8 -*-
# @Time : 2021/1/15 9:06
# @Author : smw
# @Site : jnsenter
# @File : remove_img_without_jsonlabel.py
# @Software: PyCharm
# 功能:1. 统一标注和图像,将没有标注的图像删除;
# 2. 将不同文件夹下的图像和标注文件汇总到一个文件夹下
import os
import shutil
def scandir(path, file_list):
for item in os.scandir(path):
if item.is_dir():
scandir(item.path, file_list)
elif item.is_file():
file_list.append(item.path)
def image_remove(image_file_path, delete_num=0, residue_num=0):
move_path_img = "E:image_datasetyaban_train_imagesJPEGImages"
move_path_anno = "E:image_datasetyaban_train_imagesAnnotations"
os.makedirs(move_path_img, exist_ok=True)
os.makedirs(move_path_anno, exist_ok=True)
for root, dir, file_names in os.walk(image_file_path):
if not file_names: # 空
for _dir in dir:
next_dir = os.path.join(root, _dir)
delete_num, residue_num = image_remove(next_dir, delete_num, residue_num)
else: # 非空
for file_name in file_names:
image_path = os.path.join(root, file_name)
if image_path.endswith(".jpg"):
print("Process on {}".format(image_path))
json_path = image_path.replace(".jpg", ".json")
if not os.path.isfile(json_path): # 如果不是一个文件则删除图像
os.remove(image_path)
delete_num += 1
else: # 如果是一个文件 就把它们统一汇总在一起
img_dir = os.path.join(move_path_img, file_name)
anno_dir = os.path.join(move_path_anno, file_name.replace(".jpg", ".json"))
shutil.move(image_path, img_dir)
shutil.move(json_path, anno_dir)
residue_num += 1
else: # 非jpg文件跳过不处理
continue
return delete_num, residue_num
if __name__ == '__main__':
path = "E:image_datasetyaban"
delete_num, residue_num = image_remove(path)
print(delete_num, residue_num)
show_labels.py
本脚本适合以下情况:
- 对于标注文件中类型较多,需要汇总的情况;
- 对于需要在标注文件中提取待训练的类型(工程实际中,往往会对一张图像上包含的目标进行统一标注,不返工;其中可能会包含此次不需要训练的目标)
使用前提是在知道目标类型的部分开头的情况下。
需要修改json文件的路径json_path,以及筛选的labelcandidate_label.
import json
import os
import os.path as osp
import sys
import shutil
import math
import numpy as np
# 本脚本的目的在于显示json中包含的标签名称
# 由于标注时会临时添加某种类型的某个标签,无法获取该有的标签类型
# 在获得标签名称后,可以移步create_txt.py生成label
if __name__ == "__main__":
json_path = "/home/smw/Project/yolov5/COCOdevkit/COCO2021/labels_json"
json_dir = [os.path.join(json_path, json_name) for json_name in os.listdir(json_path)]
# 筛选的label
candidate_label = ['XX1', 'XX2']
# 建立label
label_list = [] # 用于存放不同符合要求的label
# 循环读取json文件,并获得其中的label
for js in json_dir:
with open(js, "r", encoding="utf-8") as f:
json_info = json.load(f)
shapes_info = json_info.get("shapes")
for label in shapes_info:
label_name = label.get("label")
flag = [True if label_name.startswith(m) else False for m in candidate_label]
flag_sum = sum(flag) # 是否所有的筛选label都不符合
if not flag_sum: # 如果均不符合 则跳过 到下一个标签
continue
# 若符合,进行label_list 的添加
if label_name not in label_list:
label_list.append(label_name)
print(label_list)
create_txt.py
YOLOv5中训练需要json文件生成的txt文件。并且包含单张图像的txt文件和训练、验证、测试汇总的txt文件。
-
单张图像包含的txt文件示例
包含类别序号、x、y、w、h的相对位置。

-
汇总的txt文件示例
包含图像名称、以逗号分割的左上角点坐标 右下角点坐标(x1, y1, x2, y2, classid)以及类别序号,不同框之间以空格作为分隔符。

其中,会过滤掉不包含预定目标的图像以及json文件。
create_txt.py
# -*- coding: utf-8 -*-
# @Time : 2021/1/15 16:06
# @Author : smw
# @Site : jnsenter
# @File : create_txt.py
# @Software: PyCharm
import json
import os
import os.path as osp
import sys
import shutil
import math
import numpy as np
from functools import reduce
import logging
import logging.handlers
import logging.config
# 功能: 将数据集划分为训练集、验证集、测试集,并生成对应的txt于train_2021, val_2021, test_2021
classses = ['XX1', 'XX2']
sets = [('2022', 'train'), ('2022', 'val'), ("2022", "test")] # float为划分比例 需保证比例总和为1
ratio = [0.8, 0.1, 0.1]
names_reflect = {"XX1": "YY1", "XX2": "YY2"}
# print(names_reflect.values())
# print("")
def initLog(logfile):
logger = logging.getLogger()
# 指定日志的最低输出级别,默认为WARN级别
logger.setLevel(logging.INFO)
fileHandeler = logging.handlers.TimedRotatingFileHandler(logfile, 'M', 1, 0, encoding="utf-8")
# rotate_handler = ConcurrentRotatingFileHandler(logfile, "a", 1024 * 1024 * 100 * 6, backupCount=5, encoding="utf-8")
# 指定logger输出格式
formatter = logging.Formatter('%(asctime)s %(levelname)s %(message)s')
fileHandeler.setFormatter(formatter)
# 为logger添加的日志处理器
logger.addHandler(fileHandeler)
return logger
def convert(size, box):
"""坐标转换为中心点坐标+宽高"""
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def image_datasets_split(year, image_set, json_path, data, names_reflect, f_main, logger):
"""移动图像数据到相应的训练 测试 验证文件夹下"""
move_path_image = "/home/smw/Project/yolov5/COCOdevkit/COCO{}/images/{}".format(year, image_set+year)
os.makedirs(move_path_image, exist_ok=True)
save_label_path = "/home/smw/Project/yolov5/COCOdevkit/COCO{}/labels/{}".format(year, image_set+year)
os.makedirs(save_label_path, exist_ok=True)
no_object_num = 0
main_info_list = [] # 汇总的txt
for path in data: # 某中数据集的循环
image_name = os.path.split(path)[1]
if not image_name.endswith(".jpg"):
logger.warning("{} is not endwith the .jpg".format(path))
print("{} is not endwith the .jpg".format(path))
continue
# label txt
save_txt_dir = os.path.join(save_label_path, image_name.replace(".jpg", ".txt"))
# 1. 读取json 信息
json_name = image_name.replace(".jpg", ".json")
json_dir = os.path.join(json_path, json_name)
# 再次验证json文件是否存在
if not os.path.isfile(json_dir):
logger.info("{} is not exist".format(json_dir))
print("{} is not exist".format(json_dir))
continue
# 2. 过滤标签
label_names = list(names_reflect.keys())
with open(json_dir, "r", encoding="utf-8") as f:
json_info = json.load(f)
shapes_info = json_info.get("shapes")
info_num = 0
info_list = [] # 单个的label txt
main_info_list_pick = [image_name]
h = json_info.get("imageHeight")
w = json_info.get("imageWidth")
img_size = (w, h)
for label_info in shapes_info:
if label_info.get("shape_type") != 'rectangle': # 过滤掉标错的 类别名称相同的内容
continue
label_name = label_info.get("label")
if not label_name in label_names: # 标注类型符合后 过滤标签名字
continue
# 准备写txt的内容
info_num += 1 # 符合数量增
label_reflect_name = names_reflect[label_name]
label_class_id = label_names.index(label_name) # info 1
points = label_info.get("points")
x, y, _w, _h = convert(img_size, [points[0][0], points[1][0],points[0][1], points[1][1]]) # 转xywh
info_list.append([label_class_id, x, y, _w, _h]) # 记录信息
main_info_list_pick.append([str(math.floor(points[0][0])), str(math.floor(points[0][1])), str(math.floor(points[1][0])), str(math.floor(points[1][1])), str(label_class_id)])
if info_num > 0: # 存在目标对象, 开始写txt,移动图像, 否则不移动图像
# ToDo 移动图像,写txt
# 如果不存在,则移动
if not os.path.isfile(os.path.join(move_path_image, image_name)):
# 移动图像
shutil.copy(path, os.path.join(move_path_image, image_name))
# shutil.move(path, os.path.join(move_path_image, image_name))
# 写txt
if not os.path.isfile(save_txt_dir):
with open(save_txt_dir, "w") as f_txt:
for write_info in info_list:
write_info_str = map(str, write_info)
str_info = " ".join(write_info_str)
f_txt.write(str_info)
f_txt.write("
")
else: # 不存在目标
# ToDo 不移动目标也不写txt 加日志输出
no_object_num += 1
logger.info("{} file does not have object!".format(image_name))
print("{} file does not have object!".format(image_name))
if len(main_info_list_pick) != 1:
main_info_list.append(main_info_list_pick) # 汇总每张图的
# 所有图像汇总好后,写train2021.txt
main_txt_write(main_info_list, f_main)
return no_object_num
def main_txt_write(info_list, f):
def add_dou(x, y):
return x+","+y
def add_space(x, y):
return x+" "+y
for info in info_list:
image_name = info[0]
bbox_list = []
for info_bbox in info[1:]:
info_single = reduce(add_dou, info_bbox)
bbox_list.append(info_single)
info_str_all = image_name + " " + reduce(add_space, bbox_list)
f.write(info_str_all)
f.write("
")
print("")
if __name__ == "__main__":
pwd = os.getcwd()
print(pwd)
logfile = os.path.join(pwd, "run.log")
logger = initLog(logfile)
image_path = "/home/smw/Project/yolov5/COCOdevkit/COCO2021/images_ori"
json_path = "/home/smw/Project/yolov5/COCOdevkit/COCO2021/labels_json"
main_txt_path = "/home/smw/Project/yolov5/COCOdevkit/COCO{}".format(sets[0][0])
image_dir = [os.path.join(image_path, image_name) for image_name in os.listdir(image_path)]
json_dir = [os.path.join(json_path, json_name) for json_name in os.listdir(json_path)]
image_info = np.array(image_dir) # image_dir 和 json_dir 的序号直接拼接对不上 因此仅以图像为主!!
# 判断数量一致
image_num = len(image_dir)
json_num = len(json_dir)
if image_num != json_num:
logger.error(" The num of images is not equal to json, please excute remove_img_without_jsonlabel.py first")
print(" The num of images is not equal to json, please excute remove_img_without_jsonlabel.py first")
sys.exit(0) # 此处可以进行删除无json的图像的代码 代替退出程序!!
else:
logger.info("The num of images is equal to json")
logger.info("The num of images is {}, the number of images is {}".format(image_num, json_num))
print(" The num of images is not equal to json, please excute remove_img_without_jsonlabel.py first")
# 数据集划分 只看数据 json文件没有再说吧
image_num_index = list(range(image_num))
np.random.shuffle(image_num_index)
train_end_num = int(image_num * ratio[0])
val_end_num = int(image_num * (ratio[0] + ratio[1])) # 没有对是否有测试 验证集的兼容!!
print(image_info[0])
print(image_info.shape)
print(type(image_num_index))
train_info = image_info[image_num_index[:train_end_num]]
val_info = image_info[image_num_index[train_end_num: val_end_num]]
test_info = image_info[image_num_index[val_end_num:]]
logger.info("train num: {}".format(train_info.shape[0]))
logger.info("val num:{}".format(val_info.shape[0]))
logger.info("test num{}".format(test_info.shape[0]))
print("train num: {}".format(train_info.shape[0]))
print("val num:{}".format(val_info.shape[0]))
print("test num:{}".format(test_info.shape[0]))
print("The number of total split data is {}".format(train_info.shape[0]+val_info.shape[0]+test_info.shape[0])) # 目前来看划分后的数据和总数是相等的
no_object_list = []
for path_info, data in zip(sets, (train_info, val_info, test_info)):
year = path_info[0]
image_set = path_info[1]
main_txt_dir = os.path.join(main_txt_path, image_set+year+".txt")
f = open(main_txt_dir, "w")
no_object_num = image_datasets_split(year, image_set, json_path, data, names_reflect, f, logger)
no_object_list.append(no_object_num)
f.close()
print("{} finished!".format(image_set))
print("No object Number:")
print("train: {}".format(no_object_list[0]))
print("val: {}".format(no_object_list[1]))
print("test: {}".format(no_object_list[2]))
kmeans.py
用于anchor的优化,直接使用darknet中的kmeans.py即可。在使用前需要具有汇总的txt文件,并在代码中修改相应的路径,示例如下:
if __name__ == "__main__":
cluster_number = 9
filename = "/home/smw/Project/yolov5/COCOdevkit/COCO2022/train2022.txt"
kmeans = YOLO_Kmeans(cluster_number, filename)
kmeans.txt2clusters()
另外,对于YOLOv5而言,无论是轻量级模型YOLOv5s还是达模型YOLOv5l,anchor的数量都是9个,不像YOLOv3/v4的tiny模型,anchor数量为6。
kmeans.py
import numpy as np
class YOLO_Kmeans:
def __init__(self, cluster_number, filename):
self.cluster_number = cluster_number
self.filename = filename
def iou(self, boxes, clusters): # 1 box -> k clusters
n = boxes.shape[0]
k = self.cluster_number
box_area = boxes[:, 0] * boxes[:, 1] # 把要聚类的框的宽高相乘,作为了一个box_area
box_area = box_area.repeat(k) # 要算到k个类中心的距离,需要搞一个每个都有k个的矩阵
box_area = np.reshape(box_area, (n, k))
cluster_area = clusters[:, 0] * clusters[:, 1]
cluster_area = np.tile(cluster_area, [1, n])
cluster_area = np.reshape(cluster_area, (n, k))
# 把box和cluster的宽都整理成n行k列的形式,并把两者做比较,最后还是一个n行k列的形式,这个
# 过程其实在比较box和两个cluster的宽,并选出小的
box_w_matrix = np.reshape(boxes[:, 0].repeat(k), (n, k))
cluster_w_matrix = np.reshape(np.tile(clusters[:, 0], (1, n)), (n, k))
min_w_matrix = np.minimum(cluster_w_matrix, box_w_matrix)
# 把box和cluster的高都整理成n行k列的形式,并把两者做比较,最后还是一个n行k列的形式,这个
# 过程其实在比较box和两个cluster的高,并选出小的
box_h_matrix = np.reshape(boxes[:, 1].repeat(k), (n, k))
cluster_h_matrix = np.reshape(np.tile(clusters[:, 1], (1, n)), (n, k))
min_h_matrix = np.minimum(cluster_h_matrix, box_h_matrix)
# 将筛选出来的小的宽高 相乘
inter_area = np.multiply(min_w_matrix, min_h_matrix)
result = inter_area / (box_area + cluster_area - inter_area)
return result
def avg_iou(self, boxes, clusters):
accuracy = np.mean([np.max(self.iou(boxes, clusters), axis=1)])
return accuracy
def kmeans(self, boxes, k, dist=np.median):
box_number = boxes.shape[0]
distances = np.empty((box_number, k))
last_nearest = np.zeros((box_number,))
np.random.seed()
clusters = boxes[np.random.choice(
box_number, k, replace=False)] # 随机选择k个类中心
while True:
distances = 1 - self.iou(boxes, clusters)
current_nearest = np.argmin(distances, axis=1)
if (last_nearest == current_nearest).all():
break # clusters won't change
for cluster in range(k):
# print(clusters[cluster])
# print(boxes[current_nearest == cluster])
# print(np.mean(boxes[current_nearest == cluster][:, 0]))
clusters[cluster] = dist(boxes[current_nearest == cluster], axis=0) # update clusters
# 类中心的修改选取的是中位数 不是平均值
last_nearest = current_nearest
return clusters
def result2txt(self, data):
f = open("/home/smw/Project/yolov5/COCOdevkit/COCO2022/huikonggui2022.txt", 'w')
row = np.shape(data)[0]
for i in range(row):
if i == 0:
x_y = "%d,%d" % (data[i][0], data[i][1])
else:
x_y = ", %d,%d" % (data[i][0], data[i][1])
f.write(x_y)
f.close()
def txt2boxes(self):
f = open(self.filename, 'r')
dataSet = []
for line in f:
infos = line.split(" ")
length = len(infos)
for i in range(1, length):
width = int(infos[i].split(",")[2]) -
int(infos[i].split(",")[0])
height = int(infos[i].split(",")[3]) -
int(infos[i].split(",")[1])
dataSet.append([width, height])
result = np.array(dataSet)
f.close()
return result
def txt2clusters(self):
all_boxes = self.txt2boxes() # 将txt中数值信息转化为图像标记框的宽高,并返回
result = self.kmeans(all_boxes, k=self.cluster_number)
result = result[np.lexsort(result.T[0, None])]
self.result2txt(result)
print("K anchors:
{}".format(result))
print("Accuracy: {:.2f}%".format(
self.avg_iou(all_boxes, result) * 100)
if __name__ == "__main__":
cluster_number = 9
filename = "/home/smw/Project/yolov5/COCOdevkit/COCO2022/train2022.txt"
kmeans = YOLO_Kmeans(cluster_number, filename)
kmeans.txt2clusters()
综上所述,执行完上述步骤,YOLOv5的准备工作基本完成。
修改配置参数
准备工作完成后,需要修改相关的配置参数,具体包含需要修改如下文件:
-
data/coco128.yaml
- 训练、测试、验证集图像的路径
- 类别数量
- 类别名称
-
models/yolov5s/m/x/l.yaml
- 类别数量
- anchor
后续在介绍网络结构时会详细介绍不同配置参数的作用。
训练 train.py
train.py用于模型的训练主要需要有如下参数进行传递,可以使用配置参数传递的方式,也可以在源码中进行修改。
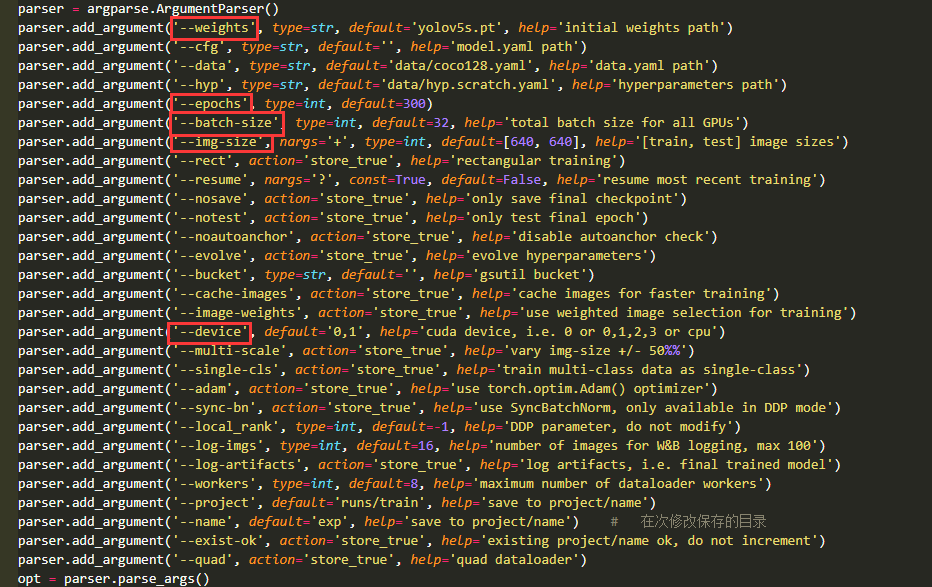
-
传递的方式:

按照上图修改执行后,会在runs/train/exp文件夹下生成训练的相关文件,可以对--project和--name修改其保存路径。
其中,模型会保存在runs/train/exp/weights文件夹下,最终会保存两个模型,其一为best.pt,其二为last.pt。另外,还会包含训练过程中的结果图、日志等相关信息;hyp.yaml中汇总了模型中使用超参数的值,可以根据模型的效果进行进一步调整(数据增强)。
指标测试 test.py
test.py用于测试COCO指标,并生成回调曲线。参数主要包含以下参数。同样可以使用修改源码和传递参数两种方式进行参数传递。
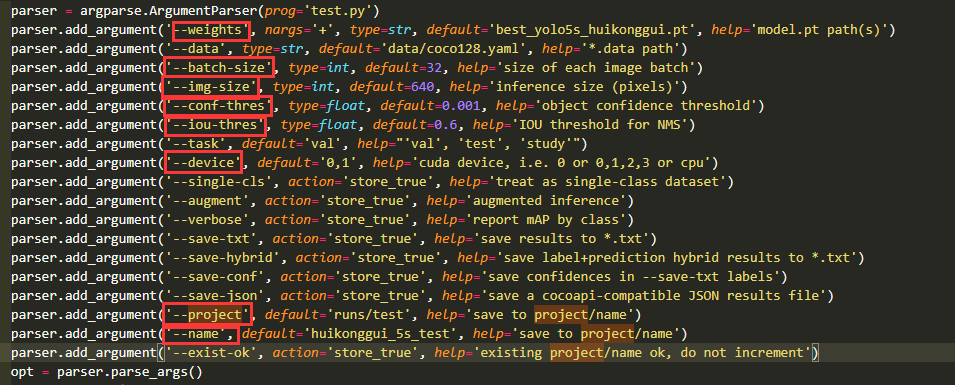
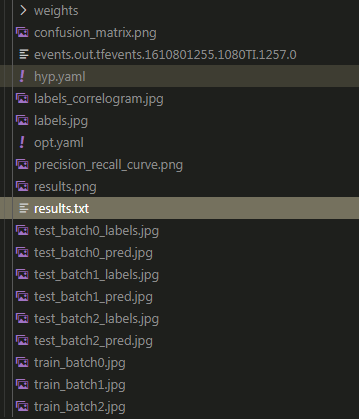
按照上图修改执行后,会在runs/test/huikonggui_5s_test文件夹下生成下述文件。

批量测试结果图 detect.py
detect.py用于批量生成检测结果,参数主要包含以下参数。同样可以使用修改源码和传递参数两种方式进行参数传递。
按照上图修改执行后,会在runs/detect/no_label_huikonggui_5s下生成检测结果图。