变量的声明
python中变量的声明是很简单的,不用显式的给出变量的类型,因为它是一门动态语言,会在执行时依据值的类型来确定变量的类型!
!# -*- coding:utf-8 -*- __author__ = "monkey"
上述代码定义了名为 __author__的变量 值 为 "monkey"
变量命名规则:
- 变量名只能是 字母、数字或下划线的任意组合
- 变量名的第一个字符不能是数字
- 变量名尽量取的有某种含义,表明这个变量的作用
- 尽量避霾中文变量名(虽然Python支持,但是不推荐使用)
- Python中的关键字不能声明为变量
到Python3.6版本为止 Python共有关键字为:
['False', 'None', 'True', 'and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
查看Python版本支持的关键字:
help("keywords")
或者
>>> import keyword >>> keyword.kwlist
变量的赋值
变量名 = 值/已定义的变量名
name = ”monkey“
print(name)
monkey
变量名为 name 值 为str类型的 “monkey”
new_name = name print(new_name) monkey
变量名为 new_name 值 已定义的变量名 name
Python中的常量
在Python中常量和变量是没有任何区别的,但是 我们习惯于 用全大写变量名来声明一个常量
PATH = '/usr/bin/bash' URL = '/etc/vmware/'
基本数据类型
整形(int)
Python的整数没有指定位宽,物理内存有多大,理论上整形数就能多大,自从Python2.2起,如果整数发生溢出,Python会自动将整数数据转换为长整数,所以如今在长整数数据后面不加字母L也不会导致严重后果了。
浮点型(float)
浮点数用来处理实数,即带有小数的数字。类似于C语言中的double类型,占8个字节(64位),其中52位表示底,11位表示指数,剩下的一位表示符号。
复数
布尔值(bool)
True 和 False
Python中的对象都自带bool属性
bool()
bool([]) #-->False
bool('') #-->False
bool({}) #-->False
bool(()) #-->False
bool(0) #-->False
bool(1 == 2) #-->False
bool(None) #-->Fales
bool('0') #-->Ture
bool([1, 2]) #-->Ture
字符串
被单引号 或 双引号引起来的部分 'hello world!'
列表
是一个存放对象的容器
定义
""" 定义列表的方法 """ lst1 = list(range(1,10,2)) #list()方法 lst2 = [1,3,5,7,9] #手撸 lst3 = [i for i in range(1,10,2)] #列表生成式
方法
- 移除空白
- 分割
- 长度
- 索引
- 切片
- 合并
- 排序
元组
也叫只读列表
定义
tuple0 = ('name',1,'age',2,1) #手撸
tuple2 = tuple([1,2,3]) # tuple方法
方法
- 索引
- 修改
字典
字典的实现方式是hash散列函数,字典的形式为 键(key)值(value)对对应关系集合,并且key 必须是一个字符串或是数字,是一个具体的对象而不是引用。value 几乎可以是任意的 对象 或 引用 都是可以的,甚至可以是 对象的动态方法或自定义函数 此时应注意()的作用
定义
dict0=dict.fromkeys([1,2,3,4,5,6],'侯老师') # 初始化一个新的字典键为123...值为'侯老师'的字典
dict1={'name':'monkey','age':'ten','high':'280cm'} # 手撸 dict_ = {k:v for k,v in zip(range(10),range(10))} # 字典生成式
方法
- 增加
- 删除
- 修改
- 查询
- 循环
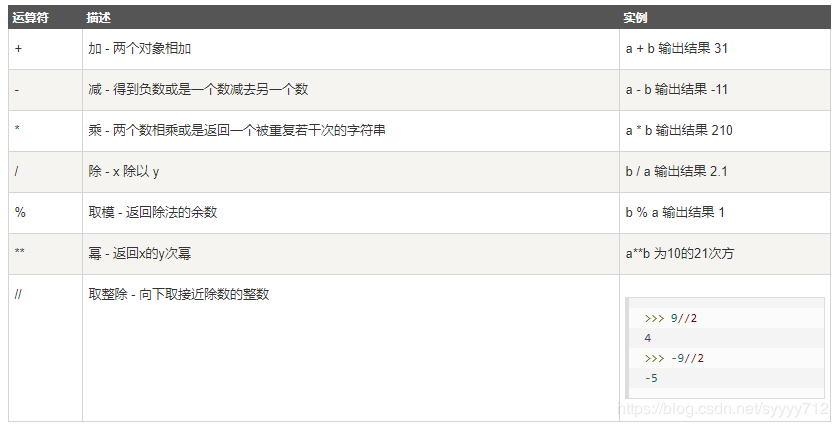
Python中的运算符
算术运算符
比较运算符

逻辑运算

赋值运算符

成员运算

身份运算符

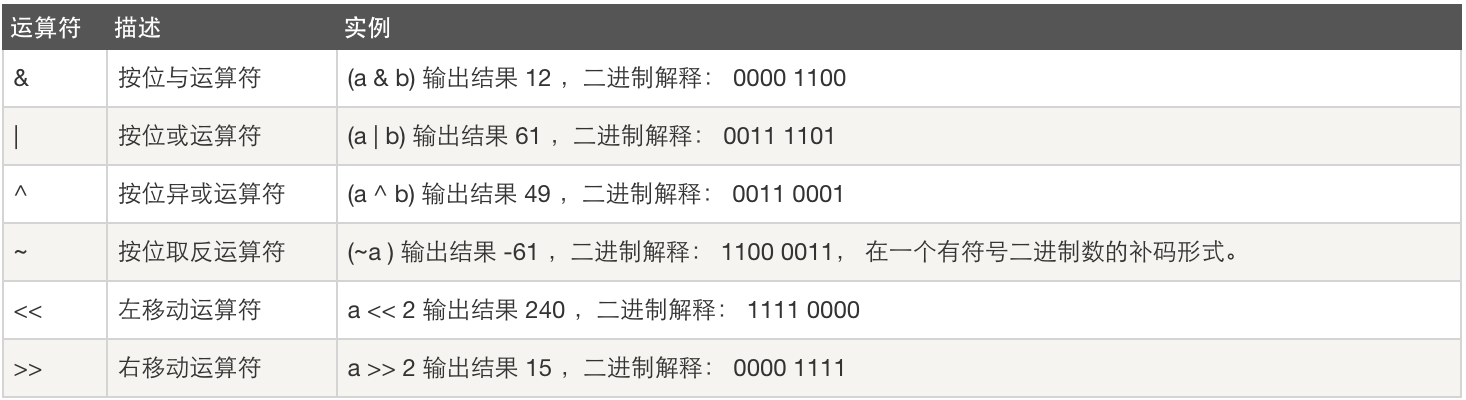
位运算符
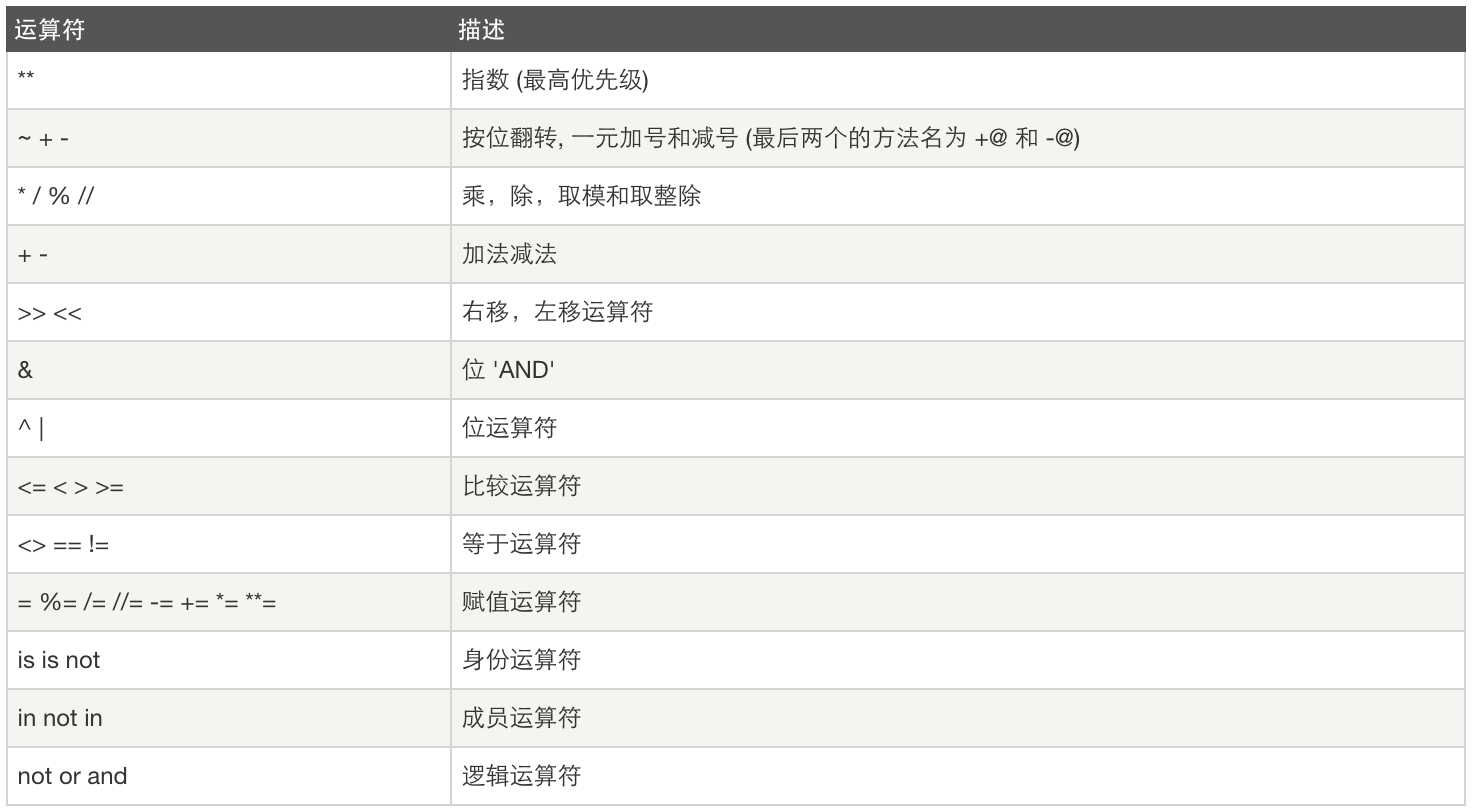
运算优先级
循环和分支语句
if条件语句
if (能得出bool的表达式或变量或条件):
statement 1
else:
statement 2
一个比大小的if示例


1 num1 = 10 2 num2 = 20 3 4 if num1 > num2: 5 max = num1 6 else: 7 max = num2
在Python中,else if 被合并成elif关键字,使用时注意结构应该是:
if: ... elif: ... else: ...
for循环语句
for <variable> in <sequence>:
<statements>
示例
#!/usr/bin/env python3
#_*_ coding: utf-8 _*_
__author__ = "monkey"
for i in rang(10)
print(i)
while循环语句
while 循环终止条件:
statement
#!/usr/bin/env python3
#_*_ coding: utf-8 _*_
__author__ = "monkey"
N = 100
counter = 0
while counter != 100:
counter += 1
print("我循环了{}次".format(counter))
循环中的 else、break、continue的用法
else
在for和while循环中的 else 表示这样的意思, 循环中的语句和普通的没有区别, else 中的语句会在循环正常执行完(即循环不是通过 break 跳出而中断的)的情况下执行。
示例:
#!/usr/bin/env python3
#_*_ coding: utf-8 _*_
__author__ = "monkey"
lst = ["爱","我","中","华"]
for index,elem in enumerate(lst):
if elem == "中":
print('"中"的索引值为:{}'.format(index))
break
else:
print('"中"不在列表中')
break
break 会跳出本层循环体,如果是多层的嵌套循环,则外层循环依旧继续
示例:
#!/usr/bin/env python3
# _*_ coding: utf-8 _*_
__author__ = "monkey"
for i in range(6):
for j in range(100):
if i == 3:
print(i,j)
break
print(i)
输出的结果为:
0
1
2
3 0
3
4
5
continue
循环中遇见continue关键字时,会在此处终止本次循环,直接开始下一次循环,而不是终止本层循环
示例
#!/usr/bin/env python3
# _*_ coding: utf-8 _*_
__author__ = "monkey"
for j in range(6):
if j==3:
continue
print(j)
结果:
0
1
2
4
5
Python之禅
>>> import this The Zen of Python, by Tim Peters Beautiful is better than ugly. Explicit is better than implicit. Simple is better than complex. Complex is better than complicated. Flat is better than nested. Sparse is better than dense. Readability counts. Special cases aren't special enough to break the rules. Although practicality beats purity. Errors should never pass silently. Unless explicitly silenced. In the face of ambiguity, refuse the temptation to guess. There should be one-- and preferably only one --obvious way to do it. Although that way may not be obvious at first unless you're Dutch. Now is better than never. Although never is often better than *right* now. If the implementation is hard to explain, it's a bad idea. If the implementation is easy to explain, it may be a good idea. Namespaces are one honking great idea -- let's do more of those!
Python代码规范
代码注释
在Python中代码的注释有两种,一种为块级注释或多行注释,一种为行内注释或单行注释。
- 多行注释部分用三引号包起来 : """被注释内容"""
- 单行注释跟在 # 符号后面: # 这是注释(注意 不要紧跟代码 也不需要对齐 适当即可 # 和注释之间有一个空格)
- 写代码 要有注释的习惯,因为读懂别人的代码是不易的,甚至看自己曾经写的代码也是一件痛苦的事情
- 我认为注释的重要性,甚至高于代码本身
* Python的代码编写要严格遵循 PEP8标准
Python命名空间和作用域
命名空间
定义:
名称到对象的映射。命名空间是一个字典的实现,键为变量名,值是变量对应的值。各个命名空间是独立没有关系的,一个命名空间中不能有重名,但是不同的命名空间可以重名而没有任何影响。
分类:
python程序执行期间会有2个或3个活动的命名空间(函数调用时有3个,函数调用结束后2个)。按照变量定义的位置,可以划分为以下3类:
- Local,局部命名空间,每个函数所拥有的命名空间,记录了函数中定义的所有变量,包括函数的入参、内部定义的局部变量。(每一个递归函数都拥有自己的命名空间)。
- Global,全局命名空间,每个模块加载执行时创建的,记录了模块中定义的变量,包括模块中定义的函数、类、其他导入的模块、模块级的变量与常量。
- Built-in,python自带的内建命名空间,任何模块均可以访问,放着内置的函数和异常,Python解释器启动时创建,解释器退出时销毁。
创建顺序:
- python解释器启动 ->创建内建命名空间 -> 加载模块 -> 创建全局命名空间 ->函数被调用 ->创建局部命名空间
- 各命名空间销毁顺序:函数调用结束 -> 销毁函数对应的局部命名空间 -> python虚拟机(解释器)退出 ->销毁全局命名空间 ->销毁内建命名空间
- python解释器加载阶段会创建出内建命名空间、模块的全局命名空间,局部命名空间是在运行阶段函数被调用时动态创建出来的,函数调用结束动态的销毁的。
作用域
定义:
作用域是针对变量而言,指申明的变量在程序里的可应用范围。即某个命名空间中的名字可以被直接引用的范围,就称为这个命名空间的作用域。
分类:
只有函数、类、模块会产生作用域,代码块不会产生作用域。作用域按照变量的定义位置可以划分为4类:
Local(函数内部)局部作用域
Enclosing(嵌套函数的外层函数内部)嵌套作用域(闭包)
Global(模块全局)全局作用域
Built-in(内建)内建作用域
命名空间和作用域的关系
- 命名空间定义了在某个作用域内变量名和绑定值之间的对应关系,命名空间是键值对的集合,变量名与值是一一对应关系。作用域定义了命名空间中的变量能够在多大范围内起作用。
- 命名空间在python解释器中是以字典的形式存在的,是以一种可以看得见摸得着的实体存在的。作用域是python解释器定义的一种规则,该规则确定了运行时变量查找的顺序,是一种形而上的虚的规定。
变量查找法则
python解释器动态执行过程中,对遇到的变量进行解释时,是按照一条固定的作用域链查找解释的,又称为LEGB法则。
其中L代表Local 局部作用域,E代表Enclosing 嵌套作用域,G代表Global 全局作用域,B代表Built-in 内建作用域。
python解释器查找变量时,会按照顺序依次查找局部作用域,嵌套作用域,全局作用域,内建作用域,在任意一个作用域中找到变量则停止查找,所有作用域查找完成没有找到对应的变量,则抛出 NameError: name 'xxxx' is not defined的异常。
在局部作用域中,可以看到局部作用域、嵌套作用域、全局作用域、内建作用域中所有定义的变量。
在全局作用域中,可以看到全局作用域、内建作用域中的所有定义的变量,无法看到局部作用域中的变量。