From Here: https://zhuanlan.zhihu.com/p/24425116
Python下使用OpenCV
本篇将介绍和深度学习数据处理阶段最相关的基础使用,并完成4个有趣实用的小例子:
- 延时摄影小程序
- 视频中截屏采样的小程序
- 图片数据增加(data augmentation)的小工具
- 物体检测框标注小工具
其中后两个例子的代码可以在下面地址直接下载:
frombeijingwithlove/dlcv_for_beginners
6.1 OpenCV简介
OpenCV是计算机视觉领域应用最广泛的开源工具包,基于C/C++,支持Linux/Windows/MacOS/Android/iOS,并提供了Python,Matlab和Java等语言的接口,因为其丰富的接口,优秀的性能和商业友好的使用许可,不管是学术界还是业界中都非常受欢迎。OpenCV最早源于Intel公司1998年的一个研究项目,当时在Intel从事计算机视觉的工程师盖瑞·布拉德斯基(Gary Bradski)访问一些大学和研究组时发现学生之间实现计算机视觉算法用的都是各自实验室里的内部代码或者库,这样新来实验室的学生就能基于前人写的基本函数快速上手进行研究。于是OpenCV旨在提供一个用于计算机视觉的科研和商业应用的高性能通用库。 第一个alpha版本的OpenCV于2000年的CVPR上发布,在接下来的5年里,又陆续发布了5个beta版本,2006年发布了第一个正式版。2009年随着盖瑞加入了Willow Garage,OpenCV从Willow Garage得到了积极的支持,并发布了1.1版。2010年OpenCV发布了2.0版本,添加了非常完备的C++接口,从2.0开始的版本非常用户非常庞大,至今仍在维护和更新。2015年OpenCV 3正式发布,除了架构的调整,还加入了更多算法,更多性能的优化和更加简洁的API,另外也加强了对GPU的支持,现在已经在许多研究机构和商业公司中应用开来。
6.1.1 OpenCV的结构
和Python一样,当前的OpenCV也有两个大版本,OpenCV2和OpenCV3。相比OpenCV2,OpenCV3提供了更强的功能和更多方便的特性。不过考虑到和深度学习框架的兼容性,以及上手安装的难度,这部分先以2为主进行介绍。
根据功能和需求的不同,OpenCV中的函数接口大体可以分为如下部分:
- core:核心模块,主要包含了OpenCV中最基本的结构(矩阵,点线和形状等),以及相关的基础运算/操作。
- imgproc:图像处理模块,包含和图像相关的基础功能(滤波,梯度,改变大小等),以及一些衍生的高级功能(图像分割,直方图,形态分析和边缘/直线提取等)。
- highgui:提供了用户界面和文件读取的基本函数,比如图像显示窗口的生成和控制,图像/视频文件的IO等。
如果不考虑视频应用,以上三个就是最核心和常用的模块了。针对视频和一些特别的视觉应用,OpenCV也提供了强劲的支持:
- video:用于视频分析的常用功能,比如光流法(Optical Flow)和目标跟踪等。
- calib3d:三维重建,立体视觉和相机标定等的相关功能。
- features2d:二维特征相关的功能,主要是一些不受专利保护的,商业友好的特征点检测和匹配等功能,比如ORB特征。
- object:目标检测模块,包含级联分类和Latent SVM
- ml:机器学习算法模块,包含一些视觉中最常用的传统机器学习算法。
- flann:最近邻算法库,Fast Library for Approximate Nearest Neighbors,用于在多维空间进行聚类和检索,经常和关键点匹配搭配使用。
- gpu:包含了一些gpu加速的接口,底层的加速是CUDA实现。
- photo:计算摄像学(Computational Photography)相关的接口,当然这只是个名字,其实只有图像修复和降噪而已。
- stitching:图像拼接模块,有了它可以自己生成全景照片。
- nonfree:受到专利保护的一些算法,其实就是SIFT和SURF。
- contrib:一些实验性质的算法,考虑在未来版本中加入的。
- legacy:字面是遗产,意思就是废弃的一些接口,保留是考虑到向下兼容。
- ocl:利用OpenCL并行加速的一些接口。
- superres:超分辨率模块,其实就是BTV-L1(Biliteral Total Variation – L1 regularization)算法
- viz:基础的3D渲染模块,其实底层就是著名的3D工具包VTK(Visualization Toolkit)。
从使用的角度来看,和OpenCV2相比,OpenCV3的主要变化是更多的功能和更细化的模块划分。
6.1.2 安装和使用OpenCV
作为最流行的视觉包,在Linux中安装OpenCV是非常方便的,大多数Linux的发行版都支持包管理器的安装,比如在Ubuntu 16.04 LTS中,只需要在终端中输入:
>> sudo apt install libopencv-dev python-opencv
当然也可以通过官网下载源码编译安装,第一步先安装各种依赖:
>> sudo apt install build-essential
>> sudo apt install cmake git libgtk2.0-dev pkg-config libavcodec-dev libavformat-dev libswscale-dev
>> sudo apt-get install python-dev python-numpy libtbb2 libtbb-dev libjpeg-dev libpng-dev libtiff-dev libjasper-dev libdc1394-22-dev
然后找一个clone压缩包的文件夹,把源码拿下来:
>> git clone opencv/opencv
然后进入OpenCV文件夹:
>> mkdir release
>> cd release
>> cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local ..
准备完毕,直接make并安装:
>> make
>> sudo make install
Windows下的安装也很简单,直接去OpenCV官网下载:
执行exe安装后,会在<安装目录>/build/python/2.7下发现一个叫cv2.pyd的文件,把这个文件拷贝到<Python目录>Libsite-packages下,就可以了。Windows下如果只想在Python中体验OpenCV还有个更简单的方法是加州大学尔湾分校(University of California, Irvine)的Christoph Gohlke制作的Windows下的Python科学计算包网页,下载对应版本的wheel文件,然后通过pip安装:
http://www.lfd.uci.edu/~gohlke/pythonlibs/#opencv
本书只讲Python下OpenCV基本使用,Python中导入OpenCV非常简单:
import cv2
就导入成功了。
6.2 Python-OpenCV基础
6.2.1 图像的表示
前面章节已经提到过了单通道的灰度图像在计算机中的表示,就是一个8位无符号整形的矩阵。在OpenCV的C++代码中,表示图像有个专门的结构叫做cv::Mat,不过在Python-OpenCV中,因为已经有了numpy这种强大的基础工具,所以这个矩阵就用numpy的array表示。如果是多通道情况,最常见的就是红绿蓝(RGB)三通道,则第一个维度是高度,第二个维度是高度,第三个维度是通道,比如图6-1a是一幅3×3图像在计算机中表示的例子:
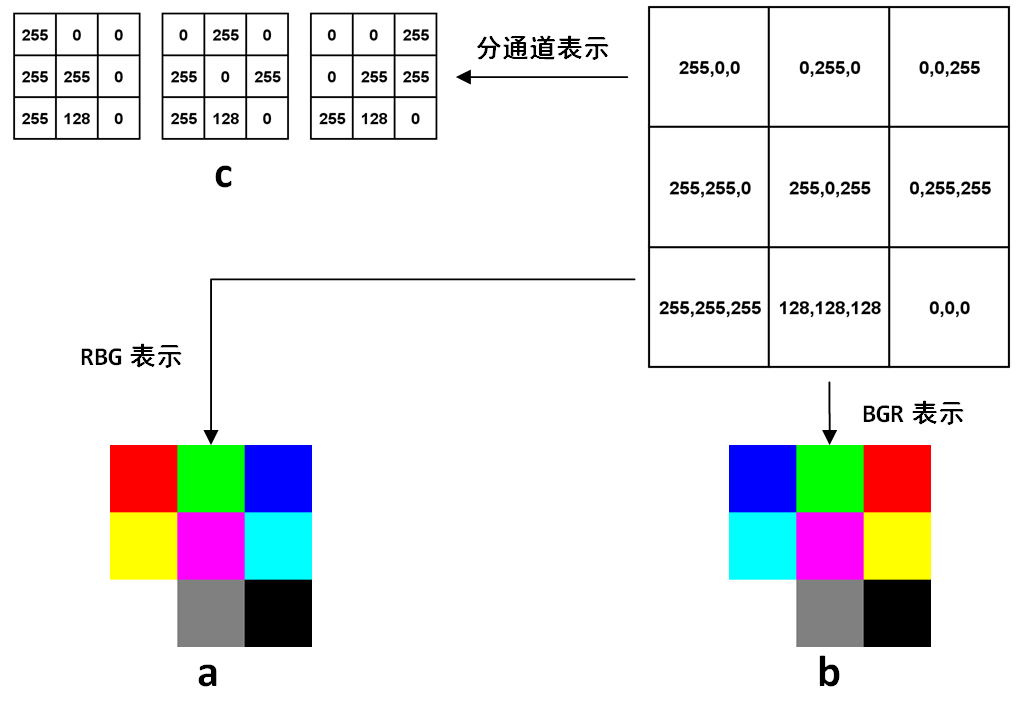
图6-1 RGB图像在计算机中表示的例子
图6-1中,右上角的矩阵里每个元素都是一个3维数组,分别代表这个像素上的三个通道的值。最常见的RGB通道中,第一个元素就是红色(Red)的值,第二个元素是绿色(Green)的值,第三个元素是蓝色(Blue),最终得到的图像如6-1a所示。RGB是最常见的情况,然而在OpenCV中,默认的图像的表示确实反过来的,也就是BGR,得到的图像是6-1b。可以看到,前两行的颜色顺序都交换了,最后一行是三个通道等值的灰度图,所以没有影响。至于OpenCV为什么不是人民群众喜闻乐见的RGB,这是历史遗留问题,在OpenCV刚开始研发的年代,BGR是相机设备厂商的主流表示方法,虽然后来RGB成了主流和默认,但是这个底层的顺序却保留下来了,事实上Windows下的最常见格式之一bmp,底层字节的存储顺序还是BGR。OpenCV的这个特殊之处还是需要注意的,比如在Python中,图像都是用numpy的array表示,但是同样的array在OpenCV中的显示效果和matplotlib中的显示效果就会不一样。下面的简单代码就可以生成两种表示方式下,图6-1中矩阵的对应的图像,生成图像后,放大看就能体会到区别:
import numpy as np
import cv2
import matplotlib.pyplot as plt
# 图6-1中的矩阵
img = np.array([
[[255, 0, 0], [0, 255, 0], [0, 0, 255]],
[[255, 255, 0], [255, 0, 255], [0, 255, 255]],
[[255, 255, 255], [128, 128, 128], [0, 0, 0]],
], dtype=np.uint8)
# 用matplotlib存储
plt.imsave('img_pyplot.jpg', img)
# 用OpenCV存储
cv2.imwrite('img_cv2.jpg', img)
不管是RGB还是BGR,都是高度×宽度×通道数,H×W×C的表达方式,而在深度学习中,因为要对不同通道应用卷积,所以用的是另一种方式:C×H×W,就是把每个通道都单独表达成一个二维矩阵,如图6-1c所示。
6.2.2 基本图像处理
存取图像
读图像用cv2.imread(),可以按照不同模式读取,一般最常用到的是读取单通道灰度图,或者直接默认读取多通道。存图像用cv2.imwrite(),注意存的时候是没有单通道这一说的,根据保存文件名的后缀和当前的array维度,OpenCV自动判断存的通道,另外压缩格式还可以指定存储质量,来看代码例子:
import cv2
# 读取一张400x600分辨率的图像
color_img = cv2.imread('test_400x600.jpg')
print(color_img.shape)
# 直接读取单通道
gray_img = cv2.imread('test_400x600.jpg', cv2.IMREAD_GRAYSCALE)
print(gray_img.shape)
# 把单通道图片保存后,再读取,仍然是3通道,相当于把单通道值复制到3个通道保存
cv2.imwrite('test_grayscale.jpg', gray_img)
reload_grayscale = cv2.imread('test_grayscale.jpg')
print(reload_grayscale.shape)
# cv2.IMWRITE_JPEG_QUALITY指定jpg质量,范围0到100,默认95,越高画质越好,文件越大
cv2.imwrite('test_imwrite.jpg', color_img, (cv2.IMWRITE_JPEG_QUALITY, 80))
# cv2.IMWRITE_PNG_COMPRESSION指定png质量,范围0到9,默认3,越高文件越小,画质越差
cv2.imwrite('test_imwrite.png', color_img, (cv2.IMWRITE_PNG_COMPRESSION, 5))
缩放,裁剪和补边
缩放通过cv2.resize()实现,裁剪则是利用array自身的下标截取实现,此外OpenCV还可以给图像补边,这样能对一幅图像的形状和感兴趣区域实现各种操作。下面的例子中读取一幅400×600分辨率的图片,并执行一些基础的操作:
import cv2
# 读取一张四川大录古藏寨的照片
img = cv2.imread('tiger_tibet_village.jpg')
# 缩放成200x200的方形图像
img_200x200 = cv2.resize(img, (200, 200))
# 不直接指定缩放后大小,通过fx和fy指定缩放比例,0.5则长宽都为原来一半
# 等效于img_200x300 = cv2.resize(img, (300, 200)),注意指定大小的格式是(宽度,高度)
# 插值方法默认是cv2.INTER_LINEAR,这里指定为最近邻插值
img_200x300 = cv2.resize(img, (0, 0), fx=0.5, fy=0.5,
interpolation=cv2.INTER_NEAREST)
# 在上张图片的基础上,上下各贴50像素的黑边,生成300x300的图像
img_300x300 = cv2.copyMakeBorder(img, 50, 50, 0, 0,
cv2.BORDER_CONSTANT,
value=(0, 0, 0))
# 对照片中树的部分进行剪裁
patch_tree = img[20:150, -180:-50]
cv2.imwrite('cropped_tree.jpg', patch_tree)
cv2.imwrite('resized_200x200.jpg', img_200x200)
cv2.imwrite('resized_200x300.jpg', img_200x300)
cv2.imwrite('bordered_300x300.jpg', img_300x300)
这些处理的效果见图6-2。
色调,明暗,直方图和Gamma曲线
除了区域,图像本身的属性操作也非常多,比如可以通过HSV空间对色调和明暗进行调节。HSV空间是由美国的图形学专家A. R. Smith提出的一种颜色空间,HSV分别是色调(Hue),饱和度(Saturation)和明度(Value)。在HSV空间中进行调节就避免了直接在RGB空间中调节是还需要考虑三个通道的相关性。OpenCV中H的取值是[0, 180),其他两个通道的取值都是[0, 256),下面例子接着上面例子代码,通过HSV空间对图像进行调整:
# 通过cv2.cvtColor把图像从BGR转换到HSV
img_hsv = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)
# H空间中,绿色比黄色的值高一点,所以给每个像素+15,黄色的树叶就会变绿
turn_green_hsv = img_hsv.copy()
turn_green_hsv[:, :, 0] = (turn_green_hsv[:, :, 0]+15) % 180
turn_green_img = cv2.cvtColor(turn_green_hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('turn_green.jpg', turn_green_img)
# 减小饱和度会让图像损失鲜艳,变得更灰
colorless_hsv = img_hsv.copy()
colorless_hsv[:, :, 1] = 0.5 * colorless_hsv[:, :, 1]
colorless_img = cv2.cvtColor(colorless_hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('colorless.jpg', colorless_img)
# 减小明度为原来一半
darker_hsv = img_hsv.copy()
darker_hsv[:, :, 2] = 0.5 * darker_hsv[:, :, 2]
darker_img = cv2.cvtColor(darker_hsv, cv2.COLOR_HSV2BGR)
cv2.imwrite('darker.jpg', darker_img)
无论是HSV还是RGB,我们都较难一眼就对像素中值的分布有细致的了解,这时候就需要直方图。如果直方图中的成分过于靠近0或者255,可能就出现了暗部细节不足或者亮部细节丢失的情况。比如图6-2中,背景里的暗部细节是非常弱的。这个时候,一个常用方法是考虑用Gamma变换来提升暗部细节。Gamma变换是矫正相机直接成像和人眼感受图像差别的一种常用手段,简单来说就是通过非线性变换让图像从对曝光强度的线性响应变得更接近人眼感受到的响应。具体的定义和实现,还是接着上面代码中读取的图片,执行计算直方图和Gamma变换的代码如下:
import numpy as np
# 分通道计算每个通道的直方图
hist_b = cv2.calcHist([img], [0], None, [256], [0, 256])
hist_g = cv2.calcHist([img], [1], None, [256], [0, 256])
hist_r = cv2.calcHist([img], [2], None, [256], [0, 256])
# 定义Gamma矫正的函数
def gamma_trans(img, gamma):
# 具体做法是先归一化到1,然后gamma作为指数值求出新的像素值再还原
gamma_table = [np.power(x/255.0, gamma)*255.0 for x in range(256)]
gamma_table = np.round(np.array(gamma_table)).astype(np.uint8)
# 实现这个映射用的是OpenCV的查表函数
return cv2.LUT(img, gamma_table)
# 执行Gamma矫正,小于1的值让暗部细节大量提升,同时亮部细节少量提升
img_corrected = gamma_trans(img, 0.5)
cv2.imwrite('gamma_corrected.jpg', img_corrected)
# 分通道计算Gamma矫正后的直方图
hist_b_corrected = cv2.calcHist([img_corrected], [0], None, [256], [0, 256])
hist_g_corrected = cv2.calcHist([img_corrected], [1], None, [256], [0, 256])
hist_r_corrected = cv2.calcHist([img_corrected], [2], None, [256], [0, 256])
# 将直方图进行可视化
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure()
pix_hists = [
[hist_b, hist_g, hist_r],
[hist_b_corrected, hist_g_corrected, hist_r_corrected]
]
pix_vals =