目录:
一、进程前戏
二、进程介绍
三、进程补充知识
四、线程
五、协程
一、进程前戏
1、 操作系统
核心CPU的调度 操作系统负责控制 调度 协调 管理 硬件(计算机硬件)资源 和软件资源(应用程序)
负责数据运算和逻辑运算
2、多道技术:a>>>>>IO>>>>
利用a 程序在执行IO时加载b 程序到内存
核心
1、空间上的复用 多个程序共用同一套计算机系统硬件
2、时间上的复用 在执行一个程序的IO时 加载另一个成序到内存空间 节省时间 特点 会保存上一次的IO的状态 回到就绪态》》》》排队再进入运行态》》》阻塞态
eg:比如我们在洗衣服的时间30 分钟内可以去做其他事 做饭 烧水 互不影响
(1)切换+保存切换时状态
什么时候才会切换
>>>1 当一个程序的执行过程遇到IO操作时 操作系统会剥夺程序的CPU的执行权限(切换+保存运行当前的状态)
>>>2 当一个程序长时间占用CPU 操作系统也会剥夺改程序的CPU的执行权限
优点:
提高了CPU的利用率,并且也不会影响程序的执行
单道技术:等待A程序全部执行完毕才会执行 下一个程序 实际上是 一个 同步
3、进程三态状态装换图
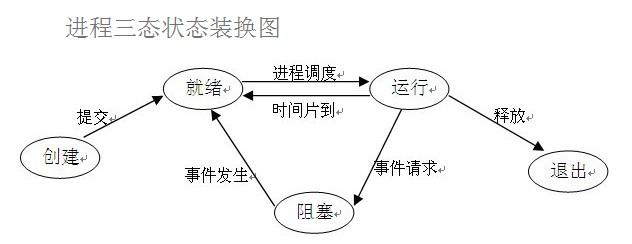
1 、程序在运行之后并不是直接进入运行态而是 在就绪态等待操作系统的调度 开始执行
2、阻塞态遇到IO操作 会进入阻塞态 如 input time.sleep print() 阻塞态结束 input time.sleep print 运行结束 并不是直接回到运行态的 而是 进入就绪态等待
操作系统的重新调用 开始执行 到之前切换的状态
3.运行结束释放 退出

4、进程调度(算法)
1、FCFS 先进先出
2、短作业优先调度算法
3、时间片轮法
二、进程
1、进程和程序
程序:一堆代码块
进程:正在运行的程序
2、如何创建进程
方法一
# 方法一函数的方法 import time from multiprocessing import Process def run(name): print('%s dancing' % name) time.sleep(2) print('%s dancing over' % name) if __name__ == '__main__': p = Process(target=run, args=('Lufei',)) # 产生一个进程对象 p.start() # 告诉操作系统帮你创一个进程 print('主进程') """ # windows创建进程会将代码以模块的方式 从上往下执行一遍 # linux会直接将代码完完整整的拷贝一份 # 创建进程就是内存中开辟一块内存空间 将允许产生的代码丢进去 一个进程对应在内存就是一块独立的内存空间 进程与进程间数是相互隔离的 无法直接的进行交互 但是可以通过某些技术实现简介交互 """
方法二
类继承
# 类继承 import time from multiprocessing import Process class Myprocess(Process): def __init__(self,name): super().__init__() # 继承父类进程名称空间 self.name = name def run(self): print('%s is dancing' % self.name) time.sleep(2) print('%s is over' % self.name) if __name__ == '__main__': p = Myprocess('jason') # 类继承的方法 继承Process 的属性 调用super().__init__() 重写自己的名称空间 p.start() # 告诉操作系统帮你创建一个进程 print('主进程')
3、进程的join 的方法
# 控制子所有子进程的结束才会结束主进程。。。如果不加的话主进程一结束所有的子进程也会随之结束,不合理啊有些子进程都没有运行
# 如何使用
# 创建多个进程 所有的代码都会复制一份 # join 的先让 所有自尅执行完毕才会执行 主进程 from multiprocessing import Process import time def run(name,i): print("%s is dancing" % name) time.sleep(i) print('%s is over' % name) if __name__ == '__main__': p_list = [] for i in range(5): p = Process(target=run, args=('第一号%s子进程 '%i,i)) p.start() p_list.append(p) for p in p_list: p.join() # 等待子进程运行完毕 内部机制 print('主进程')
原始版本 不加for 循环
# 创建多个进程 # join 的先让 所有自尅执行完毕才会执行 主进程 from multiprocessing import Process import time def run(name,i): print("%s is dancing" % name) time.sleep(i) print('%s is over' % name) if __name__ == '__main__': # p_list = [] # for i in range(5): # p = Process(target=run, args=('第一号%s子进程 '%i,i)) # p.start() # 让操作系统帮我们创建进程 # p_list.append(p) # for p in p_list: # p.join() # 等待子进程运行完毕 内部机制 # print('主进程') # 原始状态 p = Process(target=run, args=('jsaon',1)) p1 = Process(target=run, args=('tank',2)) p2 = Process(target=run, args=('egon',3)) p3 = Process(target=run, args=('mmm',4)) p.start() p1.start() p2.start() p3.start() p.join() p1.join() p2.join() p3.join() print('主进程')
4、进程间的数据是否可以通用?代码验证
# 进程间的数据是不能直接获取的 from multiprocessing import Process num = 99 # 可变数据类型是不需要进行全局的 def run(): global num # global 是将局部修改全局 num = 100 # print(num) # if __name__ == '__main__': p = Process(target=run, args=()) # 没有参数的话是可以不写 p.start() # 让操作系统帮我们创建一个进程 p.join() print(num) # 99
5、进程对象及其它方法
子进程的pid号和父进程的pid 好的 查询方法
僵尸进程和孤儿进程
6、守护进程
7、互斥锁(*****)
# 开多进程会将
import json import time from multiprocessing import Process, Lock # 进程互斥锁 """;操作同一份数据会造成数据的错乱 所以需要加锁 1.代码由并行变成了串行虽然牺牲了效率 降低的这执行效率到但是保证了数据的安全性 """ # def check(i): with open('data', 'r', encoding='utf-8')as f: # 获取数据 res = f.read() my_dic = json.loads(res) print('%s用户查询的火车票为%s' % (i, my_dic.get('ticket'))) # 买之前还得再获取数据的 def buy(i): # with open('data', 'r', encoding='utf-8')as f: res = f.read() my_dic = json.loads(res) time.sleep(2) if my_dic['ticket'] > 0: my_dic['ticket'] -= 1 with open('data', 'w', encoding='utf-8')as f: json.dump(my_dic, f) print('%s用户买票成功' % i) else: print('没有票了') def run(i, mutex): check(i) # 枪锁 mutex.acquire() # 枪锁 buy(i) # 释放锁 mutex.release() # 释放锁 if __name__ == '__main__': # 创建进程 # 将锁放在主进程中 mutex = Lock() # 生成一把锁 for i in range(10): p = Process(target=run, args=((i, mutex))) p.start() 7用户查询的火车票为2 5用户查询的火车票为2 0用户查询的火车票为2 1用户查询的火车票为2 4用户查询的火车票为2 6用户查询的火车票为2 3用户查询的火车票为2 2用户查询的火车票为2 8用户查询的火车票为2 9用户查询的火车票为2 7用户买票成功 5用户买票成功 没有票了 没有票了 没有票了 没有票了 没有票了 没有票了 没有票了 没有票了
作业:FTP上传文件
需求:
1 用户认证加密
2 允许同时多个用户登录
3 每个用户都有自己的家目录(home),并且只能访问自己的home 目录
允许访问自己的家目录
4 允许用户在FTPserver 上随意切换目录
5 允许传输过程中显示进度条
6 附加功能 支持文件的端点的端点续传
三、进程补充
1、进程间的相互通信 间接 通过Quueue 实现
队列可以实现通讯的本质 利用Qqueue 在一个进程中存 q.put() 的所有变量 存放到队列中的名称空间中
可以在另一个进程中通过q.get() 获取 另一个进程的值 就相当于一个链接 进程之间的通道
也可以比作一座桥梁
2.
Pipe(管道)
The Pipe() function returns a pair of connection objects connected by a pipe which by default is duplex (two-way).
# 简单版本的进程间相互通信是类简介通信的 import os import time from multiprocessing import Process, Queue # q = Queue(5) # q.put(1) # q.put(2) # q.put(3) # # print(q.full()) # q.put(4) # # q.put(5) # # print(q.full()) # # # # 取值 # q.get() # q.get() # q.get() # q.get() # print(q.get_nowait()) # print(q.empty()) # # print(q.get_nowait()) # # # print(q.get()) # q.get() 如果没有取到值则会一致等 # # print(q.empty()) # # """ # # """
2、进程间通过Queue进行通信的代码
实现过程:
money = 6666 def task(q): global money money = 9999 q.put('Hello i love') def consumer(q): print(q.get(),'haha') if __name__ == '__main__': q1 = Queue() p = Process(target=task, args=(q1,)) c = Process(target=consumer,args=(q1,)) c.start() p.start() p.join() # 等待所有的子进程结束才结束 # print(money) print(q1.get(),'luelie') #
2.PIpe进程实现通信
from multiprocessing import Process, Pipe def f(conn): conn.send('11') conn.send('22') print("from parent:",conn.recv()) print("from parent:", conn.recv()) conn.close() if __name__ == '__main__': parent_conn, child_conn = Pipe() #生成管道实例,可以互相send()和recv() p = Process(target=f, args=(child_conn,)) p.start() print(parent_conn.recv()) # prints "11" print(parent_conn.recv()) # prints "22" parent_conn.send("33") # parent 发消息给 child parent_conn.send("44") p.join() Pipe
3.Manage
进程之间是相互独立的 ,Queue和pipe只是实现了数据交互,并没实现数据共享,Manager可以实现进程间数据共享 。
Manager还支持进程中的很多操作 , 比如Condition , Lock , Namespace , Queue , RLock , Semaphore等
from multiprocessing import Process, Manager import os def f(d, l): d[os.getpid()] =os.getpid() l.append(os.getpid()) print(l) if __name__ == '__main__': with Manager() as manager: d = manager.dict() #{} #生成一个字典,可在多个进程间共享和传递 l = manager.list(range(5)) #生成一个列表,可在多个进程间共享和传递 p_list = [] for i in range(2): p = Process(target=f, args=(d, l)) p.start() p_list.append(p) for res in p_list: #等待结果 res.join() print(d) print(l)
4、进程中的IPC机制
生产者和消费者模型
#
"""
生产者消费者模型
1.生产者:生产制造数据的
2、消费者:消费处理数据的
应用场景:解决生产与消费的供需不平衡的问题
供==求
列子:
···老王 开了一家面馆10碗面 老二 开了包子10个包子铺>>>>> 生产者
···小明 小红 吃面和包子
"""
def producer(name, food, q): for i in range(10): data = '%s生产的%s 个数:%d' % (name, food,i) # 生产需要时间的所以 # time.sleep(random.random()) time.sleep(random.random()) q.put(data) print(data) def consumer(name, q): # 消费者 while True: data = q.get() # print(data) # if data == None: # q.task_done() 其实已经帮我们处理完毕所有的数值 # break print("%s吃了%s"%(name,data)) time.sleep(random.random()) q.task_done() # 告诉队列你已经从你的队列中取出一个值并且已经处理完毕 if __name__ == '__main__': # 创建进程可等待队列 q = JoinableQueue() p1 = Process(target=producer, args=('大厨San', '包子', q)) p2 = Process(target=producer, args=('二厨tank', '生蚝', q)) p1.start() p2.start() c1 = Process(target=consumer, args=('吃货lufei', q)) c2 = Process(target=consumer, args=('吃货Nami', q)) # 守护进程 c1 c2 等待 运行完毕 运行主进程结束程序 c1.daemon = True c2.daemon = True c1.start() # 让操作系统帮我们创建一个消费者进程 c2.start() # 让是生产进程全部执行完毕 才走 消费 进程 p1.join() p2.join() # print('zhu') q.join() # 等待队列中的所有值取完
5.进程池
pass
四、线程和进程的关系
#
"""
进程:进程是资源单位,每个进程下面自带了一个线程
线程:是正真运行代码的执行单位
并发:单核下是一个进程下的多个线程进行IO切换
eg: 进程好比一个工厂 线程是里面的一条条流水线
"""
1 主进程,父进程和子进程之间的关系 父子进程之间的定义:当一个进程创建一个或多个子进程时,那么这个进程可以称之这些进程的父进程, 他们之间是父子关系,也可以说是继承关系,子进程会继承父进程的属性。 进程是一个资源单位,在进程创建的过程,系统会自动为其开辟一块独立的内存空间。因此,在子进程的创建的过程中,系统会自动为其开辟一块独立的内存空间 ,并且会将父进程的代码拷贝到这个内存空间中。 一般来说,主进程默认是最初始的父进程。 所以在Python中创建子进程的过程中为了避免无限递归主进程的问题,必须将创建子进程的代码放在if name == ‘__main__’下面 2 主线程,父线程和子线程之间的关系 父线程和子线程之间的关系类似与主进程和子进程之间的关系,但是在线程的创建过程中并不需要开辟内存空间吗,而且线程与线程之间是没有主次之分的,他们共享同一块内存资源。每一个进程都自带一个线程, 这个线程称之为主线程。一般来说,主线程不会是父线程,他与子线程是同等地位的,这一点与进程有很大的不同。主线程创建的子线程只会去执行主线程交给他的任务,不会去执行子线程的创建任务,所以在线程的创建的过程不需要加if判断。 注意:如果子线程执行的是函数任务,函数的加载并不会在子线程中创建,他只是去执行这个函数体代码,而不会去执行创建过程,创建过程在主线程中完成。
2、创建线程的两种方法
· 1、函数的方法
# def producer(name): # print('%s is runing'% name) # time.sleep(1) # print('%s is over'% name) # # # def consumer(name): # print('%s is runing '% name) # time.sleep(1) # print('% is over'% name) # # # # 线程可以不用在双下__main__ # t1 = Thread(target=producer, args=('san',)) # # t2 = Thread(target=producer, args=('Nami',)) # t1.start() # 创建线程的资源开支小于 进程 时间消耗也小于进程 不需要开辟内存空间 # t2.start() # 所以执行创建线程 # print('主线程')
2、类继承创建线程
# 类继承 class MyThread(Thread): def __init__(self, name): # super().__init__() self.name = name def task(self): print('%s is running' % self.name) time.sleep(1) print('%s is over' % self.name) # if __name__ == '__main__': t1 = MyThread('San') t1.task() t1.start() t1.join() print('主线程', os.getpid()) # # # 创建多个线程 def task1(i): print('%s is running' % i) time.sleep(1) print('%s is over' % i) # print('主线程1', os.getppid()) # 主线程1 32092 # print('子线程', os.getpid()) # 子线程 38928 for i in range(6): t = Thread(target=task1, args=(i,)) t.daemon = True t.start() # print('主线程2', os.getpid()) # 主线程2 38928 # print('主主',os.getppid()) # 主主 32092 #
小结:
"""
主线程的结束也就意味进程的结束
主线程必须等待其他非守护线程的结束才能结束
(意味子线程云运行的时候需要使用进程中的资源,而主线程一旦结束资源也就销毁了)
"""
3、线程中的是可以进行相互通信的 因为同一进程下的线程是可以共用进程的所有资源单位的
from threading import Thread money = 6666 def task(): global money money = 9999 t = Thread(target=task) t.start() t.join() print(money)
4、线程中的互斥锁 当多个线程对同一份数据进行操作的时候 会造成数据的错乱 所以需要进行加锁 虽然牺牲了效率 但保证数据的安全
# 多个线程对同一份数据的操作 会造成数据的错乱 # 需要加锁 保障数据的安全 import time from threading import Thread,Lock num = 100 def task(mutex): # print('%s is running' % i) # time.sleep(2) # print('%s is over '% i) global num mutex.acquire() # 加到要操作的数据上 temp = num time.sleep(0.01) num = temp-1 mutex.release() # 操作完毕进行释放锁
t_list = [] mutex = Lock() # 加锁的位置 for i in range(100): t = Thread(target=task, args=(mutex,)) t.start() t_list.append(t) for t in t_list: t.join() print(num) # 多个线程在操作同一份的数据的时候 会造成数据的错乱的 所以需要对我们的操作的数据加锁 #
五、协程
1.简介
协程(Coroutine) : 是单线程下的并发 , 又称微线程 , 纤程 . 协程是一种用户态的轻量级线程 , 即协程有用户自己控制调度
协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。
协程能保留上一次调用时的状态(即所有局部状态的一个特定组合),每次过程重入时,就相当于进入上一次调用的状态
使用协程的优缺点
优点 :
- 协程的切换开销更小 , 属于程序级别的切换 , 更加轻量级
- 单线程内就可以实现并发的效果 , 最大限度利用CPU
缺点 :
- 协程的本质是单线程下 , 无法利用多核 , 可以是一个程序开启多个进程 , 每个进程内开启多个线程 , 每个线程内开启协程
- 协程指的是单个线程 , 因而一旦协程出现阻塞 将会阻塞整个线程
2.Greenlet
greenlet是一个用C实现的协程模块,相比与python自带的yield,它可以使你在任意函数之间随意切换,而不需把这个函数先声明为generator
· greenlet
为了更好使用协程来完成多任务,python中greenlet模块对其封装,从而使得切换任务变得更加简单
安装方式
pip install greenlet
from greenlet import greenlet def test1(): print(12) gr2.switch() #到这里切换到gr2,执行test2() print(34) gr2.switch() #切换到上次gr2运行的位置 def test2(): print(56) gr1.switch() #切换到上次gr1运行的位置 print(78) gr1 = greenlet(test1) #启动一个协程gr1 gr2 = greenlet(test2) #启动一个协程gr2 gr1.switch() #开始运行gr1 greenlet
3、gevent
greenlet已经实现了协程,但是这个工人切换,是不是觉得太麻烦了,不要着急,python还有一个比greenlet更强大的并且能够自动切换任务的模块`gevent`
其原理是当一个greentlet遇到IO(指的是input ouput输入输出,比如网络、文件操作等)操作时,比如访问网络,就自动切换到其他的greenlet,等到IO完成,再适当的时候切换回来继续执行。
由于IO操作非常耗时,经常使程序处于等待状态,有了gevent我们自动切换协程,就保证总有greenlet在运行,而不是等待IO


Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。
由于切换是在IO操作时自动完成,所以gevent需要修改Python自带的一些标准库,这一过程在启动时通过monkey patch完成:
安装:
pip install gevent
import gevent def f(n): for i in range(n): print(gevent.getcurrent(), i) # 用来模拟一个耗时操作,注意不是time模块中的sleep gevent.sleep(1) g1 = gevent.spawn(f, 5) g2 = gevent.spawn(f, 5) g3 = gevent.spawn(f, 5) g1.join() g2.join() g3.join()