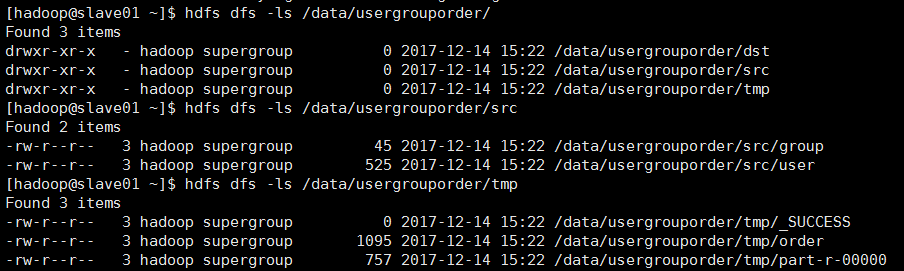
将user表、group表、order表关;(类似于多表关联查询)
测试准备:
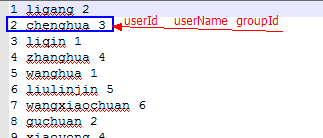
首先同步时间,然后 开启hdfs集群,开启yarn集群;在本地"/home/hadoop/test/"目录创建user表、group表、order表的文件;
user文件:
group文件:
order文件:
测试目标:
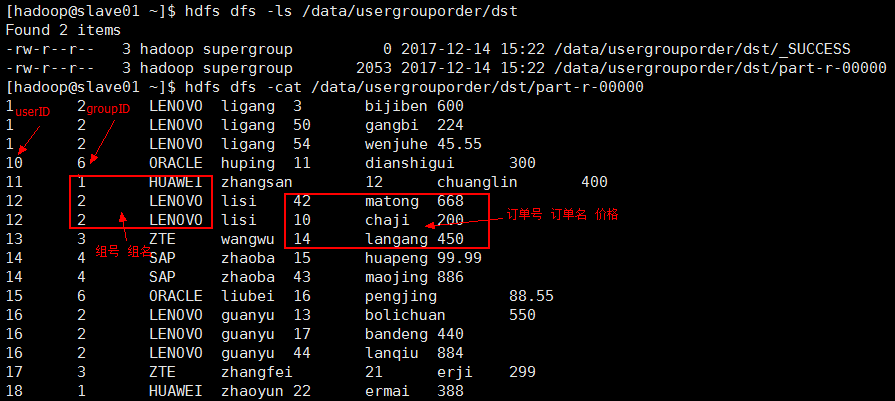
得到3张表关联后的结果;
测试代码:
一定要把握好输出键值的类型,否则有可能造成有输出目录,但是没有文件内容的问题;


package com.mmzs.bigdata.yarn.mapreduce; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class UserGroupMapper01 extends Mapper<LongWritable, Text, Text, Text> { private Text outKey; private Text outValue; @Override protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { outKey = new Text(); outValue = new Text(); } @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { FileSplit fp = (FileSplit) context.getInputSplit(); String fileName = fp.getPath().getName(); String line = value.toString(); String[] fields = line.split("\s+"); String keyStr = null; String valueStr = null; if ("group".equalsIgnoreCase(fileName)) { keyStr = fields[0]; valueStr = new StringBuilder(fields[1]).append("-->").append(fileName).toString(); } else { keyStr = fields[2]; //加“-->”;后以此标识符作为分割符,进行文件区分 valueStr = new StringBuilder(fields[0]).append(" ").append(fields[1]).append("-->").append(fileName).toString(); } outKey.set(keyStr); outValue.set(valueStr); context.write(outKey, outValue); } @Override protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { outKey = null; outValue = null; } }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.List; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Reducer; 9 10 public class UserGroupReducer01 extends Reducer<Text, Text, Text, Text> { 11 12 private Text outValue; 13 14 @Override 15 protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { 16 outValue = new Text(); 17 } 18 19 @Override 20 protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) 21 throws IOException, InterruptedException { 22 Iterator<Text> its = values.iterator(); 23 24 String masterRecord = null; 25 List<String> slaveRecords = new ArrayList<String>(); 26 27 //拆分出主表记录和从表记录 28 while (its.hasNext()) { 29 String[] rowAndFileName = its.next().toString().split("-->"); 30 if (rowAndFileName[1].equalsIgnoreCase("group")) { 31 masterRecord = rowAndFileName[0]; 32 continue; 33 } 34 slaveRecords.add(rowAndFileName[0]); 35 } 36 37 for (String slaveRecord : slaveRecords) { 38 String valueStr = new StringBuilder(masterRecord).append(" ").append(slaveRecord).toString(); 39 outValue.set(valueStr); 40 context.write(key, outValue); 41 } 42 43 } 44 45 @Override 46 protected void cleanup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { 47 outValue = null; 48 } 49 50 51 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.io.LongWritable; 11 import org.apache.hadoop.io.Text; 12 import org.apache.hadoop.mapreduce.Job; 13 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 14 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 15 16 /** 17 * @author hadoop 18 * 19 */ 20 public class UserGroupDriver01 { 21 22 private static FileSystem fs; 23 private static Configuration conf; 24 static { 25 String uri = "hdfs://master01:9000/"; 26 conf = new Configuration(); 27 try { 28 fs = FileSystem.get(new URI(uri), conf, "hadoop"); 29 } catch (IOException e) { 30 e.printStackTrace(); 31 } catch (InterruptedException e) { 32 e.printStackTrace(); 33 } catch (URISyntaxException e) { 34 e.printStackTrace(); 35 } 36 } 37 38 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 39 40 Job ugJob01 = getJob(args); 41 if (null == ugJob01) { 42 return; 43 } 44 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 45 boolean flag = false; 46 flag = ugJob01.waitForCompletion(true); 47 System.exit(flag?0:1); 48 } 49 50 /** 51 * 获取Job实例 52 * @param args 53 * @return 54 * @throws IOException 55 */ 56 public static Job getJob(String[] args) throws IOException { 57 if (null==args || args.length<2) return null; 58 //放置需要处理的数据所在的HDFS路径 59 Path inputPath = new Path(args[0]); 60 //放置Job作业执行完成之后其处理结果的输出路径 61 Path outputPath = new Path(args[1]); 62 //主机文件路径 63 Path userPath = new Path("/home/hadoop/test/user"); 64 Path groupPath = new Path("/home/hadoop/test/group"); 65 66 //如果输入的集群路径存在,则删除 67 if (fs.exists(inputPath)) { 68 fs.delete(inputPath, true);//true表示递归删除 69 } 70 if (fs.exists(outputPath)) { 71 fs.delete(outputPath, true);//true表示递归删除 72 } 73 74 //创建并且将数据文件拷贝到创建的集群路径 75 fs.mkdirs(inputPath); 76 fs.copyFromLocalFile(false, false, new Path[]{userPath, groupPath}, inputPath); 77 78 79 //获取Job实例 80 Job ugJob01 = Job.getInstance(conf, "UserGroupJob01"); 81 //设置运行此jar包入口类 82 //ugJob01的入口是WordCountDriver类 83 ugJob01.setJarByClass(UserGroupDriver01.class); 84 //设置Job调用的Mapper类 85 ugJob01.setMapperClass(UserGroupMapper01.class); 86 //设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句) 87 ugJob01.setReducerClass(UserGroupReducer01.class); 88 89 //设置MapTask的输出键类型 90 ugJob01.setMapOutputKeyClass(Text.class); 91 //设置MapTask的输出值类型 92 ugJob01.setMapOutputValueClass(Text.class); 93 94 //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句) 95 ugJob01.setOutputKeyClass(Text.class); 96 //设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句) 97 ugJob01.setOutputValueClass(Text.class); 98 99 //设置整个Job需要处理数据的输入路径 100 FileInputFormat.setInputPaths(ugJob01, inputPath); 101 //设置整个Job计算结果的输出路径 102 FileOutputFormat.setOutputPath(ugJob01, outputPath); 103 104 return ugJob01; 105 } 106 107 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 5 import org.apache.hadoop.io.LongWritable; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Mapper; 8 import org.apache.hadoop.mapreduce.lib.input.FileSplit; 9 10 public class UserGroupMapper02 extends Mapper<LongWritable, Text, Text, Text> { 11 12 private Text outKey; 13 private Text outValue; 14 15 @Override 16 protected void setup(Mapper<LongWritable, Text, Text, Text>.Context context) 17 throws IOException, InterruptedException { 18 outKey = new Text(); 19 outValue = new Text(); 20 } 21 22 @Override 23 protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) 24 throws IOException, InterruptedException { 25 FileSplit fp = (FileSplit) context.getInputSplit(); 26 String fileName = fp.getPath().getName(); 27 28 String line = value.toString(); 29 String[] fields = line.split("\s+"); 30 31 String keyStr = fields[2]; 32 String valueStr = null; 33 valueStr = new StringBuilder(fields[0]).append(" ").append(fields[1]).append(" ").append(fields[3]).append("-->").append(fileName).toString(); 34 35 outKey.set(keyStr); 36 outValue.set(valueStr); 37 context.write(outKey, outValue); 38 39 40 } 41 42 @Override 43 protected void cleanup(Mapper<LongWritable, Text, Text, Text>.Context context) 44 throws IOException, InterruptedException { 45 outKey = null; 46 outValue = null; 47 } 48 49 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.util.ArrayList; 5 import java.util.Iterator; 6 import java.util.List; 7 8 import org.apache.hadoop.io.Text; 9 import org.apache.hadoop.mapreduce.Reducer; 10 11 public class UserGroupReducer02 extends Reducer<Text, Text, Text, Text> { 12 13 private Text outValue; 14 15 @Override 16 protected void setup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { 17 outValue = new Text(); 18 } 19 20 @Override 21 protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) 22 throws IOException, InterruptedException { 23 String masterRecord = null; 24 List<String> slaveRecords = new ArrayList<String>(); 25 26 //拆分出主表记录和从表记录 27 Iterator<Text> its = values.iterator(); 28 while (its.hasNext()) { 29 String[] rowAndFileName = its.next().toString().split("-->"); 30 if (!rowAndFileName[1].equalsIgnoreCase("order")) { 31 masterRecord = rowAndFileName[0]; 32 continue; 33 } 34 slaveRecords.add(rowAndFileName[0]); 35 } 36 37 for (String slaveRecord : slaveRecords) { 38 String valueStr = new StringBuilder(masterRecord).append(" ").append(slaveRecord).toString(); 39 outValue.set(valueStr); 40 context.write(key, outValue); 41 } 42 43 } 44 45 @Override 46 protected void cleanup(Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { 47 outValue = null; 48 } 49 50 51 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 import org.apache.hadoop.conf.Configuration; 7 import org.apache.hadoop.fs.FileSystem; 8 import org.apache.hadoop.fs.Path; 9 import org.apache.hadoop.io.Text; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 13 14 /** 15 * @author hadoop 16 * 17 */ 18 public class UserGroupDriver02 { 19 20 private static FileSystem fs; 21 private static Configuration conf; 22 static { 23 String uri = "hdfs://master01:9000/"; 24 conf = new Configuration(); 25 try { 26 fs = FileSystem.get(new URI(uri), conf, "hadoop"); 27 } catch (IOException e) { 28 e.printStackTrace(); 29 } catch (InterruptedException e) { 30 e.printStackTrace(); 31 } catch (URISyntaxException e) { 32 e.printStackTrace(); 33 } 34 } 35 36 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 37 38 Job ugJob02 = getJob(new String[] {args[1], args[2]}); 39 if (null == ugJob02) { 40 return; 41 } 42 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 43 boolean flag = false; 44 flag = ugJob02.waitForCompletion(true); 45 System.exit(flag?0:1); 46 } 47 48 /** 49 * 获取Job实例 50 * @param args 51 * @return 52 * @throws IOException 53 */ 54 public static Job getJob(String[] args) throws IOException { 55 if (null==args || args.length<2) return null; 56 //放置需要处理的数据所在的HDFS路径 57 Path inputPath = new Path(args[1]); 58 //放置Job作业执行完成之后其处理结果的输出路径 59 Path outputPath = new Path(args[2]); 60 //主机文件路径 61 Path orderPath = new Path("/home/hadoop/test/order"); 62 63 //输入的集群路径存在,在第一次已创建 64 if (!fs.exists(inputPath)) return null; 65 if (fs.exists(outputPath)) { 66 fs.delete(outputPath, true);//true表示递归删除 67 } 68 69 //将数据文件拷贝到创建的集群路径 70 fs.copyFromLocalFile(false, false, orderPath, inputPath); 71 72 73 //获取Job实例 74 Job ugJob02 = Job.getInstance(conf, "UserGroupJob02"); 75 //设置运行此jar包入口类 76 //ugJob02的入口是WordCountDriver类 77 ugJob02.setJarByClass(UserGroupDriver02.class); 78 //设置Job调用的Mapper类 79 ugJob02.setMapperClass(UserGroupMapper02.class); 80 //设置Job调用的Reducer类(如果一个Job没有Reducer则可以不调用此条语句) 81 ugJob02.setReducerClass(UserGroupReducer02.class); 82 83 //设置MapTask的输出键类型 84 ugJob02.setMapOutputKeyClass(Text.class); 85 //设置MapTask的输出值类型 86 ugJob02.setMapOutputValueClass(Text.class); 87 88 //设置整个Job的输出键类型(如果一个Job没有Reducer则可以不调用此条语句) 89 ugJob02.setOutputKeyClass(Text.class); 90 //设置整个Job的输出值类型(如果一个Job没有Reducer则可以不调用此条语句) 91 ugJob02.setOutputValueClass(Text.class); 92 93 //设置整个Job需要处理数据的输入路径 94 FileInputFormat.setInputPaths(ugJob02, inputPath); 95 //设置整个Job计算结果的输出路径 96 FileOutputFormat.setOutputPath(ugJob02, outputPath); 97 98 return ugJob02; 99 } 100 101 }
1 package com.mmzs.bigdata.yarn.mapreduce; 2 3 import java.io.IOException; 4 import java.net.URI; 5 import java.net.URISyntaxException; 6 7 import org.apache.hadoop.conf.Configuration; 8 import org.apache.hadoop.fs.FileSystem; 9 import org.apache.hadoop.fs.Path; 10 import org.apache.hadoop.mapreduce.Job; 11 12 public class UserGroupDriver { 13 14 private static FileSystem fs; 15 private static Configuration conf; 16 private static final String TEMP= "hdfs://master01:9000/data/usergrouporder/tmp"; 17 static { 18 String uri = "hdfs://master01:9000/"; 19 conf = new Configuration(); 20 try { 21 fs = FileSystem.get(new URI(uri), conf, "hadoop"); 22 } catch (IOException e) { 23 e.printStackTrace(); 24 } catch (InterruptedException e) { 25 e.printStackTrace(); 26 } catch (URISyntaxException e) { 27 e.printStackTrace(); 28 } 29 } 30 31 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 32 33 String[] params = {args[0], TEMP, args[1]}; 34 35 //运行第1个Job 36 Job ugJob01 = UserGroupDriver01.getJob(params); 37 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 38 boolean flag01 = ugJob01.waitForCompletion(true); 39 if (!flag01) { 40 System.out.println("job2 running failure......"); 41 System.exit(1); 42 } 43 44 //运行第2个Job 45 Job ugJob02 = UserGroupDriver02.getJob(params); 46 //提交Job到集群并等待Job运行完成,参数true表示将Job运行时的状态信息返回到客户端 47 boolean flag02 = ugJob02.waitForCompletion(true); 48 if (flag02) {//等待Job02完成后就删掉中间目录并退出; 49 // fs.delete(new Path(TEMP), true); 50 System.out.println("job2 running success......"); 51 System.exit(0); 52 } 53 System.out.println("job2 running failure......"); 54 System.exit(1); 55 } 56 57 }
为了更好的测试,可以先屏蔽删除中间输出结果的语句;
//总Driver String[] params = {args[0], TEMP, args[1]}; //运行第1个Job Job ugJob01 = UserGroupDriver01.getJob(params); //运行第2个Job Job ugJob02 = UserGroupDriver02.getJob(params); //分Driver01
//放置需要处理的数据所在的HDFS路径 Path inputPath = new Path(args[0]);//params中的args[0] //放置Job作业执行完成之后其处理结果的输出路径 Path outputPath = new Path(args[1]);//params中的TEMP //分Driver02 //params中的TEMP和args[2]//放置需要处理的数据所在的HDFS路径 Path inputPath = new Path(args[1]); //放置Job作业执行完成之后其处理结果的输出路径 Path outputPath = new Path(args[2]);
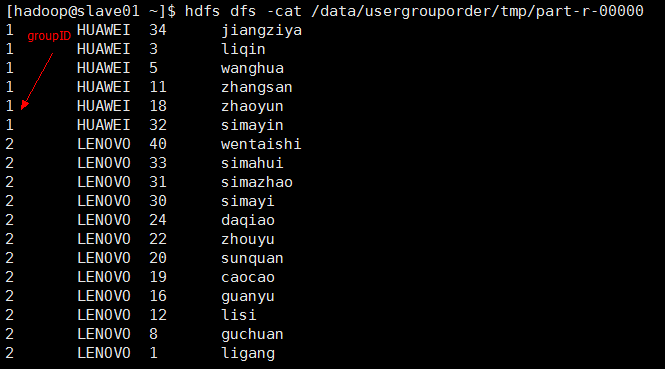
测试结果:
运行时传入参数是:
如果在eclipse上运行:传参需要加上集群的master的uri即 hdfs://master01:9000
输入路径参数: /data/usergrouporder/src
输出路径参数: /data/usergrouporder/dst