深浅拷贝:参考:http://www.cnblogs.com/yuanchenqi/articles/5782764.html
s = [[1, 2], 'lily', 'hello'] s2 = s.copy() print(s2) s2[0][1] = 3 print(s2) print(s) # >>> [[1, 2], 'lily', 'hello'] # >>> [[1, 3], 'lily', 'hello'] # >>> [[1, 3], 'lily', 'hello'] # 输出结果显示当改变列表内的元素的时候,两个会一起改变
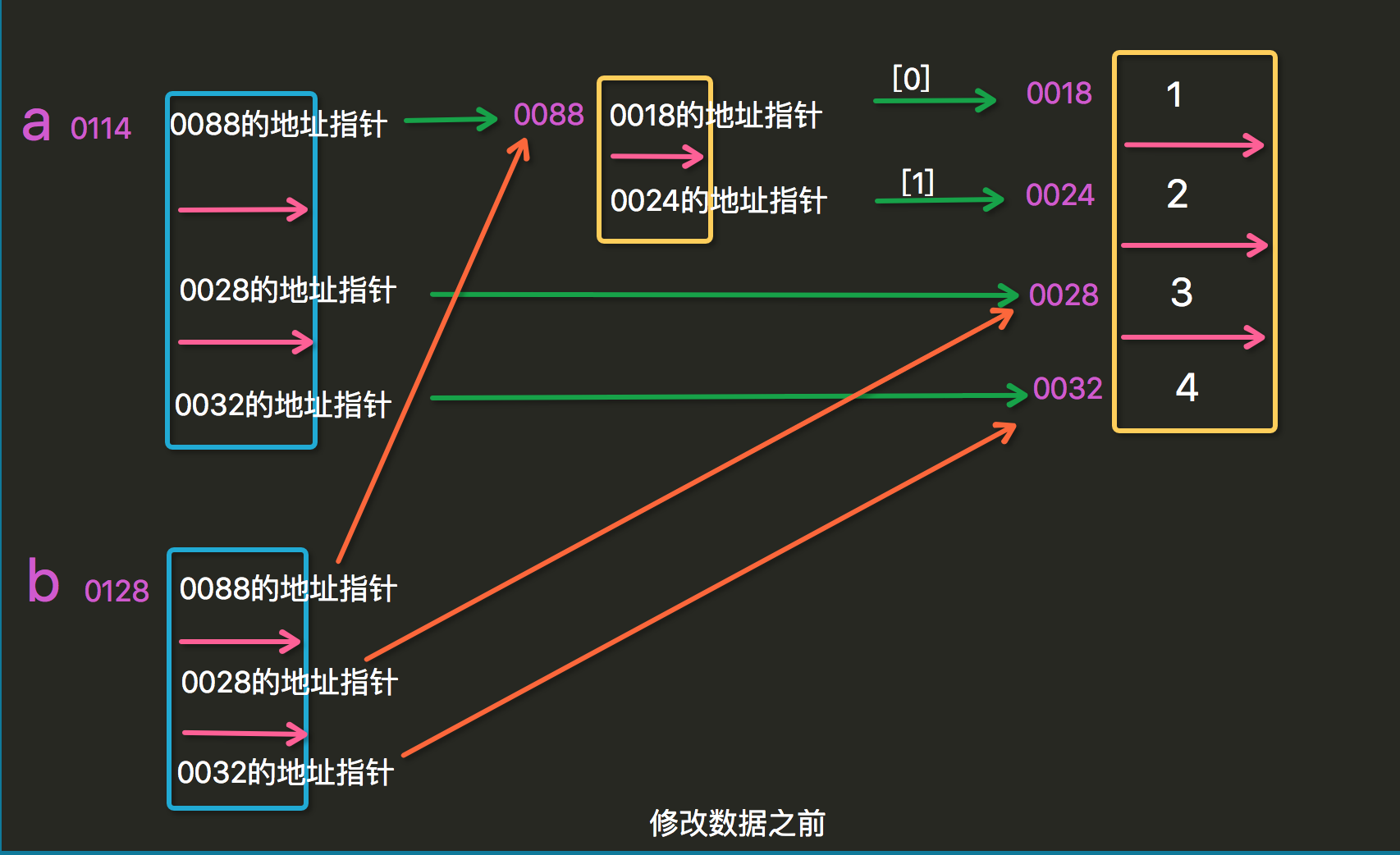
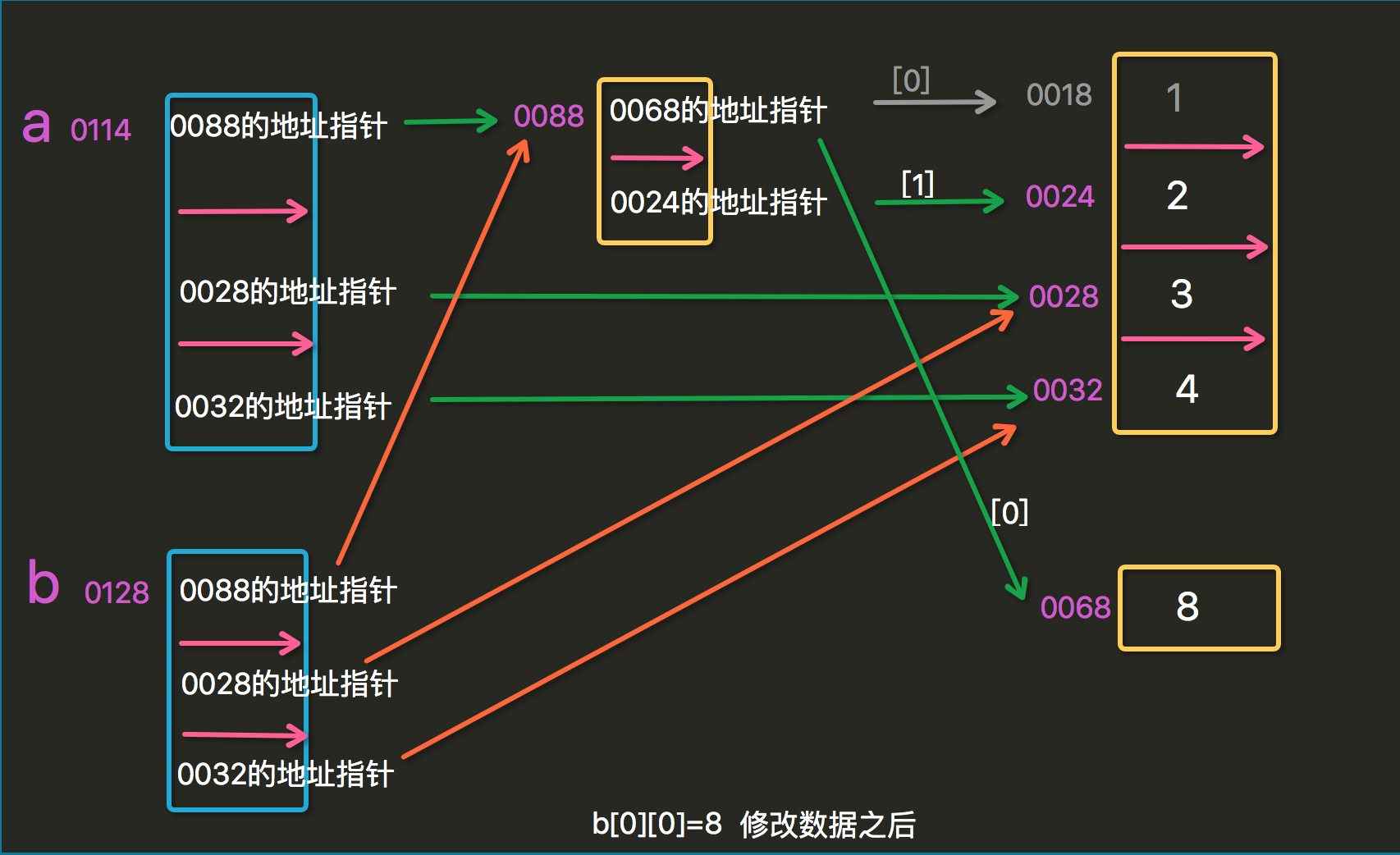
s2 = s 和 s2 = s.copy 是不一样的。
s2 = s:是将 s 整体的一个内存地址直接复制给了 s2,相当于 s2 是 s 的一个别名,两个都指向同一块内存空间
s2 = s.copy:是将s 内的每一份地址都拷贝了一份给 s2
浅拷贝:只拷贝一层,不拷贝第二层
深拷贝:克隆一份,和原来完全没关系 s2 = copy.deepcopy(s)
set:
- 集合的创建,只有一种方式:s = set(‘lily’) ;每个字符为 1 个单独的元素,重复的只保留一个
- 集合对象是一组无序排列的可哈希的值,集合成员可以做字典的键
- set 是无序不重复的,没有索引。
- 集合分类:可变集合(set) 和 不可变集合(frozenset)
可变集合:可添加和删除元素,非可哈希的,不能用做字典的键,也不能做其他集合的元素
不可变集合:与上面相反
5. 集合操作:
in、not in:判断元素是否在集合中
add():将参数作为一个元素加入集合中
update():将参数作为一个序列,将序列中的每一个内容加入到集合中
remove():删除某个元素
pop():随机删除一个
clear():清空
6. 集合类型操作符
in 、not in
集合等价与不等价(==、!=) print(set('lilyyyy') == set('liy')) True
子集,超集 print(set('lilyyyy') < set('lilysu')) True
a = set([1, 2, 3, 4, 5])
b = set([4, 5, 6, 7, 8])
交集 intersection print(a.intersection(b)) == print(a & b)
并集 print(a.union(b)) == print(a | b)
差集 print(a.difference(b)) == print(a - b)
反向交集:print(a.symmetric_difference(b)) == print(a ^ b) 反向差集
父集(超集): a.issuperset(b) == print(a > b)
子集:a.issubset(b) == print(a < b)
拷贝相关:
a = b: a、b是不可变数据类型
''' b = a 语句是直接将 a 指向的内存地址赋值给 b,a、b都指向同一块内存; 当 a 的值改变时,就指向了另一块内存 ''' a = 10 b = a print(id(a)) # 140716184614000 print(id(b)) # 140716184614000 a = 5 print(id(a)) # 140716184613776 print(id(b)) # 140716184614000
图解: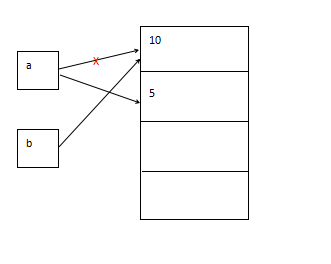
a = b: a、b是可变数据类型
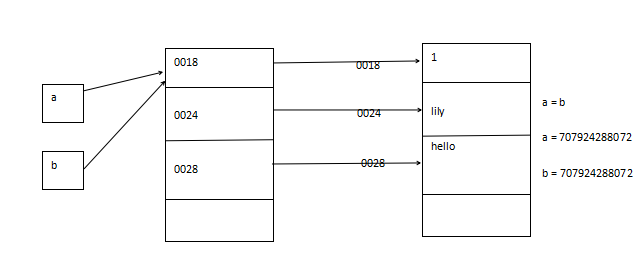
s = [1, 'lily', ' hello'] s2 = s print(id(s)) # 707924288072 print(id(s2)) # 707924288072 s[0] = 3 print(s) # [3, 'lily', ' hello'] print(s2) # [3, 'lily', ' hello'] print(id(s)) # 500697752136 print(id(s2)) # 500697752136
图解: