

1 os.path.abspath(path) 返回这个文件的绝对路径 2 os.path.split(path) 把一个路径分成两段 第二段是一个文件/文件夹 3 os.path.dirname(path) 返回path的目录 4 os.path.basename(path) 返回path 最后的文件名 5 os.path.exists(path)如果路径存在 那么返回True ,不存在 返回false 6 os.path.isabs(path)判断是否是绝对路径 7 os.path.isfile(path)判断是否是一个文件 8 os.isdir(path) 判断文件或文件夹是否存在 9 os.path.join(path1[...path2,path3])将多个路径组合后返回 10 os.path.getmtime(path) 返回path 指向的文件或者目录的最后访问时间 11 os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间 12 os.path.getsize(path) 返回path的大小 13 os.listdir 查看文件下的目录
1 #拿到这个我文件夹下所有的文件或文件夹 2 是文件就取文件大小 是文件夹就再打开这个文件夹,在取文件 计算大小 3 4 递归 5 import os 6 def func(path): 7 size_sum=0 8 name_lst=os.listdir(path) 9 for name in name_lst: 10 path_abs=os.path.join(path,name) 11 if os.path.isdir(path_abs): 12 size=func(path_abs) 13 size_sum +=size 14 else: 15 size_sum +=os.path.getsize(path_abs) 16 return size_sum 17 ret=func(文件夹路径) 18 print(ret) 19 20 21 22 23 循环 24 import os 25 lst=['C:python文件',] 列表 26 size_sum=0 27 while lst: 循环列表 28 path=lst.pop() 把列表中的元素弹出来 29 path_list=os.listdir(path) 查看路径下的文件 30 for name in path_list: 循环文件 31 path_abs=os.path.join(path,name) 32 if os.path.isdir(path_abs): 文件夹的逻辑 33 lst.append(path_abs) 34 else: 35 size_sum+=os.path.getsize(path_abs) 36 print(size_sum)
1 序列化模块
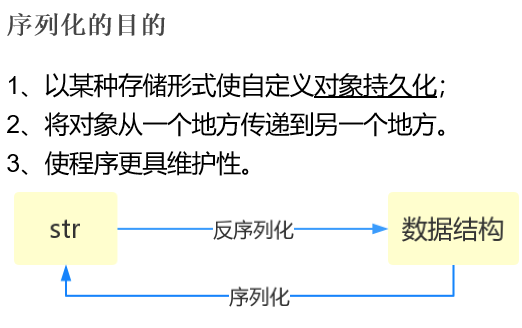
什么叫序列化?-----将原本的字典。列表等内容转换成一个字符串的过程就叫做序列化
序列化:字符串 bytes
序列: 列表,元组,字符串,bytes
为什么要把其他的数据类型转换成字符串?
1 能够在网络上传输的只能是bytes
2 能够在存储在文件里的只能是bytes和str
json 模块
1 json模块提供了四个功能:dumps,dump,loads.load
2 json在所有的语言之间都通用:json序列化的数据 在python上序列化了,能过处理的数据类型是非常有限的:字符串 列表 字典 数字,字典中的key值必须是字符串
3
1 import json 2 dic ={'k1':'v1','k2':'v2','k3':'v3'} 3 str_dic=json.dumps(dic) #序列化 ;将一个字典转换成一个字符串 4 print(str_dic,type(str_dic)) 5 #注意json换完的字符串类型的字典中的字符串是由”“表示 6 # 结果:{"k1": "v1", "k2": "v2", "k3": "v3"} <class 'str'> 7 8 9 dic2=json.loads(str_dic) #反序列化:将字符串格式的字典转换成一个字典 10 print(dic2,type(dic2)) 11 #结果:{'k1': 'v1', 'k2': 'v2', 'k3': 'v3'} <class 'dict'>
1 dump 和load是直接操作文件的 2 import json 3 # dic ={'k1':'v1','k2':'v2','k3':'v3'} 4 # with open('json_file',mode='a') as f: 5 # json.dump(dic,f) 将字典转换成字符串写入到文件中 6 7 8 with open('json_file',mode='r') as f: 9 dic=json.load(f) 从文件中将字符串字典转换成字典 10 print(dic.keys())
1 问题一: 2 import json 3 dic = {1 : 'value',2 : 'value2'} 4 ret = json.dumps(dic) # 序列化 5 print(dic,type(dic)) 6 print(ret,type(ret)) 7 8 res=json.loads(ret) 9 print(res,type(res)) 10 11 结果: 12 {1: 'value', 2: 'value2'} <class 'dict'> 没序列化之前 13 {"1": "value", "2": "value2"} <class 'str'> 序列化之后 14 {'1': 'value', '2': 'value2'} <class 'dict'> 反序列化之后 int类型的1 变成了字符串类型的‘1’ 和原来的的字典不一样 因此在使用json方法的序列化和反序列化时 不能用数字作为键 15 16 17 问题2 18 import json 19 dic = {r : [1,2,3],t : (4,5,'aa')} 20 ret = json.dumps(dic) # 序列化 21 print(dic,type(dic)) 22 print(ret,type(ret)) 23 24 结果: 25 {r: [1, 2, 3], 2: (4, 5, 'aa')} <class 'dict'> 26 {"r": [1, 2, 3], "2": [4, 5, "aa"]} <class 'str'> 27 28 在序列化的时候元组变成列表了 29 30 问题3 31 mport json 32 s = {1,2,'aaa'} 集合不是 33 json.dumps(s) 34 35 结果:TypeError: Object of type 'set' is not JSON serializable 36 37 问题4: 38 json.dumps({(1,2,3):123}) 39 keys must be a string 40 41 键值必须时字符串类型
1 import json 2 dic= {'key' : 'value','key2' : 'value2'} 3 ret=json.dumps(dic) 4 with open('json_file','a') as f: 5 f.write(ret) 6 7 8 with open('json_file','r') as f: 9 str_dic=f.read() 10 dic=json.loads(str_dic) 11 json.loads(f)
1 存文件 2 dic = {'key1' : 'value1','key2' : 'value2'} 3 with open('json_file','a') as f: 4 str_dic=json.dumps(dic) 5 f.write(str_dic+' ') 6 str_dic = json.dumps(dic) 7 f.write(str_dic + ' ') 8 str_dic = json.dumps(dic) 9 f.write(str_dic + ' ') 10 11 12 13 14 读取文件 15 with open('json_file','r') as f: 16 for line in f: 17 dic=json.loads(line.strip()) 18 print(dic.kes())
4 json 中的dumps loads 和dump load的区别
(1)dumps loads
在内存中做数据类型转换:
dumps 数据类型 转成 字符串 序列化
loads 字符串类型 转成 数据类型 反序列化
(2) dump load
直接将数据类型写入文件,直接从文件中读出数据类型
dump 数据类型 写入 文件 序列化
load 文件 读出 数据类型 反序列化
dump 在存取文件时能连续存 但读取的时候(load)不能连续取
pickle模块:pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)