前言:
JS的拷贝(copy),之所以分为深浅两种形式,是因为JS变量的类型存在premitive(字面量)与reference(引用)两种区别。当然,大多数编程语言都存在这种特性。
众所周知,内存包含的结构中,有堆与栈。在JS里,字面量类型变量存放在栈中,储存的是它的值,而引用类型变量虽然在栈中也占有空间,但储存的只是一个内存地址(通过该地址可以索引找到真实结构所在的内存区域),它的真实结构是存在于堆中的。如下图所示:
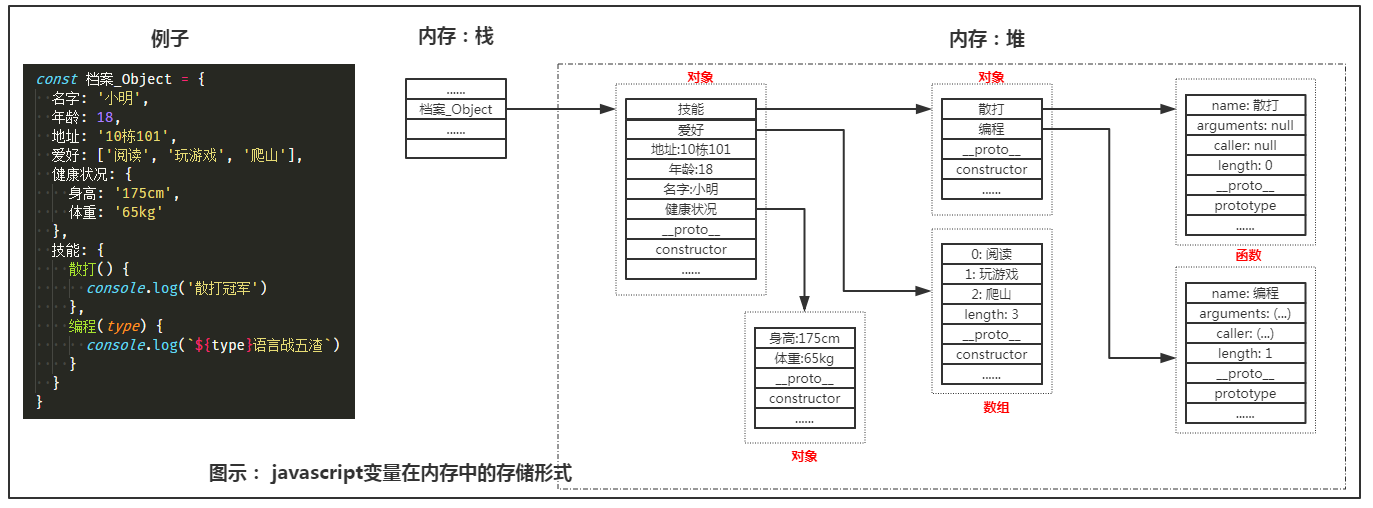
结合图示来看,一般来说,浅拷贝只是拷贝了内存栈中的数据,深拷贝,则是要沿着引用类型变量的真实内存地址,去进行一次次的深度遍历,直到拷贝完目标遍历在栈与堆中的所有真实值。
一、浅拷贝的实现
JS实现了一些拥有浅拷贝功能的接口,比如解构赋值的rest模式、Object.assgin。
但浅拷贝的缺陷在于,进行拷贝之后,如果改变了被拷贝目标的某个引用属性的值,则拷贝结果的对应属性的值也会发生改变,反过来亦是如此。
比如将example['爱好'][0]赋予新值 ('听歌'),如下图所示。

从本质上来说,就是因为两者都指向同一个内存区域。那片内存区域一旦发生了变动,自然两者取到的值都发生改变,而且完全一样。
二、深拷贝的实现
深拷贝的原理,前文已经叙述过,但过于抽象,还不够具体。
JS里,可以利用原生的JSON序列化与反序列化接口组合进行实现深拷贝。
如下图所示,深拷贝的结果与被拷贝的目标之间,已经互不影响。

不过,JSON方式实现的深拷贝,有很多缺陷,首先,是拷贝失真:
1. 值为undefined、函数、Symbol的属性,或者键为Symbol字符串的属性,拷贝后,属性会丢失。

2. 值为NaN的属性,拷贝后,值转为了null。

3. 值为非标准对象Object,比如Set、Map、Error、RegExp等等的属性或数组元素,拷贝后,值转为了空的标准对象,丢失了原来的原型继承关系。

3. 值为undefined、NaN、函数的数组元素,拷贝后,值转为了null。

其次,是拷贝功能的缺陷:
1. 原型链丢失

2. 无法拷贝有循环引用的对象

综上所述,要实现比较完整功能的深拷贝,就必须得兼顾JSON方式的功能和缺点。
三、手动实现深拷贝
追寻深拷贝的实现方式,可以理解为:深拷贝 = 浅拷贝+深度遍历+特殊情况容错。
以下,我们来实现一个深拷贝函数,deepCopy。假定函数接受的输入为o。
// 深拷贝函数 function deepCopy(o) { }
深拷贝的基本实现思路,从JS数据类型的角度出发,可以先区分字面量与引用两种类型的变量。
然后,只要判断是字面量,我们就直接浅拷贝返回,否则就进入深度遍历,重复前面的浅拷贝,直到遍历结束。
// 深拷贝函数 function deepCopy(o) { // 如果是字面量,直接返回 if(isPrimitive(o)) return o; // 否则,进行深度遍历 /** * 深度遍历代码 */ }
我们先实现一个判断输入是否为字面量的函数
function isPrimitive(o) { if (typeof o !== 'function' && typeof o !== 'object') return true; if (o === null) return true; return false; }
然后,进行深度遍历。深度遍历一般有两种选择,一个是递归,一个是while循环。
递归很好理解,但有个缺陷,大量函数栈帧的入栈,很容易导致内存空间不足而爆栈,特别是对于有循环引用关系的输入,可能秒秒钟爆炸。这里,我们采用while循环。
采用while循环的话,我们可以模拟一个栈结构,栈如果为空,则结束循环,若不为空,则进行循环,循环第一步,先出栈,然后处理数据,处理完之后,进入下一次循环判断。
在JS里,模拟栈结构可以用数组,push与pop组合,完美实现后入先出。在数据结构与算法里,这叫深度优先。
// 深拷贝函数 function deepCopy(o) { // 如果是字面量,直接返回; 否则,进行深度遍历 if(isPrimitive(o)) return o; // 首先,先定义一个观察者,用来记录遍历的结果。等到遍历结束,这个观察者就是深拷贝的结果。 const observer = {}; // 然后,用数组模拟一个栈结构 const nodeList = []; // 其次,为了每次遍历时能地做一些处理,入栈的数据用对象来表示比较合适。 nodeList.push({ key: null, // 这里,增加一个key属性,用来关联每次遍历所要处理的数据。 }); // 循环遍历 while(nodeList.length > 0) { const node = nodeList.pop(); // 出栈,深度优先 // 处理节点node } }
接下来,就是处理节点node了。这里要处理的任务,主要有:
1.特殊情况处理,比如Symbol类型的属性虽然无法被Object.keys迭代出来,但可以用Reflect.ownKeys来解决。又比如,针对循环引用,可以在循环外面建立哈希表,每次循环都判断要处理的输入是否已存在哈希表,如果存在,直接引用,否则,存入哈希表。
// 用WeakMap模拟的哈希表,它的弱引用特性可以避免内存泄露 const hashmap = new WeakMap(); // 遍历包括Symbol类型在内的所有属性 const keys = Reflect.ownKeys(node.value);
2.初始化,将输入o挂载到节点里,并存入哈希表。
// 初始化 if (node.key === null) { node.value = o; node.observer = observer // 存入哈希表 hashmap.set(node.value, node.observer) }
3.对节点的属性进行遍历,属性值为引用类型,将它压入栈,否则,观察者利用关联的key记录属性值,然后进入下一次循环。
for (let i = 0; i < keys.length; i++) { key = keys[i]; value = node.value[key]; // 是字面量,直接记录 if (isPrimitive(value)) { node.observer[key] = value; continue; } // 否则,入栈 nodeList.push({ key, value, observer: node.observer }) }
4.每次对节点属性进行遍历前,先根据哈希表进行判断
// 查询哈希表,如果不存在对象key,就存入哈希表 if (!hashmap.has(node.value)) { hashmap.set(node.value, node.observer[node.key] = isArray(node.value) ? [] : {}); // 将对象压入栈 nodeList.push({ key: node.key, value: node.value, observer: node.observer[node.key] }) continue; } // 存在哈希表里,则从哈希表里取出,赋值 else if (node.observer !== hashmap.get(node.value)) { node.observer[node.key] = hashmap.get(node.value) continue; }
这里,补上isArray函数,用来判断是否为数组
function isArray(o) { return Object.prototype.toString.call(o) === '[object Array]'; }
到此,深拷贝函数已经成型了。但,还不够完善,因为还没有对输入是函数的情况做处理。
所以,添加两个函数,一个判断是否是函数,一个用例拷贝函数。
// 判断函数 function isFunction(o) { return Object.prototype.toString.call(o) === '[object Function]'; } // 拷贝函数 function copyFunction(fnc) { const f = eval(`(${fnc.toString()})`) Object.setPrototypeOf(f, Object.getPrototypeOf(fnc)) Object.keys(fnc).map(key => f[key] = deepCopy(fnc[key])) return f; }
循环遍历之前,加一层对函数的判断
// 是函数,则拷贝函数 if (isFunction(o)) return copyFunction(o);
遍历的时候,也要加一层对函数的判断
// 函数直接赋值
else if (isFunction(node.value)) { node.observer[node.key] = copyFunction(node.value) continue; }
循环结束后,我们还要对原型链进行处理,深拷贝,不能把继承关系给弄丢,这也是输入无论是数组还是对象都能获得正确拷贝结果的一个技巧
// 继承原型 Object.setPrototypeOf(observer, Object.getPrototypeOf(o))
最后,返回观察者对象,即深拷贝结果。
// 返回深拷贝结果 return observer;
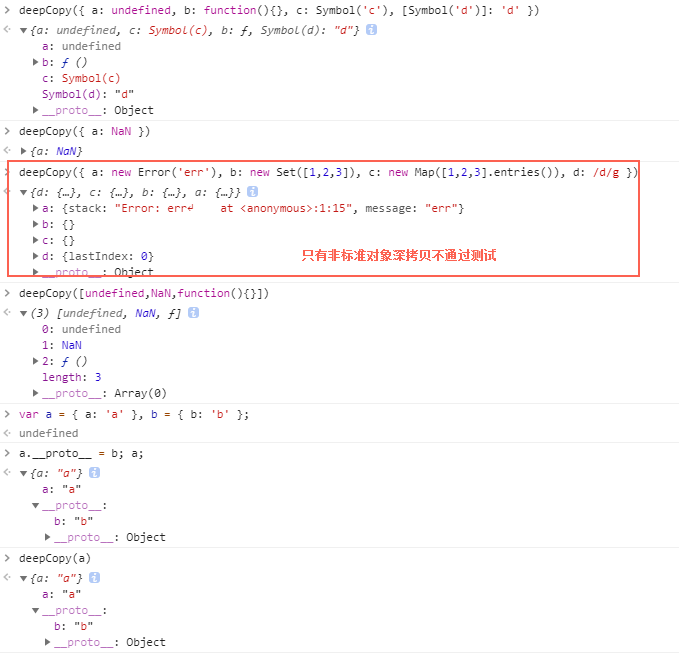
四、测试结果与结论


五、手动实现的深拷贝完整代码