1.集合概述
ava集合类存放于 java.util 包中,是一个用来存放对象的容器。
集合只能保存对象(实际上也是保存对象的引用变量),Java主要由两个接口派生而出:Collection和Map,继承树如下:

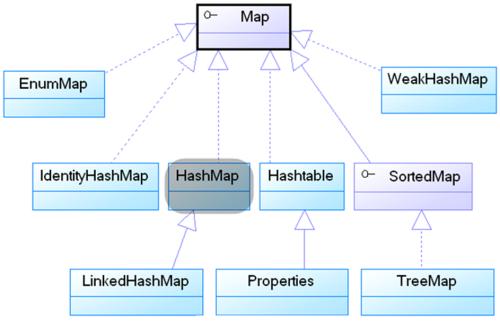
Map体系结构树
2 Collection集合常用方法:
//我们这里将 ArrayList集合作为 Collection 的实现类 Collection collection = new ArrayList(); //添加元素 collection.add("Tom"); collection.add("Bob"); //删除指定元素 collection.remove("Tom"); //删除所有元素 Collection c = new ArrayList(); c.add("Bob"); collection.removeAll(c); //检测是否存在某个元素 collection.contains("Tom"); //判断是否为空 collection.isEmpty(); //利用增强for循环遍历集合 for(Object obj : collection){ System.out.println(obj); } //利用迭代器 Iterator Iterator iterator = collection.iterator(); while(iterator.hasNext()){ Object obj = iterator.next(); System.out.println(obj); }
遍历集合可以通过Iterator或者foreach遍历集合
3 Set接口
hashset是最常用的实现类
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。
Set treeSet = new TreeSet();
treeSet.add(1); //添加一个 Integer 类型的数据 treeSet.add("a"); //添加一个 String 类型的数据 System.out.println(treeSet); //会报类型转换异常的错误* 自动排序:添加自定义对象的时候,必须要实现 Comparable 接口,并要覆盖 compareTo(Object obj) 方法来自定义比较规则
如果 this > obj,返回正数 1
如果 this < obj,返回负数 -1
如果 this = obj,返回 0 ,则认为这两个对象相等
* 定制排序: 创建 TreeSet 对象时, 传入 Comparator 接口的实现类. 要求: Comparator 接口的 compare 方法的返回值和 两个元素的 equals() 方法具有一致的返回值
public class TreeSetTest {
public static void main(String[] args) { Person p1 = new Person(1); Person p2 = new Person(2); Person p3 = new Person(3); Set<Person> set = new TreeSet<>(new Person()); set.add(p1); set.add(p2); set.add(p3); System.out.println(set); //结果为[1, 2, 3] }}class Person implements Comparator<Person>{ public int age; public Person(){} public Person(int age){ this.age = age; } @Override /*** * 根据年龄大小进行排序 */ public int compare(Person o1, Person o2) { // TODO Auto-generated method stub if(o1.age > o2.age){ return 1; }else if(o1.age < o2.age){ return -1; }else{ return 0; } } @Override public String toString() { // TODO Auto-generated method stub return ""+this.age; }}EnumSet类
enum Season {
SPRING, SUMMER, FALL, WINTER
}
public class EnumSetTest {
public static void main(String[] args) {
//创建一个EnumSet集合,集合元素就是Season枚举类的全部枚举值
EnumSet es1 = EnumSet.allOf(Season.class);
//输出[SPRING, SUMMER, FALL, WINTER]
System.out.println(es1);
//创建一个EnumSet空集合,指定其集合元素是Season类的枚举值
EnumSet es2 = EnumSet.noneOf(Season.class);
//输出[]
System.out.println(es2);
//手动添加两个元素
es2.add(Season.WINTER);
es2.add(Season.SPRING);
//输出[Spring, WINTER]
System.out.println(es2);
//以指定枚举值创建EnumSet集合
EnumSet es3 = EnumSet.of(Season.SUMMER, Season.WINTER);
//输出[SUMMER, WINTER]
System.out.println(es3);
//创建一个包含两个枚举值范围内所有枚举值的EnumSet集合
EnumSet es4 = EnumSet.range(Season.SUMMER, Season.WINTER);
//输出[SUMMER, FALL, WINTER]s
System.out.println(es4);
//新创建的EnumSet集合元素和es4集合元素有相同的类型
//es5集合元素 + es4集合元素=Season枚举类的全部枚举值
EnumSet es5 = EnumSet.complementOf(es4);
System.out.println(es5);
//创建一个集合
Collection c = new HashSet();
c.clear();
c.add(Season.SPRING);
c.add(Season.WINTER);
//复制Collection集合中的所有元素来创建EnumSet集合
EnumSet es = EnumSet.copyOf(c);
//输出es
System.out.println(es);
c.add("111");
c.add("222");
//下面代码出现异常,因为c集合里的元素不是全部都为枚举值
es = EnumSet.copyOf(c);
}
}
4 List接口
由于 List 接口是继承于 Collection 接口,所以基本的方法如上所示。
1、List 接口的三个典型实现:
①、List list1 = new ArrayList();
底层数据结构是数组,查询快,增删慢;线程不安全,效率高
②、List list2 = new Vector();
底层数据结构是数组,查询快,增删慢;线程安全,效率低,几乎已经淘汰了这个集合
③、List list3 = new LinkedList();
底层数据结构是链表,查询慢,增删快;线程不安全,效率高
怎么记呢?我们可以想象:
数组就像身上编了号站成一排的人,要找第10个人很容易,根据人身上的编号很快就能找到。但插入、删除慢,要望某个位置插入或删除一个人时,后面的人身上的编号都要变。当然,加入或删除的人始终末尾的也快。
链表就像手牵着手站成一圈的人,要找第10个人不容易,必须从第一个人一个个数过去。但插入、删除快。插入时只要解开两个人的手,并重新牵上新加进来的人的手就可以。删除一样的道理。
2、除此之外,List 接口遍历还可以使用普通 for 循环进行遍历,指定位置添加元素,替换元素等等。
//产生一个 List 集合,典型实现为 ArrayList List list = new ArrayList(); //添加三个元素 list.add("Tom"); list.add("Bob"); list.add("Marry"); //构造 List 的迭代器 Iterator it = list.iterator(); //通过迭代器遍历元素 while(it.hasNext()){ Object obj = it.next(); //System.out.println(obj); } //在指定地方添加元素 list.add(2, 0); //在指定地方替换元素 list.set(2, 1); //获得指定对象的索引 int i=list.indexOf(1); System.out.println("索引为:"+i); //遍历:普通for循环 for(int j=0;j<list.size();j++){ System.out.println(list.get(j)); }
5 Map
1、Set hashSet = new HashSet();
①、HashSet:不能保证元素的顺序;不可重复;不是线程安全的;集合元素可以为 NULL;
②、其底层其实是一个数组,存在的意义是加快查询速度。我们知道在一般的数组中,元素在数组中的索引位置是随机的,元素的取值和元素的位置之间不存在确定的关系,因此,在数组中查找特定的值时,需要把查找值和一系列的元素进行比较,此时的查询效率依赖于查找过程中比较的次数。而 HashSet 集合底层数组的索引和值有一个确定的关系:index=hash(value),那么只需要调用这个公式,就能快速的找到元素或者索引。