数据增强
- 常用数据增强方法:
transforms.RandomCrop # 随机位置裁剪
transforms.CenterCrop # 中心位置裁剪
transforms.RandomHorizontalFlip(p = 1) # 随机水平翻转
transforms.RandomVerticalFlip(p = 1) # 随机上下翻转
transforms.RandomRotation # 随机旋转
transforms.ColorJitter(brighter = 1) # 明暗度
transforms.ColorJitter(contrast = 1) # 对比度
transforms.ColorJitter(saturation = 0.5) # 饱和度
transforms.ColorJitter(hue = 0.5) # 随机调整颜色
transforms.RandomGrayscale(p = 0.5) # 随机灰度化
学习速率衰减
学习速率衰减就是每经过几个epoch,学习速率就会降低,一般为指数型衰减
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size = 5, gamma = 0.9) # 每经过多少个step,衰减为原来的多少
torch.optim.lr_scheduler.MultiStepLR(optimizer, [20, 50, 80], gamma = 0.1) # 哪几个epoch时,衰减为原来的多少
torch.optim.lr_scheduler.ExponentialLR(optimizer, gamma = 0.1) # 按照gamma的epoch次方衰减
注意,要在fit里面加一句
exp_lr_scheduler.step()
完整代码
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch.nn as nn
import torch.nn.functional as F
import torchvision
from torchvision import datasets, transforms, models
import os
import shutil
%matplotlib inline
train_transform = transforms.Compose([
transforms.Resize(224),
transforms.RandomCrop(192),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(0.2),
transforms.ColorJitter(brightness = 0.5),
transforms.ColorJitter(contrast = 0.5),
transforms.ToTensor(),
transforms.Normalize(mean = [0.5, 0.5, 0.5], std = [0.5, 0.5, 0.5])
])
test_transform = transforms.Compose([
transforms.Resize((192, 192)),
transforms.ToTensor(),
transforms.Normalize(mean = [0.5, 0.5, 0.5], std = [0.5, 0.5, 0.5])
])
train_ds = datasets.ImageFolder(
"E:/datasets2/29-42/29-42/dataset2/4weather/train",
transform = train_transform
)
test_ds = datasets.ImageFolder(
"E:/datasets2/29-42/29-42/dataset2/4weather/test",
transform = test_transform
)
train_dl = torch.utils.data.DataLoader(train_ds, batch_size = 8, shuffle = True)
test_dl = torch.utils.data.DataLoader(test_ds, batch_size = 8)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = models.vgg16(pretrained = True)
for p in model.features.parameters():
p.requries_grad = False
model.classifier[-1].out_features = 4
model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr = 0.0001)
epochs = 20
loss_func = torch.nn.CrossEntropyLoss()
exp_lr_scheduler = torch.optim.lr_scheduler.StepLR(optimizer,
step_size = 5,
gamma = 0.9)
def fit(epoch, model, trainloader, testloader):
correct = 0
total = 0
running_loss = 0
model.train()
for x, y in trainloader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_func(y_pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
with torch.no_grad():
y_pred = torch.argmax(y_pred, dim = 1)
correct += (y_pred == y).sum().item()
total += y.size(0)
running_loss += loss.item()
exp_lr_scheduler.step() # 规定一个step为一个epoch
epoch_acc = correct / total
epoch_loss = running_loss / len(trainloader.dataset)
test_correct = 0
test_total = 0
test_running_loss = 0
model.eval()
with torch.no_grad():
for x, y in testloader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
loss = loss_func(y_pred, y)
y_pred = torch.argmax(y_pred, dim = 1)
test_correct += (y_pred == y).sum().item()
test_total += y.size(0)
test_running_loss += loss.item()
epoch_test_acc = test_correct / test_total
epoch_test_loss = test_running_loss / len(testloader.dataset)
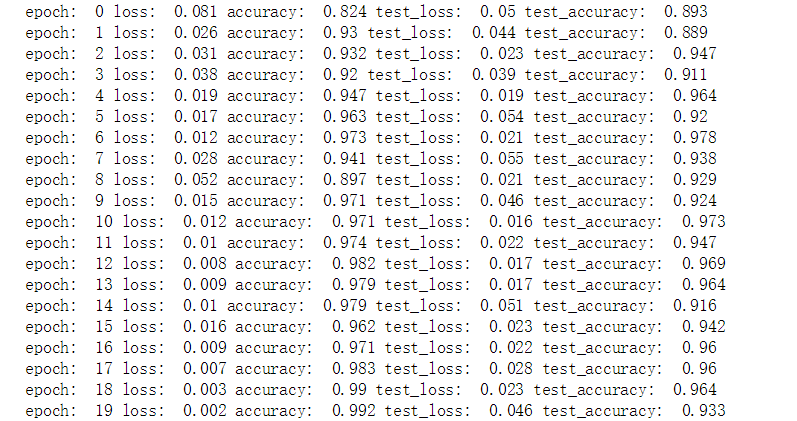
print('epoch: ', epoch,
'loss: ', round(epoch_loss, 3),
'accuracy: ', round(epoch_acc, 3),
'test_loss: ', round(epoch_test_loss, 3),
'test_accuracy: ', round(epoch_test_acc, 3))
return epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
epoch_loss, epoch_acc, epoch_test_loss, epoch_test_acc = fit(epoch, model, train_dl, test_dl)
train_loss.append(epoch_loss)
train_acc.append(epoch_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
结果展示
准确率有些许的提高