编写ORM
对象关系映射(Object Relational Mapping,简称ORM)模式是一种为了解决面向对象与关系数据库存在互不匹配的现象的技术。换句话说,ORM是通过使用描述对象和数据库直接映射的元数据,将程序中的对象自动持久化到关系数据库中。
在一个网站中,所有的数据(包括用户,日志,评论等)都存储在数据库中。我们的网站awesome-website选择用MySQL作为数据库。访问数据库需要创建数据库连接,游标对象,执行SQL语句,处理异常,清理资源。这些访问数据库的代码如果分散到每个函数中去,十分难以维护,效率低下不利于复用。因此,我们将常用的MySQL数据库操作用函数封装起来,便于网站调用。
由于我们的网站基于异步编程,系统的每一层都必须是异步。aiomysql为MySQL数据库提供了异步IO的驱动。
创建连接池
我们需要创建一个全局的连接池,每个HTTP请求都可以从连接池中直接获取数据库连接。使用连接池的好处是不必频繁地打开和关闭数据库连接,而是能复用就尽量复用。
连接池由全局变量__pool存储,缺省情况下将编码设置为utf8,自动提交事务。在www目录下新建orm.py加入以下代码:
orm.py
import asyncio,logging,aiomysql
# 定义日志输出级别为INFO,默认为WARNING
logging.basicConfig(level=logging.INFO)
# 定义日志输出函数,在其他函数内部调用即可输出info日志
def log(sql,args=()):
logging.info('SQL:%s' % sql)
# 定义创建连接池的协程函数,该协程函数传递参数为一个事件循环对象loop
# 和一个字典,字典内为创建连接池所需要的参数例如连接数据库的host,port,user,password,db等信息
async def create_pool(loop,**kw):
logging.info('create database connection pool...')
# 连接池为全局变量,其他函数也可以调用
global __pool
__pool = await aiomysql.create_pool(
# 获取字典kw的host属性,如果没有获取到则返回自定义的localhost
# 即如果字典没有传递host为key的值则默认使用localhost
host=kw.get('host', 'localhost'),
port=kw.get('port', 3306),
# 从字典获取user,password,db等信息
user=kw['user'],
password=kw['password'],
db=kw['db'],
charset=kw.get('charset', 'utf8'),
autocommit=kw.get('autocommit', True),
maxsize=kw.get('maxsize', 10),
minsize=kw.get('minsize', 1),
loop=loop
)
下面演示调用协程函数创建连接池
前提,我们已经在本机创建好一个数据库,数据库名称为awesome 用户名和密码为www-data
添加以下代码
# 演示创建连接池
# 创建事件循环对象
loop = asyncio.get_event_loop()
# 定义连接池的参数
kw = {'user':'www-data','password':'www-data','db':'awesome'}
loop.run_until_complete(create_pool(loop=loop,**kw))
print(__pool)
# <aiomysql.pool.Pool object at 0x000002672F1FE488>
注意:函数使用了关键字参数**kw则传递参数有两种形式
# 第一种形式,传递一个字典,前面需要加** (**kw) # 第二种形式,直接以key=value方式传递,key不需要加引号 (user='www-data',password='www-data',db='awesome')
运行不报错即代表该协程函数运行成功,本次传递字典没有传递host和port信息使用的是默认的localhost和端口3306
如果任何一个参数错误,例如密码错误,则运行会报错
输出全局变量__pool为一个连接池对象
Select
要执行SELECT语句,我们用select函数执行,需要传入SQL语句和SQL参数。追加以下代码至orm.py:
在追加代码以前我们先来看通过连接池怎么搜索数据库内的数据
首页演示不带参数的搜索
以下代码演示的前提条件
1,已经运行上面的create_pool协程函数创建了全局变量连接池__pool,因为我们要通过连接池连接MySQL数据库
2,已经创建了数据库awesome并且往数据库插入了本次测试的演示tabel users 并且表格有几条测试数据
该表格的创建语句如下
CREATE TABLE `users` ( `id` varchar(50) NOT NULL, `email` varchar(50) NOT NULL, `passwd` varchar(50) NOT NULL, `admin` tinyint(1) NOT NULL, `name` varchar(50) NOT NULL, `image` varchar(500) NOT NULL, `created_at` double NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `idx_email` (`email`), KEY `idx_created_at` (`created_at`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
test.py
async def select(sql):
log(sql)
# 通过连接池__pool创建一个 <class 'aiomysql.connection.Connection'>对象conn
# 前提是运行过协程函数create_pool已经创建了连接池__pool
# 使用这个语句运行会报警告DeprecationWarning,但是可以正常运行
with await __pool as conn:
# 使用这个语句不报警告
# async with __pool.acquire() as conn:
# print(type(conn))
# 使用await conn.cursor(aiomysql.DictCursor)创建一个<class 'aiomysql.cursors.DictCursor'>对象赋值给cur
cur = await conn.cursor(aiomysql.DictCursor)
# print(type(cur))
# 执行搜索sql语句为函数传递的sql语句
await cur.execute(sql)
# 把所有搜索结果返回,返回为一个list 内部元素为搜索结果对应的0至多个字典
# 方法cur.fetchmany(size)返回size设置的指定数量的最多返回结果
# 即假如返回结果有5条把size设置为3则最多返回3条
rs = await cur.fetchall()
# 关闭
await cur.close()
return rs
res=loop.run_until_complete(select('select * from users'))
print(res)
本表格已经插入了3条数据,本次使用的是fetchall()方法是有返回了搜索的3条数据返回一个list,输出如下
C:/Python37/python.exe d:/awesome-python3-webapp/www/test.py
INFO:root:create database connection pool...
INFO:root:SQL:select * from users
d:/awesome-python3-webapp/www/test.py:33: DeprecationWarning: with await pool as conn deprecated, useasync with pool.acquire() as conn instead
with await __pool as conn:
[{'id': '00163644748205841b9bba0d0fd4d79ad929a4e99ff2989000', 'email': 'test@qq.com', 'passwd': '1234567890', 'admin': 0, 'name': 'Test', 'image': 'about:blank', 'created_at': 1636447482.05881}, {'id': '001636510608229f1f72c1450ba441fa524ce6feac18512000', 'email': 'liuym@qq.com', 'passwd': '54a33e13f53df79406661069ff9d9d0a827233ec', 'admin': 1, 'name': 'liuym', 'image': 'http://www.gravatar.com/avatar/12c0df57579d413d7481425bafea1072?d=mm&s=120', 'created_at': 1636510608.23049}, {'id': '001636510717371baacb3aa7610458f994b9ddae3bd1b7e000', 'email': 'liuyueming@qq.com', 'passwd': 'd69cbd3fae507abb7f106655d0c9df12fc1d002c', 'admin': 0, 'name': 'liuyueming', 'image': 'http://www.gravatar.com/avatar/4ef117529fd9eebd18eba8d86c80fe42?d=mm&s=120', 'created_at': 1636510717.37168}]
还支持带参数的sql语法为
cur.execute(sql,args) # sql为搜索语句语句内部带格式化符号%s例如 select * from user limit %s # 其中%s替换的对象为args为一个list或者元组,前面sql语句有几个%s则list需要有一一对应的元素,例如 [1]
下面修改搜索函数把参数args加上
# 带参数sql
async def select(sql,args):
log(sql)
# 通过连接池__pool创建一个 <class 'aiomysql.connection.Connection'>对象conn
# 前提是运行过协程函数create_pool已经创建了连接池__pool
# 使用这个语句运行会报警告DeprecationWarning,但是可以正常运行
with await __pool as conn:
# 使用这个语句不报警告
# async with __pool.acquire() as conn:
# print(type(conn))
# 使用await conn.cursor(aiomysql.DictCursor)创建一个<class 'aiomysql.cursors.DictCursor'>对象赋值给cur
cur = await conn.cursor(aiomysql.DictCursor)
# print(type(cur))
# 执行搜索sql语句为函数传递的sql语句
await cur.execute(sql,args)
# 把所有搜索结果返回,返回为一个list 内部元素为搜索结果对应的0至多个字典
# 方法cur.fetchmany(size)返回size设置的指定数量的最多返回结果
# 即假如返回结果有5条把size设置为3则最多返回3条
rs = await cur.fetchall()
# 关闭
await cur.close()
return rs
res=loop.run_until_complete(select('select * from users limit %s',[1]))
print(res)
本次传递sql语句和args参数为
'select * from users limit %s',[1]
格式之后相当于执行了一次
select * from users limit 1
即查找一条,所以结果只有一条
参数也可以有多个,如果有多个参数%s则对应的args也需要有一一对应的多个对象例如,搜索1,2条结果
res=loop.run_until_complete(select('select * from users limit %s,%s',[1,2]))
因为sql语句的占位符为?而MySQL的占位符为%s所以需要把传入的sql语句的?转换成%s,最后添加至orm.py的select函数如下
# select start
async def select(sql,args,size=None):
log(sql,args)
# 通过连接池__pool创建一个 <class 'aiomysql.connection.Connection'>对象conn
# 前提是运行过协程函数create_pool已经创建了连接池__pool
# 使用这个语句运行会报警告DeprecationWarning,但是可以正常运行
with await __pool as conn:
# 使用这个语句不报警告
# async with __pool.acquire() as conn:
# print(type(conn))
# 使用await conn.cursor(aiomysql.DictCursor)创建一个<class 'aiomysql.cursors.DictCursor'>对象赋值给cur
cur = await conn.cursor(aiomysql.DictCursor)
# print(type(cur))
# 执行搜索sql语句为函数传递的sql语句
await cur.execute(sql.replace('?','%s'),args or ())
if size:
rs = await cur.fetchmany(size)
else:
rs = await cur.fetchall()
# 关闭
await cur.close()
# 打印日志返回了几条数据
logging.info('rows returned:%s' % len(rs))
return rs
# select end
下面代码分别演示无参数,有参数,设置size的搜索
res=loop.run_until_complete(select('select * from users',[]))
print(res)
res=loop.run_until_complete(select('select * from users limit ?',[1]))
print(res)
res=loop.run_until_complete(select('select * from users',[],size=2))
print(res)
第一个无参数搜索users表里所有数据返回三条数据,第二个使用limit参数输出一条数据,这里是?在select函数内部替换成占位符%s,第三个size设置为2则在select函数内使用的是fetchmany(2)返回两条数据
SQL语句的占位符是?,而MySQL的占位符是%s,select()函数在内部自动替换。注意要始终坚持使用带参数的SQL,而不是自己拼接SQL字符串,这样可以防止SQL注入攻击。
注意到await将调用一个子协程(也就是在一个协程中调用另一个协程)并直接获得子协程的返回结果。
如果传入size参数,就通过fetchmany()获取最多指定数量的记录,否则,通过fetchall()获取所有记录。
Insert, Update, Delete
要执行INSERT、UPDATE、DELETE语句,可以定义一个通用的execute()函数,因为这3种SQL的执行都需要相同的参数,以及返回一个整数表示影响的行数。追加以下代码至orm.py:
# Insert, Update, Delete start
async def execute(sql,args):
log(sql)
with (await __pool) as conn:
try:
# 使用await conn.cursor()创建<class 'aiomysql.cursors.Cursor'>对象
cur = await conn.cursor()
# print(type(cur))
await cur.execute(sql.replace('?','%s'),args)
affected = cur.rowcount
await cur.close()
except BaseException as e:
raise
return affected
# Insert, Update, Delete end
下面演示通过以上协程函数分别执行insert,update,delete操作
res = loop.run_until_complete(execute('insert into users values(123,"test1@qq.com","123456789",0,"liuym","http://image",1111111111)',[]))
print(res)
res = loop.run_until_complete(execute('update users set name="liuyueming" where email=?',["test1@qq.com"]))
print(res)
res = loop.run_until_complete(execute('delete from users where email=?',["test1@qq.com"]))
print(res)
首先插入一条数据然后更新该数据最后再删除这条数据,每次返回的影响行数都为1,输出如下
INFO:root:SQL:insert into users values(123,"test1@qq.com","123456789",0,"liuym","http://image",1111111111) 1 INFO:root:SQL:update users set name="liuyueming" where email=? 1 INFO:root:SQL:delete from users where email=? 1
execute()函数和select()函数所不同的是,cursor对象不返回结果集,而是通过rowcount返回结果数。即本次操作影响表的行数。
ORM
为了便于理解在编写ORM之前我们来拆分解析过程
关于使用元类metaclass编写ORM的过程参考:https://www.cnblogs.com/minseo/p/15572543.html
本博客实战的例子比使用metaclss编写ORM的例子会复杂一些,但是基本原理未变
1,拆分解析类User的使用metaclass的修改过程
下面代码示例使用metaclass修改User类的过程,本拆分仅为解析修改User类的过程,为了便于解析没有在User的父类Model定义任何属性和方法
class Model(dict, metaclass=ModelMetaclass):
pass
代码如下 orm_split.py
为了便于分析我们打印了修改前的attrs和修改后的attrs
############################################
# 拆分解析类User的使用metaclass的修改过程 start
import time
def create_args_string(num):
L = []
for n in range(num):
L.append('?')
return ', '.join(L)
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
# 排除Model类本身,即针对Model不做任何修改原样返回:
if name=='Model':
return type.__new__(cls, name, bases, attrs)
# 获取table名称:
# 从字典attrs中获取属性__table__,如果在类中没有定义这个属性则返回None
# 如果在属性中没有定义但是我们可以从参数name中获取到就是类名
# 例如我们对类User进行重新创建,在类User中已经定义了属性 __table__ = 'users'
# 所以我们优先得到的表名就是'users',假如没有定义则就是类名'User'
tableName = attrs.get('__table__', None) or name
# 输出日志
logging.info('found model: %s (table: %s)' % (name, tableName))
# 为了便于观察我们打印对类修改前的attrs字典
print("修改前attrs:%s" % attrs)
# 获取所有的Field和主键名:
# 定义一个空字典用于存储需要定义的类中除了默认属性以为定义的属性
# 例如本次我们针对类User则使用mappings字典存储'id','email','passwd','admin','name','image','create_at'的属性
# 它们对应的属性值是一个实例化以后的实例,例如id对应的属性值是通过类StringField实例化后的实例
mappings = dict()
# fields表用于存储普通的字段名称,即除了主键以外的其他字段
# 例如针对User类则在fields存储字段'email','passwd','admin','name','image','create_at'的名称
fields = []
# primaryKey用于存储主键字段名
# 例如针对类User的主键名为'id'
primaryKey = None
# 以key,value的方式遍历attrs字典
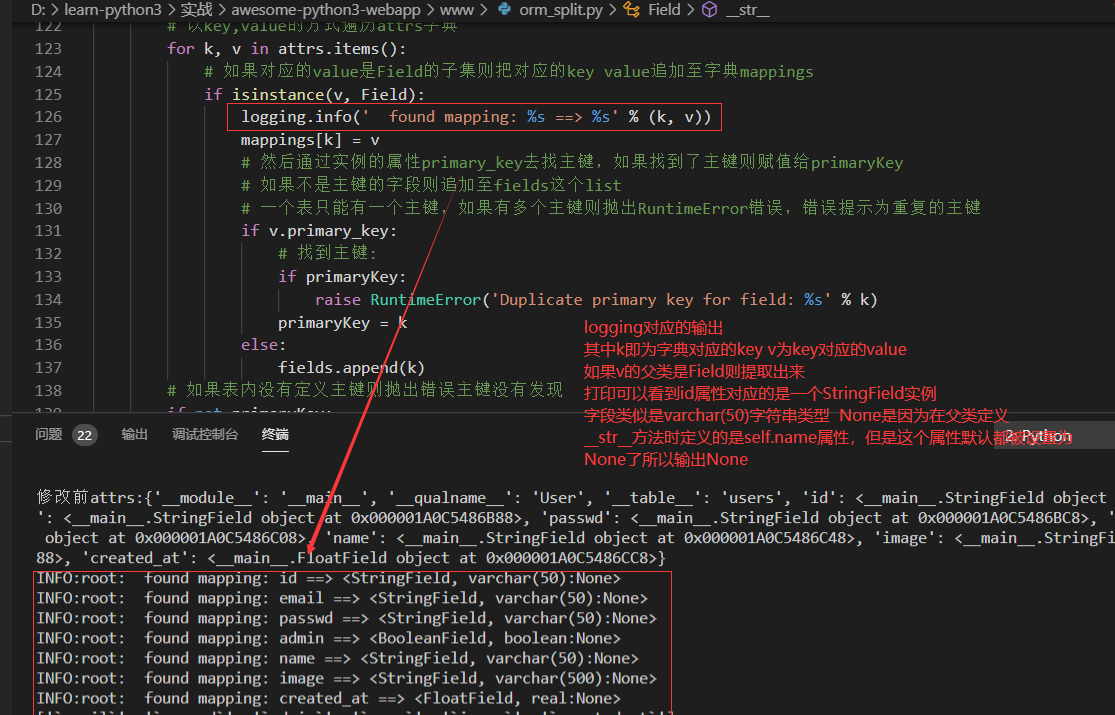
for k, v in attrs.items():
# 如果对应的value是Field的子集则把对应的key value追加至字典mappings
if isinstance(v, Field):
logging.info(' found mapping: %s ==> %s' % (k, v))
mappings[k] = v
# 然后通过实例的属性primary_key去找主键,如果找到了主键则赋值给primaryKey
# 如果不是主键的字段则追加至fields这个list
# 一个表只能有一个主键,如果有多个主键则抛出RuntimeError错误,错误提示为重复的主键
if v.primary_key:
# 找到主键:
if primaryKey:
raise RuntimeError('Duplicate primary key for field: %s' % k)
primaryKey = k
else:
fields.append(k)
# 如果表内没有定义主键则抛出错误主键没有发现
if not primaryKey:
raise RuntimeError('Primary key not found.')
# 已经把对应的key value存储至字典以后,从原attrs中属性中删除对应的key value
# 如果不删除则类属性和实例属性会冲突
# 例如类User需要从原attrs中删除key值为 'id','email','passwd','admin','name','image','create_at'的元素
for k in mappings.keys():
attrs.pop(k)
# 把存储除主键之外的字典list元素加一个``
# 例如原fields为 ['email', 'passwd', 'admin', 'name', 'image', 'created_at']
# map经过匿名函数把list中的所有元素处理加符号``,处理以后得到一个惰性序列然后通过list输出
# escaped_fields为 ['`email`', '`passwd`', '`admin`', '`name`', '`image`', '`created_at`']
escaped_fields = list(map(lambda f: '`%s`' % f, fields))
print(escaped_fields)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
# 保存表名
attrs['__table__'] = tableName
# 主键属性名
attrs['__primary_key__'] = primaryKey
# 除主键外的属性名
attrs['__fields__'] = fields
# 构造默认的SELECT, INSERT, UPDATE和DELETE语句:
attrs['__select__'] = 'select `%s`, %s from `%s`' % (primaryKey, ', '.join(escaped_fields), tableName)
attrs['__insert__'] = 'insert into `%s` (%s, `%s`) values (%s)' % (tableName, ', '.join(escaped_fields), primaryKey, create_args_string(len(escaped_fields) + 1))
attrs['__update__'] = 'update `%s` set %s where `%s`=?' % (tableName, ', '.join(map(lambda f: '`%s`=?' % (mappings.get(f).name or f), fields)), primaryKey)
attrs['__delete__'] = 'delete from `%s` where `%s`=?' % (tableName, primaryKey)
print("修改后attrs:%s" % attrs)
return type.__new__(cls, name, bases, attrs)
class Model(dict, metaclass=ModelMetaclass):
pass
# 定义Field类,作为数据库字段类型的父类
class Field(object):
# 初始化方法定义了4个属性,分别为name字段名(id),column_type字段属性(bigint),primary_key是否为主键(True or False),default默认值
def __init__(self, name, column_type, primary_key, default):
self.name = name
self.column_type = column_type
self.primary_key = primary_key
self.default = default
# 返回实例对象的时候好看一点默认返回为 <__main__.StringField object at 0x0000025CC313EF08>
# 定义了__str__返回为 <StringField:email>
# 可以省略使用默认也可以
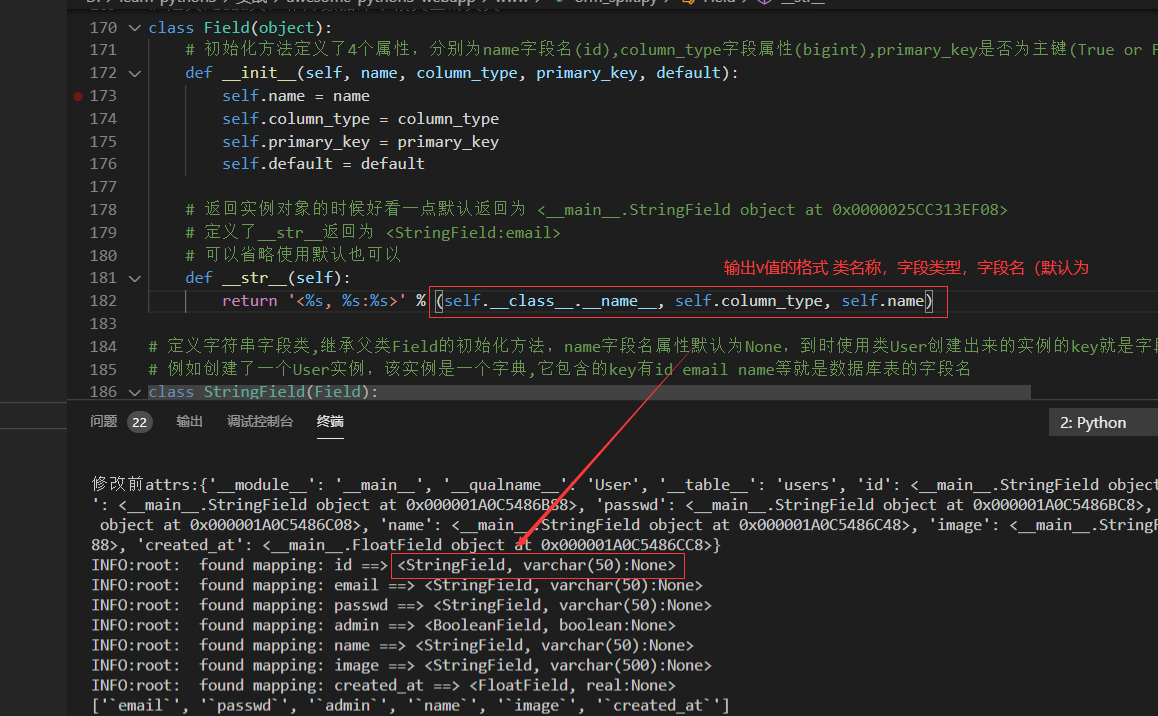
def __str__(self):
return '<%s, %s:%s>' % (self.__class__.__name__, self.column_type, self.name)
# 定义字符串字段类,继承父类Field的初始化方法,name字段名属性默认为None,到时使用类User创建出来的实例的key就是字段名
# 例如创建了一个User实例,该实例是一个字典,它包含的key有id email name等就是数据库表的字段名
class StringField(Field):
def __init__(self, name=None, primary_key=False, default=None, ddl='varchar(100)'):
super().__init__(name, ddl, primary_key, default)
# 定义布尔类型字段类,通过name属性为None
# 字段类型默认为boolean,默认为非主键,默认值为False
class BooleanField(Field):
def __init__(self, name=None, default=False):
super().__init__(name, 'boolean', False, default)
# 定义整数类型字段类
class IntegerField(Field):
def __init__(self, name=None, primary_key=False, default=0):
super().__init__(name, 'bigint', primary_key, default)
# 定义浮点类型字段类,字段类型real相当于float
class FloatField(Field):
def __init__(self, name=None, primary_key=False, default=0.0):
super().__init__(name, 'real', primary_key, default)
# 定义文本类型字段类
class TextField(Field):
def __init__(self, name=None, default=None):
super().__init__(name, 'text', False, default)
# 定义函数,用于随机生成一个字符串作为主键id的值
# 加括号运行函数返回一个字符串字符串去前15位为时间戳乘以1000,然后不足15位使用0补齐
# 后面为使用uuid.uuid4().hex随机生成的一段字符串
# 最后补000
def next_id():
return '%015d%s000' % (int(time.time() * 1000), uuid.uuid4().hex)
# 定义用户User类
class User(Model):
# 自定义表名,如果不自定义可以使用类名作为表名
# 在使用metaclass重新定义类时,通过方法__new__内部的参数name可以获取到类名
__table__ = 'users'
# 定义字段名,id作为主键
id = StringField(primary_key=True, default=next_id, ddl='varchar(50)')
email = StringField(ddl='varchar(50)')
passwd = StringField(ddl='varchar(50)')
admin = BooleanField()
name = StringField(ddl='varchar(50)')
image = StringField(ddl='varchar(500)')
created_at = FloatField(default=time.time)
u = User(name='Test', email='test@qq.com', passwd='1234567890', image='about:blank')
# 拆分解析类User的使用metaclass的修改过程 start
#$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
运行输出如下
INFO:root:found model: User (table: users)
修改前attrs:{'__module__': '__main__', '__qualname__': 'User', '__table__': 'users', 'id': <__main__.StringField object at 0x0000016406EE6CC8>, 'email': <__main__.StringField object at 0x0000016406EE6D08>, 'passwd': <__main__.StringField object at 0x0000016406EE6D48>, 'admin': <__main__.BooleanField object at 0x0000016406EE6D88>, 'name': <__main__.StringField object at 0x0000016406EE6DC8>, 'image': <__main__.StringField object at 0x0000016406EE6E08>, 'created_at': <__main__.FloatField object at 0x0000016406EE6E48>}
INFO:root: found mapping: id ==> <StringField, varchar(50):None>
INFO:root: found mapping: email ==> <StringField, varchar(50):None>
INFO:root: found mapping: passwd ==> <StringField, varchar(50):None>
INFO:root: found mapping: admin ==> <BooleanField, boolean:None>
INFO:root: found mapping: name ==> <StringField, varchar(50):None>
INFO:root: found mapping: image ==> <StringField, varchar(500):None>
INFO:root: found mapping: created_at ==> <FloatField, real:None>
['`email`', '`passwd`', '`admin`', '`name`', '`image`', '`created_at`']
修改后attrs:{'__module__': '__main__', '__qualname__': 'User', '__table__': 'users', '__mappings__': {'id': <__main__.StringField object at 0x0000016406EE6CC8>, 'email': <__main__.StringField object at 0x0000016406EE6D08>, 'passwd': <__main__.StringField object at 0x0000016406EE6D48>, 'admin': <__main__.BooleanField object at 0x0000016406EE6D88>, 'name': <__main__.StringField object at 0x0000016406EE6DC8>, 'image': <__main__.StringField object at 0x0000016406EE6E08>, 'created_at': <__main__.FloatField object at 0x0000016406EE6E48>}, '__primary_key__': 'id', '__fields__': ['email', 'passwd', 'admin', 'name', 'image', 'created_at'], '__select__': 'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', '__insert__': 'insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (?, ?, ?, ?, ?, ?, ?)', '__update__': 'update `users` set `email`=?, `passwd`=?, `admin`=?, `name`=?, `image`=?, `created_at`=? where `id`=?', '__delete__': 'delete from `users` where `id`=?'}
分析语句对应的输出
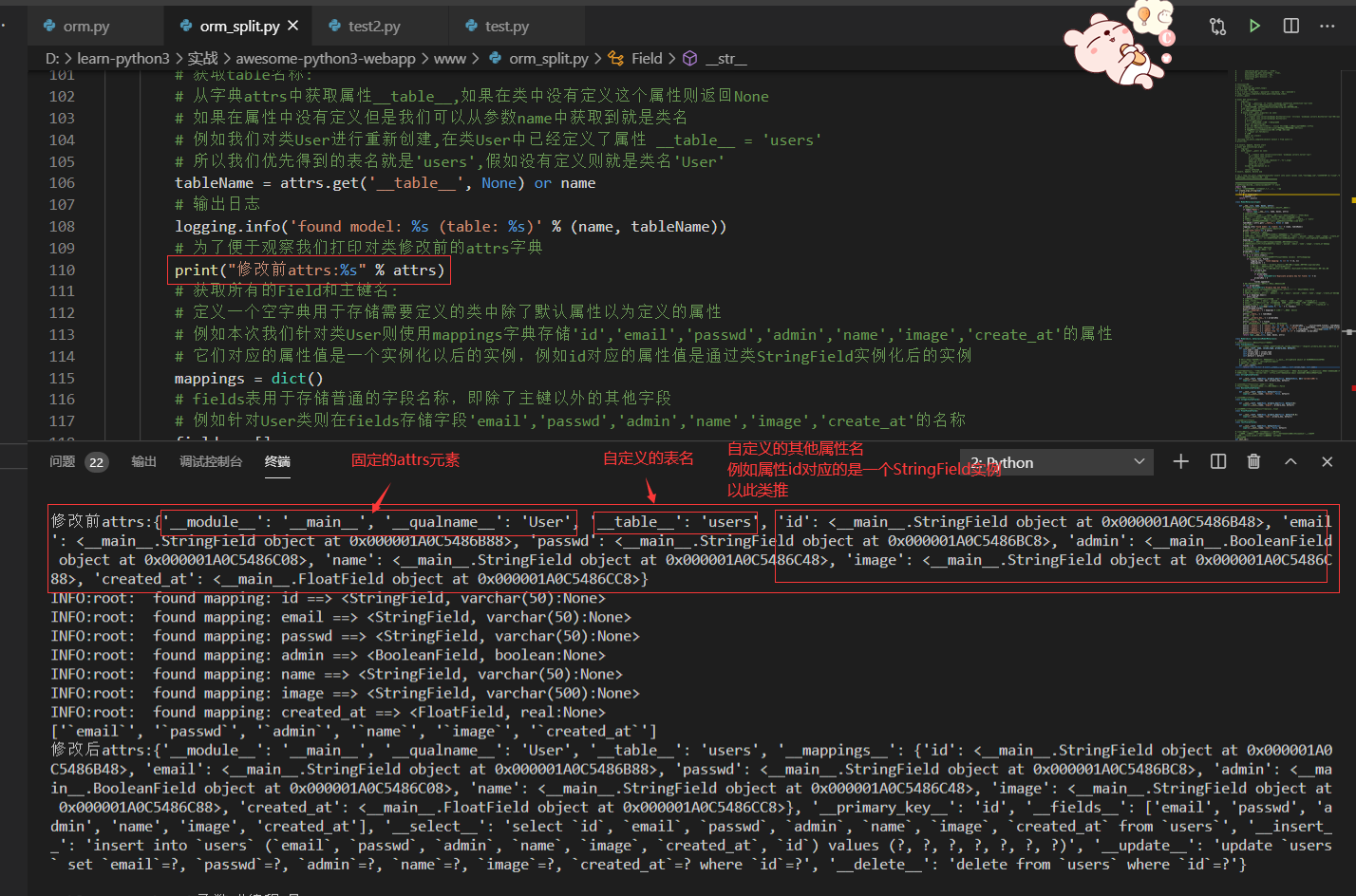
在类Field中定义的__str__方法中输出self.name属性因为默认都设置为None了,在这里输出都为None没有实际意义,我们可以修改一下改成输出default属性即该字段默认是值
def __str__(self):
return '<%s, %s:%s>' % (self.__class__.__name__, self.column_type, self.default)
在看输出
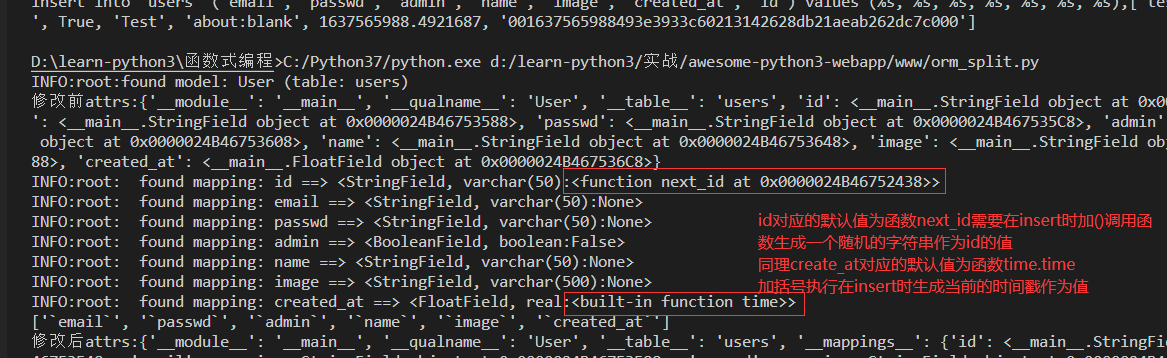
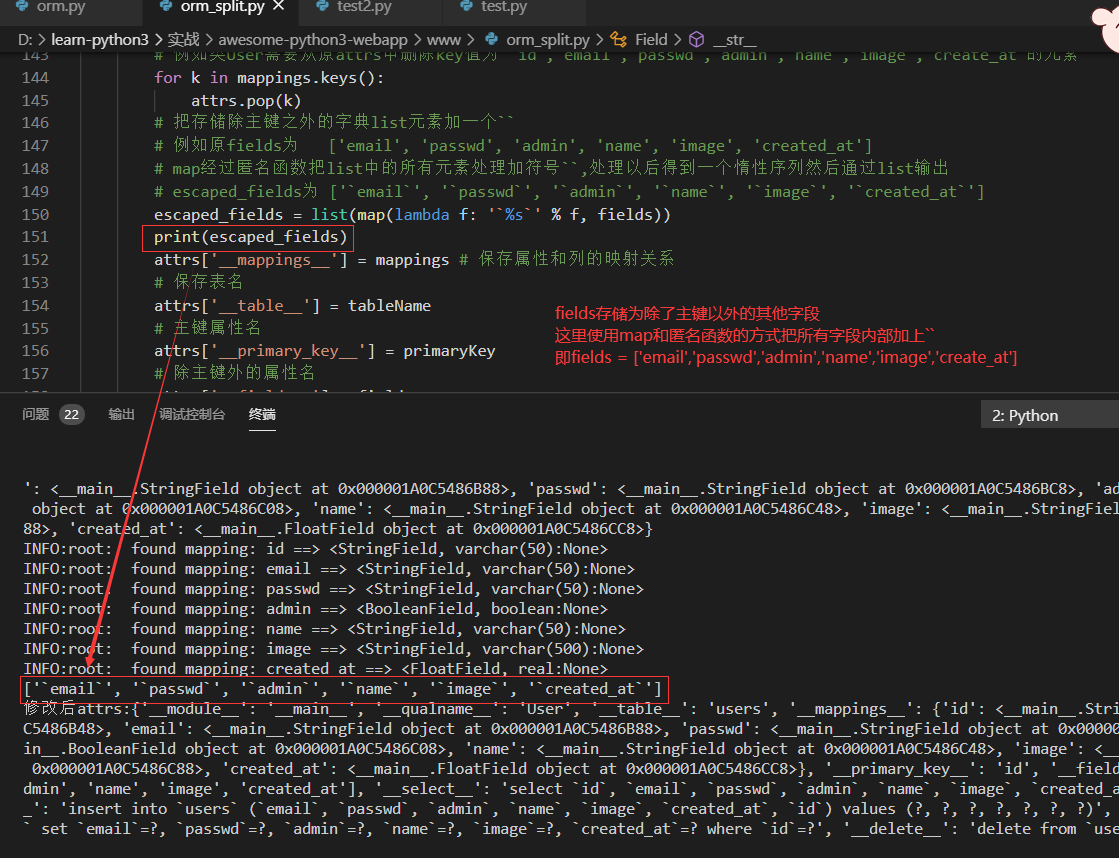
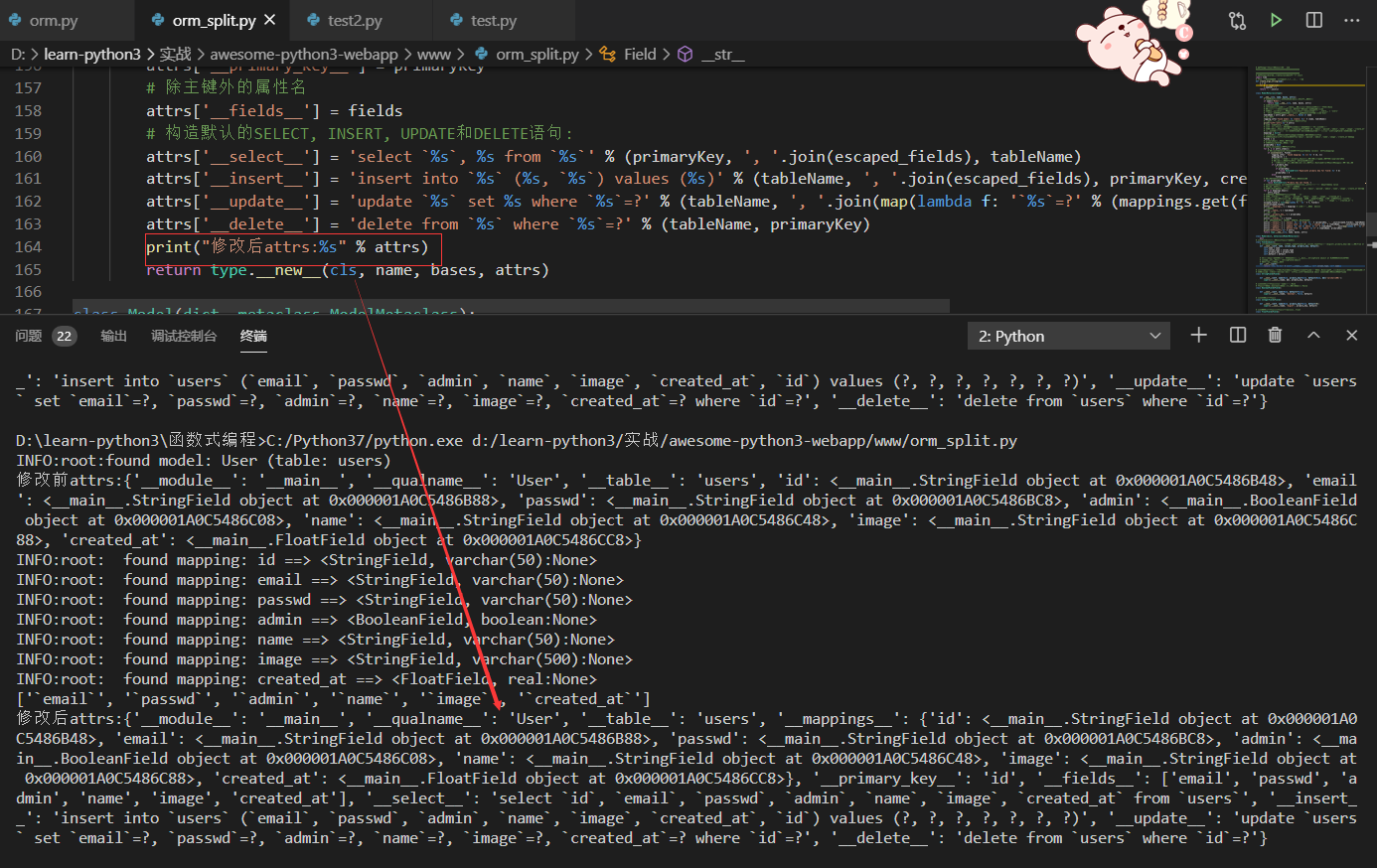
对比修改前后的attrs发现有什么变化
- 使用'__mappings__'存储所有自定义的属性id passwd等
- 使用'__primary_key__'存储主键属性'id'
- 使用'__fields__'存储除了主键以外的其他字段名['email', 'passwd', 'admin', 'name', 'image', 'created_at']
- 使用'__select__'存储select语句 'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`'
- 使用'__insert__'存储inset语句 'insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (?, ?, ?, ?, ?, ?, ?)'
- 使用'__update__'存储update语句'update `users` set `email`=?, `passwd`=?, `admin`=?, `name`=?, `image`=?, `created_at`=? where `id`=?'
- 使用'__delete__'存储delete语句'delete from `users` where `id`=?'
2,拆分解析往类Model添加方法
首先我们添加对数据库的修改操作方法,为什么先看修改操作的方法呢,因为修改操作参数相对查询操作的参数简单一些
①添加save update remove方法
相当于添加数据库的插入(insert),更新(update),删除(delete)方法,当一个实例调用对应的方法时,相当于往数据库插入,修改,删除数据
首先我们添加save()方法
代码如下
orm_split.py
############################################
# 拆分解析往类Model添加方法save update remove start
import time,uuid
# 根据传递的整数生成一个字符串?,?,?...用于占位符
def create_args_string(num):
L = []
for n in range(num):
L.append('?')
return ', '.join(L)
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
# 排除Model类本身,即针对Model不做任何修改原样返回:
if name=='Model':
return type.__new__(cls, name, bases, attrs)
# 获取table名称:
# 从字典attrs中获取属性__table__,如果在类中没有定义这个属性则返回None
# 如果在属性中没有定义但是我们可以从参数name中获取到就是类名
# 例如我们对类User进行重新创建,在类User中已经定义了属性 __table__ = 'users'
# 所以我们优先得到的表名就是'users',假如没有定义则就是类名'User'
tableName = attrs.get('__table__', None) or name
# 输出日志
logging.info('found model: %s (table: %s)' % (name, tableName))
# 为了便于观察我们打印对类修改前的attrs字典
print("修改前attrs:%s" % attrs)
# 获取所有的Field和主键名:
# 定义一个空字典用于存储需要定义的类中除了默认属性以为定义的属性
# 例如本次我们针对类User则使用mappings字典存储'id','email','passwd','admin','name','image','create_at'的属性
# 它们对应的属性值是一个实例化以后的实例,例如id对应的属性值是通过类StringField实例化后的实例
mappings = dict()
# fields表用于存储普通的字段名称,即除了主键以外的其他字段
# 例如针对User类则在fields存储字段'email','passwd','admin','name','image','create_at'的名称
fields = []
# primaryKey用于存储主键字段名
# 例如针对类User的主键名为'id'
primaryKey = None
# 以key,value的方式遍历attrs字典
for k, v in attrs.items():
# 如果对应的value是Field的子集则把对应的key value追加至字典mappings
if isinstance(v, Field):
logging.info(' found mapping: %s ==> %s' % (k, v))
mappings[k] = v
# 然后通过实例的属性primary_key去找主键,如果找到了主键则赋值给primaryKey
# 如果不是主键的字段则追加至fields这个list
# 一个表只能有一个主键,如果有多个主键则抛出RuntimeError错误,错误提示为重复的主键
if v.primary_key:
# 找到主键:
if primaryKey:
raise RuntimeError('Duplicate primary key for field: %s' % k)
primaryKey = k
else:
fields.append(k)
# 如果表内没有定义主键则抛出错误主键没有发现
if not primaryKey:
raise RuntimeError('Primary key not found.')
# 已经把对应的key value存储至字典以后,从原attrs中属性中删除对应的key value
# 如果不删除则类属性和实例属性会冲突
# 例如类User需要从原attrs中删除key值为 'id','email','passwd','admin','name','image','create_at'的元素
for k in mappings.keys():
attrs.pop(k)
# 把存储除主键之外的字典list元素加一个``
# 例如原fields为 ['email', 'passwd', 'admin', 'name', 'image', 'created_at']
# map经过匿名函数把list中的所有元素处理加符号``,处理以后得到一个惰性序列然后通过list输出
# escaped_fields为 ['`email`', '`passwd`', '`admin`', '`name`', '`image`', '`created_at`']
escaped_fields = list(map(lambda f: '`%s`' % f, fields))
print(escaped_fields)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
# 保存表名
attrs['__table__'] = tableName
# 主键属性名
attrs['__primary_key__'] = primaryKey
# 除主键外的属性名
attrs['__fields__'] = fields
# 构造默认的SELECT, INSERT, UPDATE和DELETE语句:
attrs['__select__'] = 'select `%s`, %s from `%s`' % (primaryKey, ', '.join(escaped_fields), tableName)
attrs['__insert__'] = 'insert into `%s` (%s, `%s`) values (%s)' % (tableName, ', '.join(escaped_fields), primaryKey, create_args_string(len(escaped_fields) + 1))
attrs['__update__'] = 'update `%s` set %s where `%s`=?' % (tableName, ', '.join(map(lambda f: '`%s`=?' % (mappings.get(f).name or f), fields)), primaryKey)
attrs['__delete__'] = 'delete from `%s` where `%s`=?' % (tableName, primaryKey)
print("修改后attrs:%s" % attrs)
return type.__new__(cls, name, bases, attrs)
class Model(dict, metaclass=ModelMetaclass):
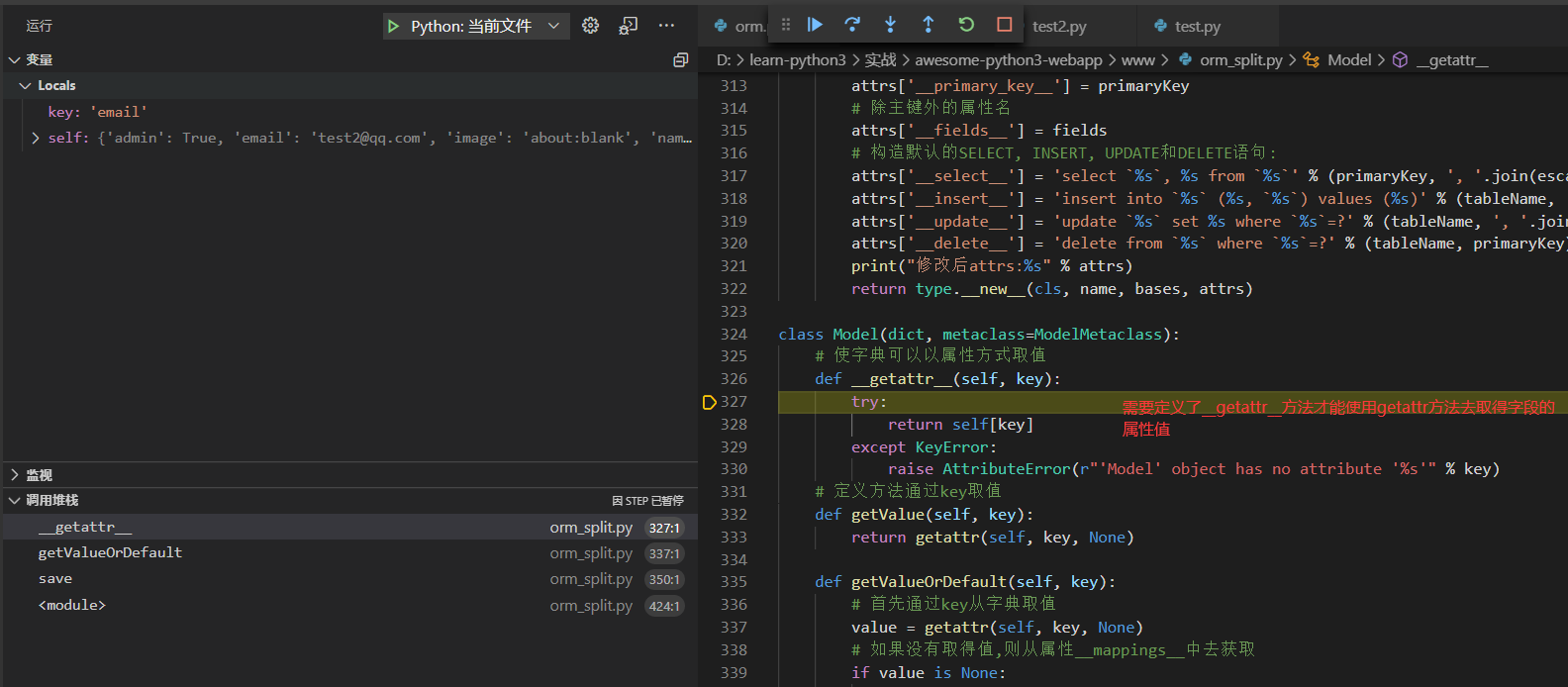
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
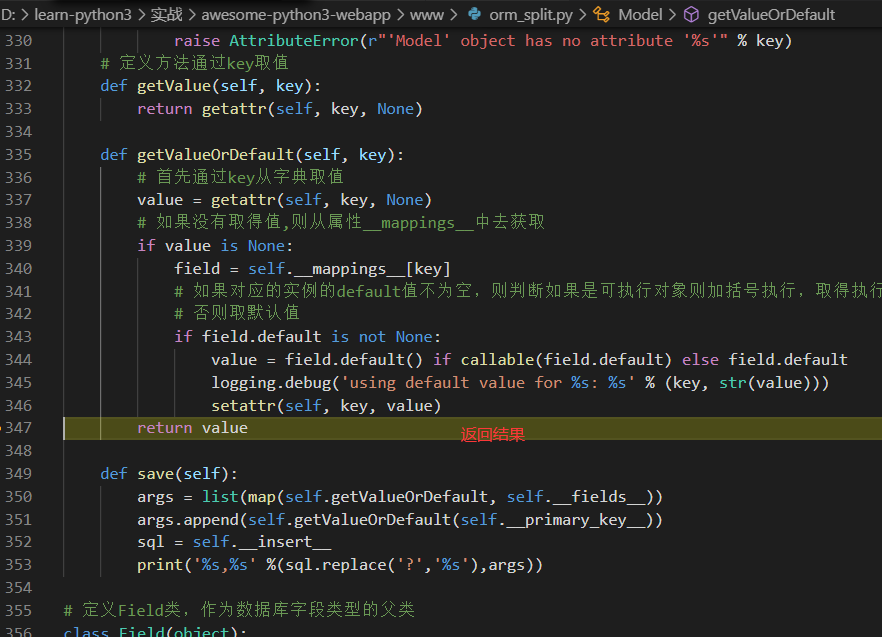
def getValue(self, key):
return getattr(self, key, None)
def getValueOrDefault(self, key):
value = getattr(self, key, None)
if value is None:
field = self.__mappings__[key]
if field.default is not None:
value = field.default() if callable(field.default) else field.default
logging.debug('using default value for %s: %s' % (key, str(value)))
setattr(self, key, value)
return value
def save(self):
args = list(map(self.getValueOrDefault, self.__fields__))
args.append(self.getValueOrDefault(self.__primary_key__))
sql = self.__insert__
print('%s,%s' %(sql.replace('?','%s'),args))
# 定义Field类,作为数据库字段类型的父类
class Field(object):
# 初始化方法定义了4个属性,分别为name字段名(id),column_type字段属性(bigint),primary_key是否为主键(True or False),default默认值
def __init__(self, name, column_type, primary_key, default):
self.name = name
self.column_type = column_type
self.primary_key = primary_key
self.default = default
# 返回实例对象的时候好看一点默认返回为 <__main__.StringField object at 0x0000025CC313EF08>
# 定义了__str__返回为 <StringField:email>
# 可以省略使用默认也可以
def __str__(self):
return '<%s, %s:%s>' % (self.__class__.__name__, self.column_type, self.default)
# 定义字符串字段类,继承父类Field的初始化方法,name字段名属性默认为None,到时使用类User创建出来的实例的key就是字段名
# 例如创建了一个User实例,该实例是一个字典,它包含的key有id email name等就是数据库表的字段名
class StringField(Field):
def __init__(self, name=None, primary_key=False, default=None, ddl='varchar(100)'):
super().__init__(name, ddl, primary_key, default)
# 定义布尔类型字段类,通过name属性为None
# 字段类型默认为boolean,默认为非主键,默认值为False
class BooleanField(Field):
def __init__(self, name=None, default=False):
super().__init__(name, 'boolean', False, default)
# 定义整数类型字段类
class IntegerField(Field):
def __init__(self, name=None, primary_key=False, default=0):
super().__init__(name, 'bigint', primary_key, default)
# 定义浮点类型字段类,字段类型real相当于float
class FloatField(Field):
def __init__(self, name=None, primary_key=False, default=0.0):
super().__init__(name, 'real', primary_key, default)
# 定义文本类型字段类
class TextField(Field):
def __init__(self, name=None, default=None):
super().__init__(name, 'text', False, default)
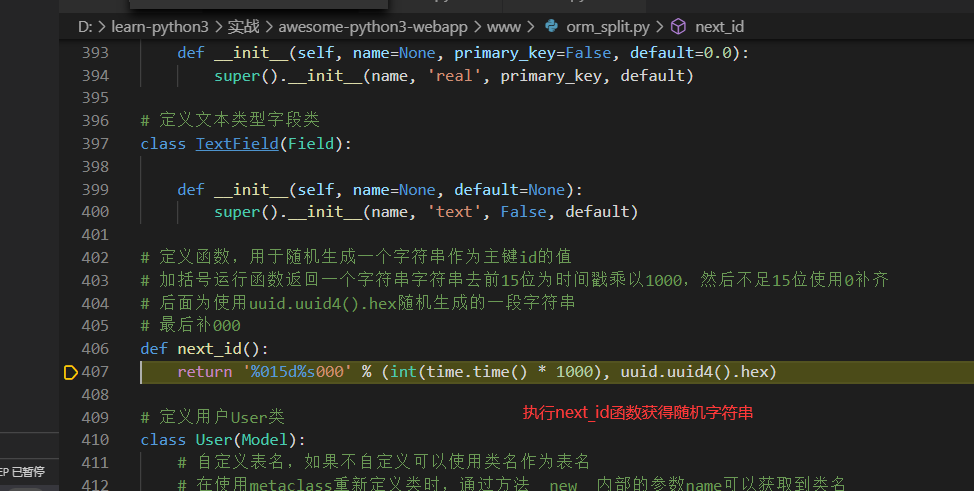
# 定义函数,用于随机生成一个字符串作为主键id的值
# 加括号运行函数返回一个字符串字符串去前15位为时间戳乘以1000,然后不足15位使用0补齐
# 后面为使用uuid.uuid4().hex随机生成的一段字符串
# 最后补000
def next_id():
return '%015d%s000' % (int(time.time() * 1000), uuid.uuid4().hex)
# 定义用户User类
class User(Model):
# 自定义表名,如果不自定义可以使用类名作为表名
# 在使用metaclass重新定义类时,通过方法__new__内部的参数name可以获取到类名
__table__ = 'users'
# 定义字段名,id作为主键
id = StringField(primary_key=True, default=next_id, ddl='varchar(50)')
email = StringField(ddl='varchar(50)')
passwd = StringField(ddl='varchar(50)')
admin = BooleanField()
name = StringField(ddl='varchar(50)')
image = StringField(ddl='varchar(500)')
created_at = FloatField(default=time.time)
u = User(name='Test', email='test2@qq.com', passwd='1234567890', image='about:blank',admin=True)
u.save()
# 拆分解析往类Model添加方法save update remove end
#$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
运行输出如下
INFO:root:found model: User (table: users)
修改前attrs:{'__module__': '__main__', '__qualname__': 'User', '__table__': 'users', 'id': <__main__.StringField object at 0x0000024B46753548>, 'email': <__main__.StringField object at 0x0000024B46753588>, 'passwd': <__main__.StringField object at 0x0000024B467535C8>, 'admin': <__main__.BooleanField object at 0x0000024B46753608>, 'name': <__main__.StringField object at 0x0000024B46753648>, 'image': <__main__.StringField object at 0x0000024B46753688>, 'created_at': <__main__.FloatField object at 0x0000024B467536C8>}
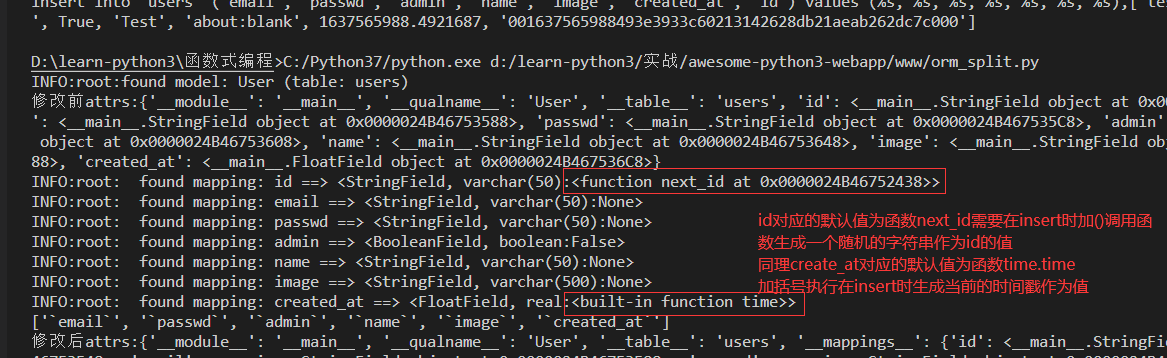
INFO:root: found mapping: id ==> <StringField, varchar(50):<function next_id at 0x0000024B46752438>>
INFO:root: found mapping: email ==> <StringField, varchar(50):None>
INFO:root: found mapping: passwd ==> <StringField, varchar(50):None>
INFO:root: found mapping: admin ==> <BooleanField, boolean:False>
INFO:root: found mapping: name ==> <StringField, varchar(50):None>
INFO:root: found mapping: image ==> <StringField, varchar(500):None>
INFO:root: found mapping: created_at ==> <FloatField, real:<built-in function time>>
['`email`', '`passwd`', '`admin`', '`name`', '`image`', '`created_at`']
修改后attrs:{'__module__': '__main__', '__qualname__': 'User', '__table__': 'users', '__mappings__': {'id': <__main__.StringField object at 0x0000024B46753548>, 'email': <__main__.StringField object at 0x0000024B46753588>, 'passwd': <__main__.StringField object at 0x0000024B467535C8>, 'admin': <__main__.BooleanField object at 0x0000024B46753608>, 'name': <__main__.StringField object at 0x0000024B46753648>, 'image': <__main__.StringField object at 0x0000024B46753688>, 'created_at': <__main__.FloatField object at 0x0000024B467536C8>}, '__primary_key__': 'id', '__fields__': ['email', 'passwd', 'admin', 'name', 'image', 'created_at'], '__select__': 'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', '__insert__': 'insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (?, ?, ?, ?, ?, ?, ?)', '__update__': 'update `users` set `email`=?, `passwd`=?, `admin`=?, `name`=?, `image`=?, `created_at`=? where `id`=?', '__delete__': 'delete from `users` where `id`=?'}
insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (%s, %s, %s, %s, %s, %s, %s),['test2@qq.com', '1234567890', True, 'Test', 'about:blank', 1637566362.3296351, '001637566362329a9a4f4f3cd12475ba1cc45d8cae38b09000']
解析
针对metaclass对类User的解析在上一个例子已经解释过了,这里我们只是把生成的sql语句和对应的参数args打印出来,并没有执行对数据的实际操作
下面我们来分析sql语句和对应参数args的生成过程,当我们实例化出来u以后调用save()方法
def save(self):
args = list(map(self.getValueOrDefault, self.__fields__))
args.append(self.getValueOrDefault(self.__primary_key__))
sql = self.__insert__
print('%s,%s' %(sql.replace('?','%s'),args))
首先执行
args = list(map(self.getValueOrDefault, self.__fields__))
这里使用的是高阶函数map相当于把self.__fields__列表里面的元素一一代入方法getValueOrDefault中去执行,然后把结果返回生成一个新的惰性序列,然后因为map生成的是惰性序列,使用使用list方法输出为list
原始list对应的元素为
self.__fields__ = ['email', 'passwd', 'admin', 'name', 'image', 'created_at']
我们把各个元素作为key代入以下方法遍历
def getValueOrDefault(self, key):
value = getattr(self, key, None)
if value is None:
field = self.__mappings__[key]
if field.default is not None:
value = field.default() if callable(field.default) else field.default
logging.debug('using default value for %s: %s' % (key, str(value)))
setattr(self, key, value)
return value
当遍历以下元素时
'email', 'passwd', 'admin', 'name', 'image'
直接获取字典对应的value即可
'test2@qq.com', '1234567890', True, 'Test', 'about:blank'
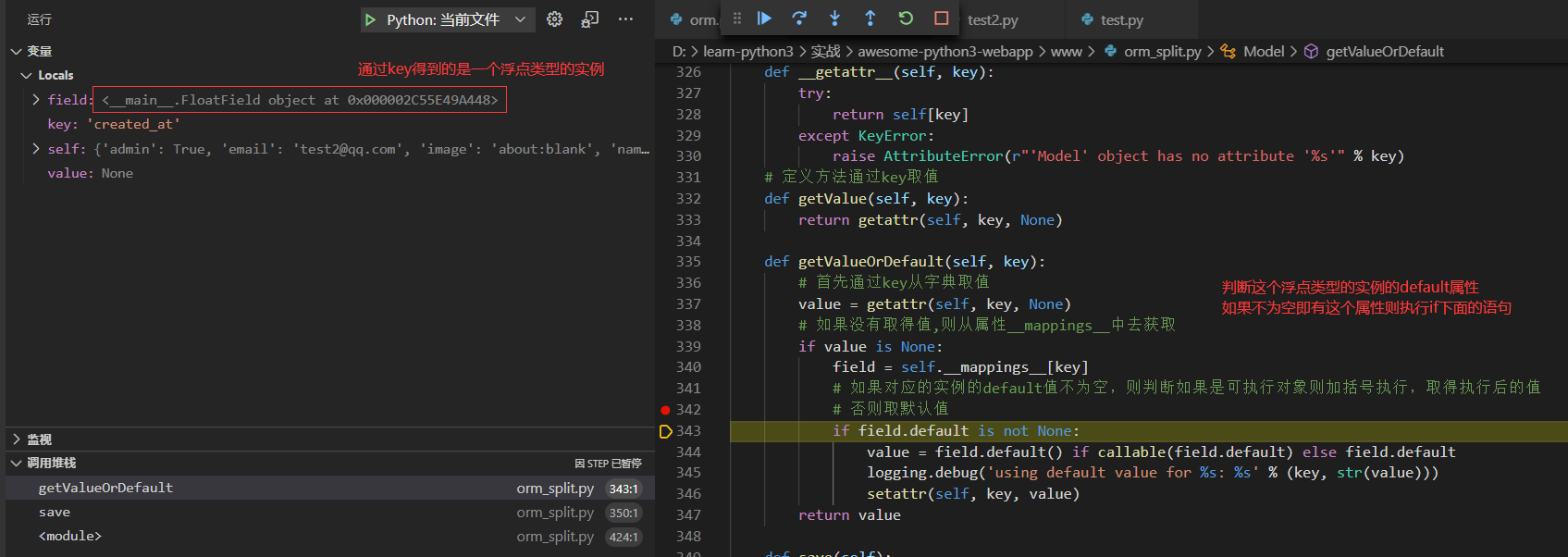
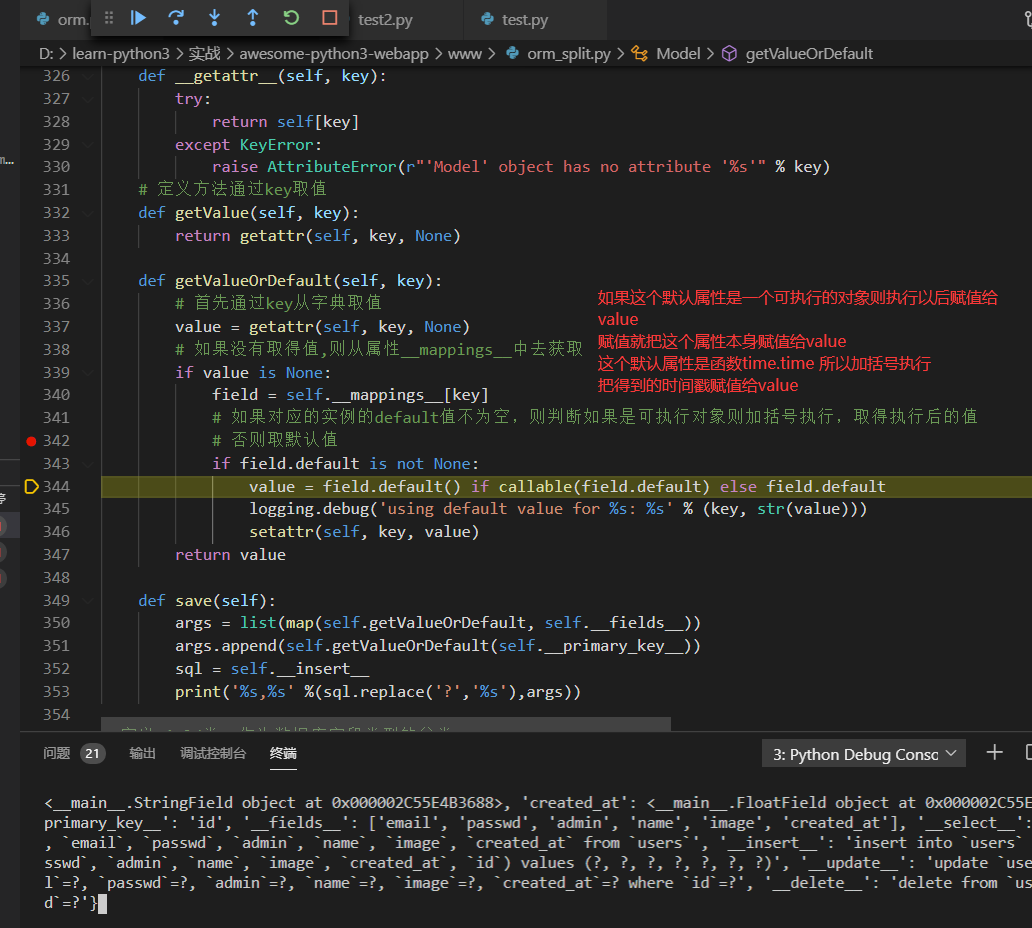
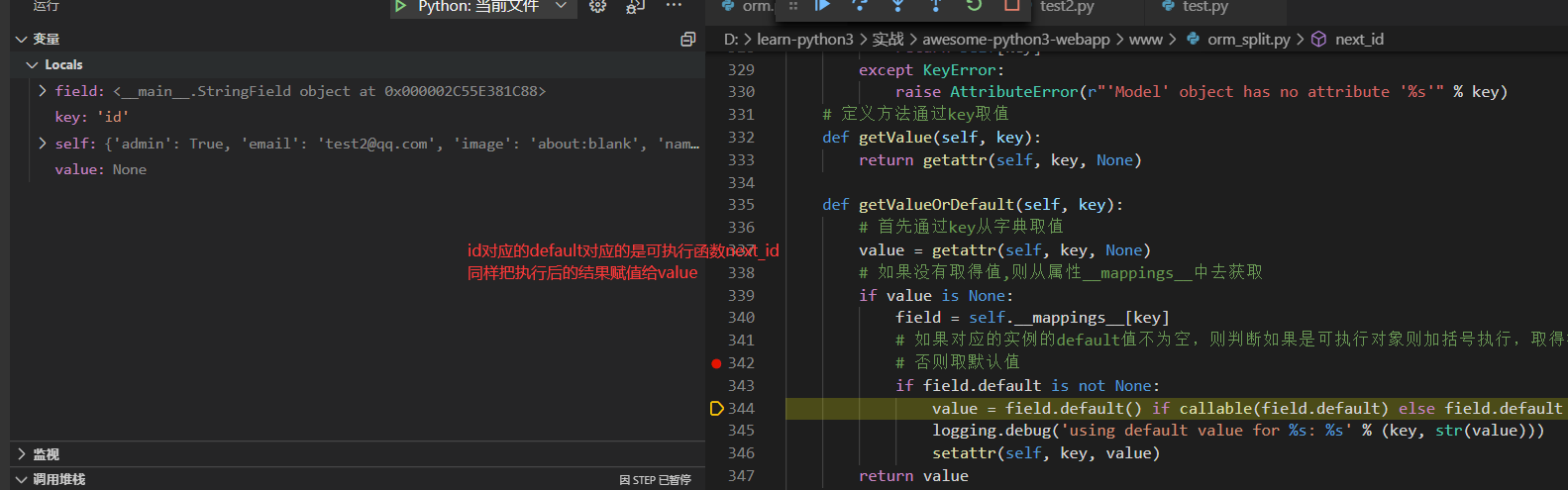
当遍历到以下元素时,对应的字典获取不到,只能从__mappings__中去获取,然后对应的default属性是一个可执行的函数,加()执行即可
'created_at'
例如我们获取created_at对应的值则相当于
u.__mappings__['created_at'].default()
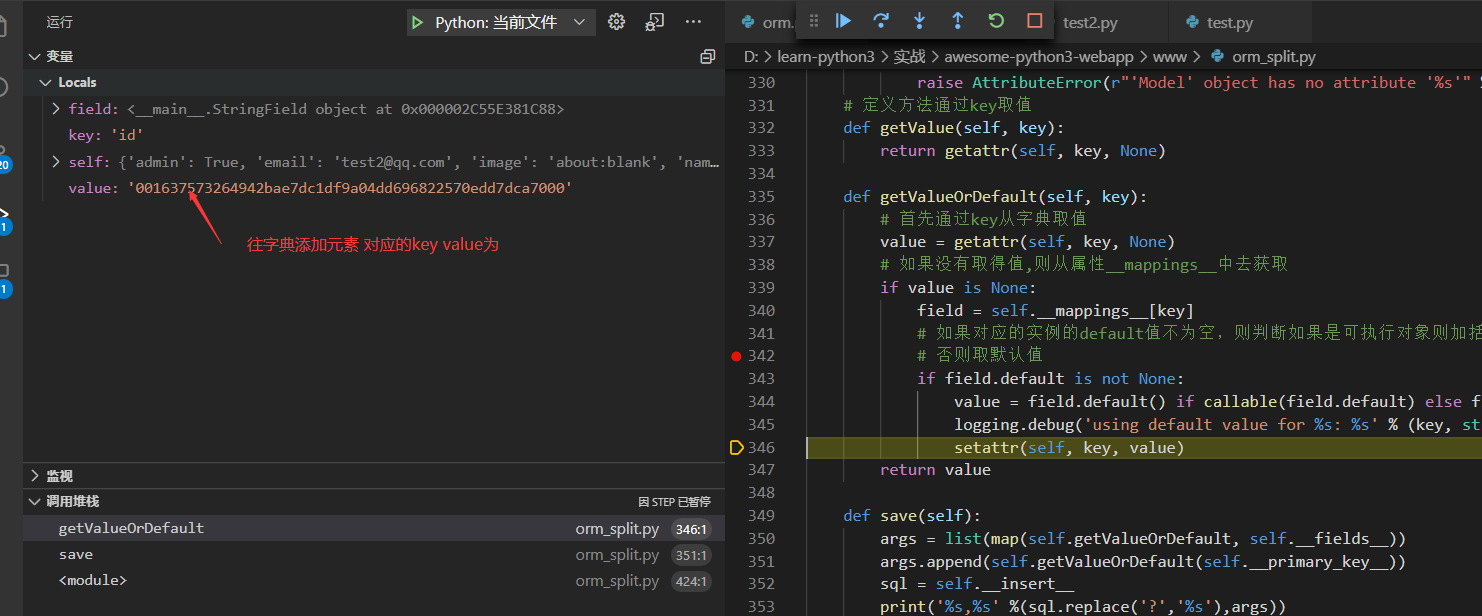
相对于执行了一次time函数得到时间戳,然后得到的args为
['test2@qq.com', '1234567890', True, 'Test', 'about:blank', 1637570070.6398582]
接下来把主键id生成值追加至args参数即可
args.append(self.getValueOrDefault(self.__primary_key__))
最后得到的args为
['test2@qq.com', '1234567890', True, 'Test', 'about:blank', 1637570070.6398582, '001637570070639ac1bf265f8aa4833abbeef27083c3c8e000']
sql直接从self.__insert__获取
'insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (?, ?, ?, ?, ?, ?, ?)'
因为MySQL的占位符为%s把?使用replace替换成%s
print('%s,%s' %(sql.replace('?','%s'),args))
所以打印输出为
insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (%s, %s, %s, %s, %s, %s, %s),['test2@qq.com', '1234567890', True, 'Test', 'about:blank', 1637570070.6398582, '001637570070639ac1bf265f8aa4833abbeef27083c3c8e000']
下面我们使用调试模式从实例调用save()方法以后查看执行过程
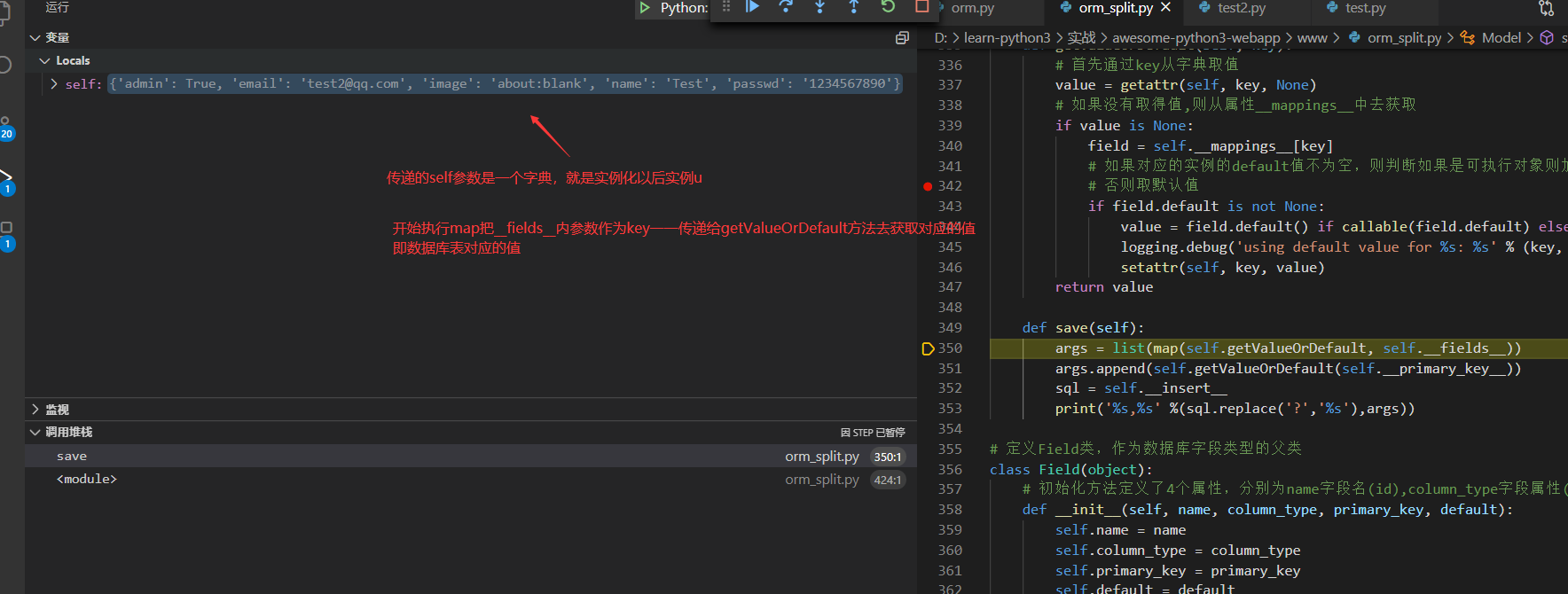
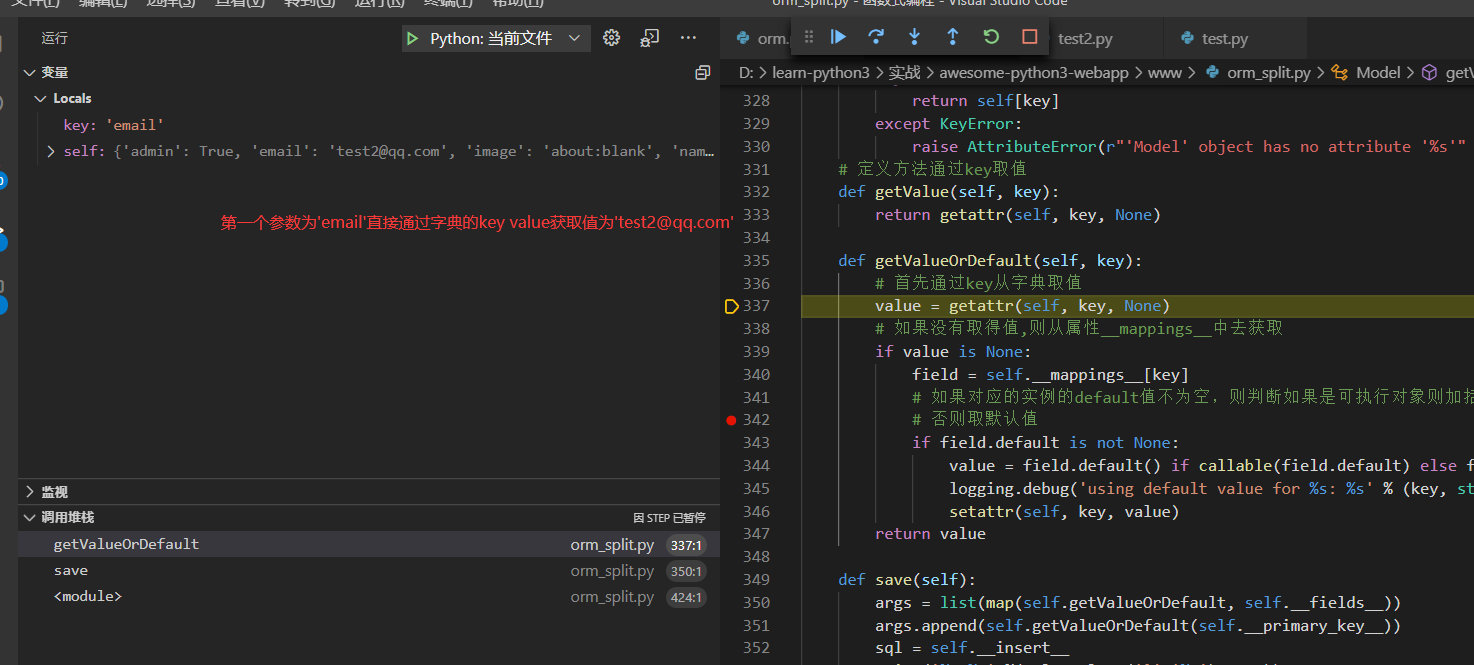
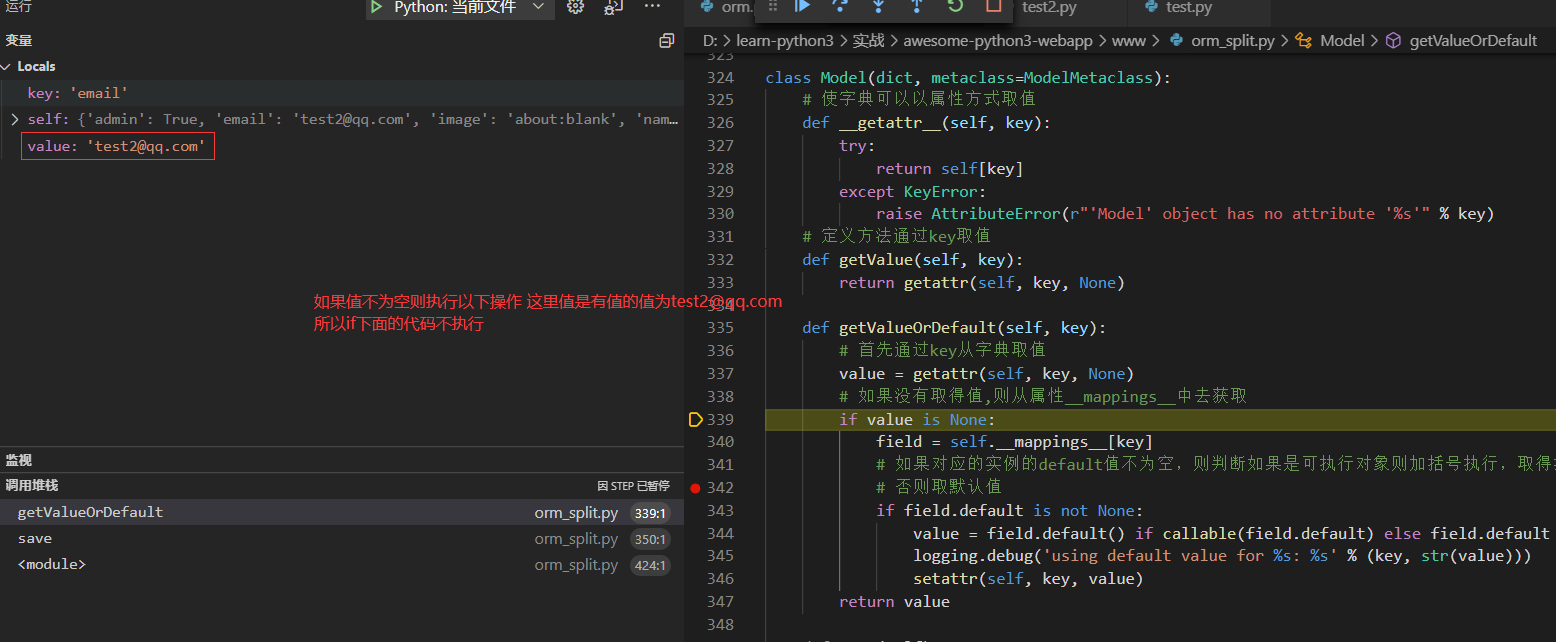
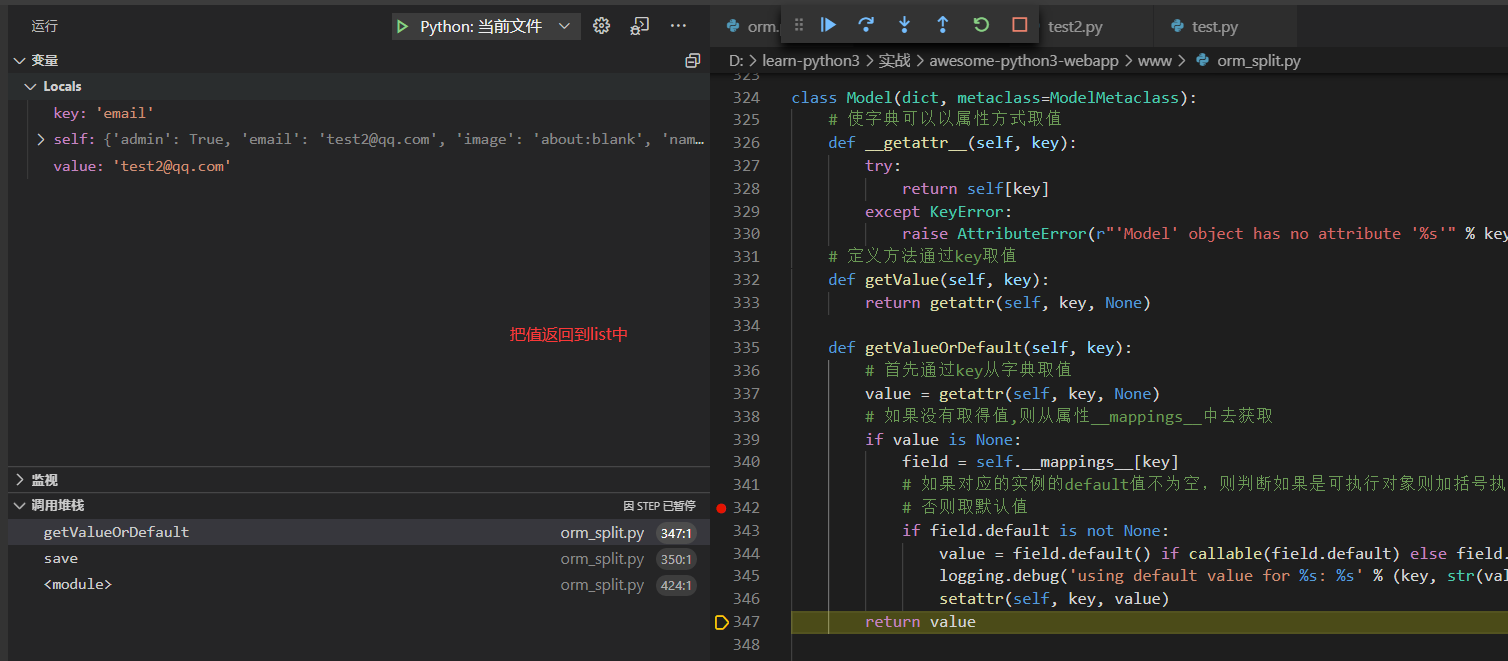
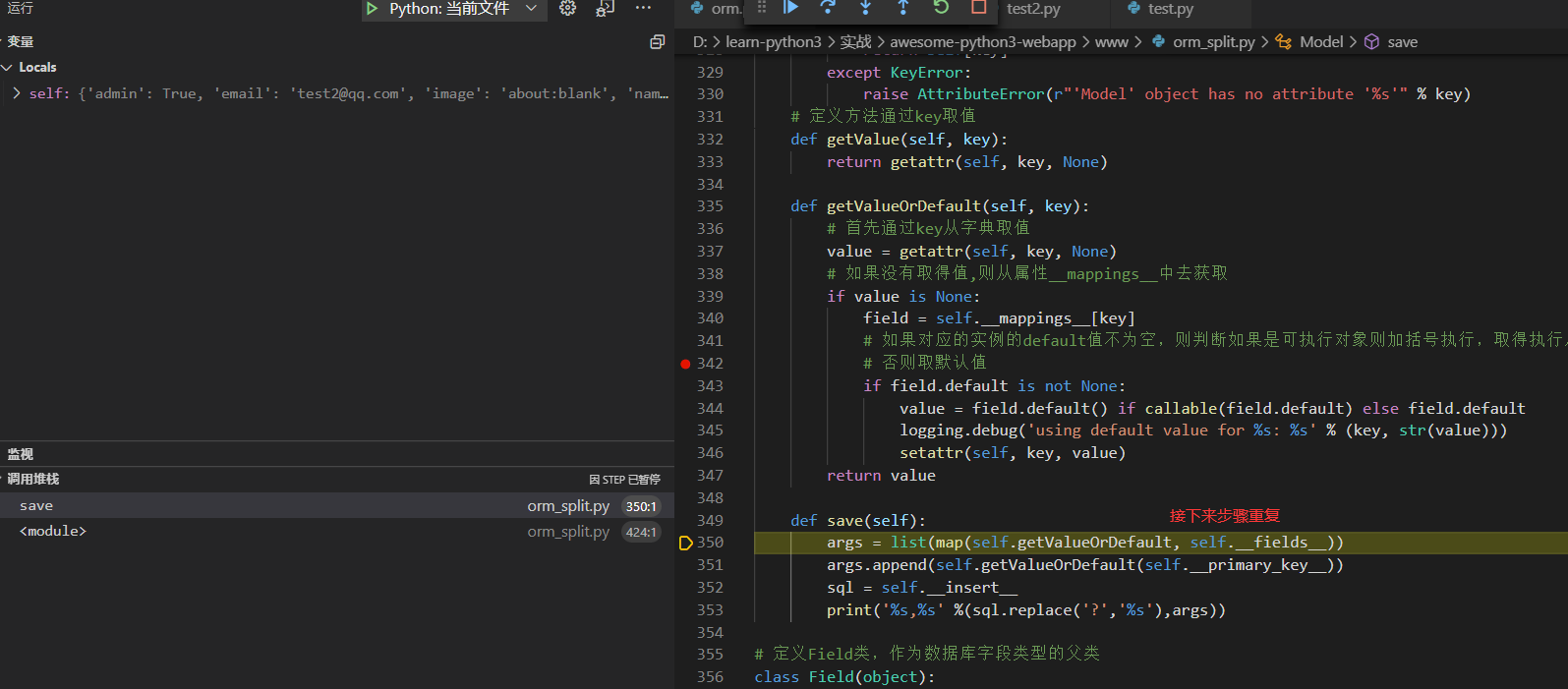
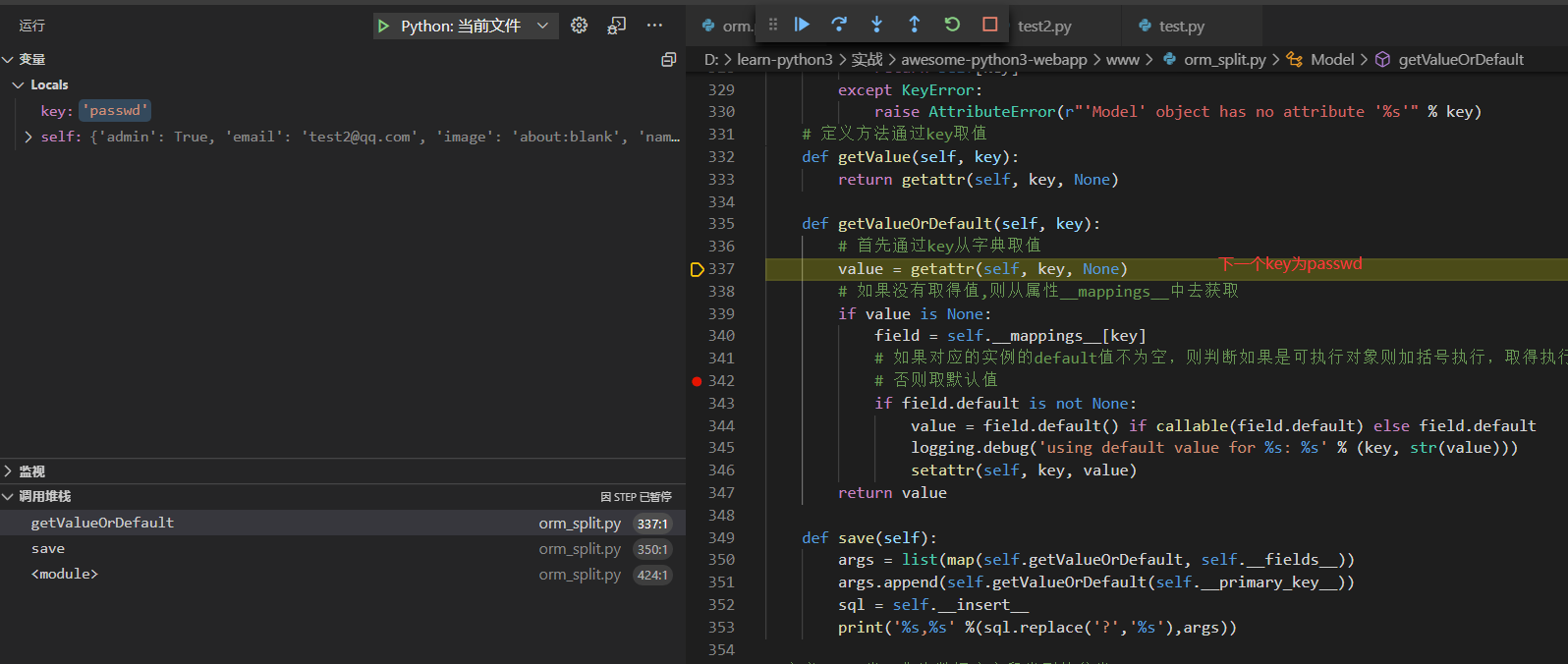
省略重复的几步分别直接从字典去的`passwd`, `admin`, `name`, `image`的值
直到key为created_at
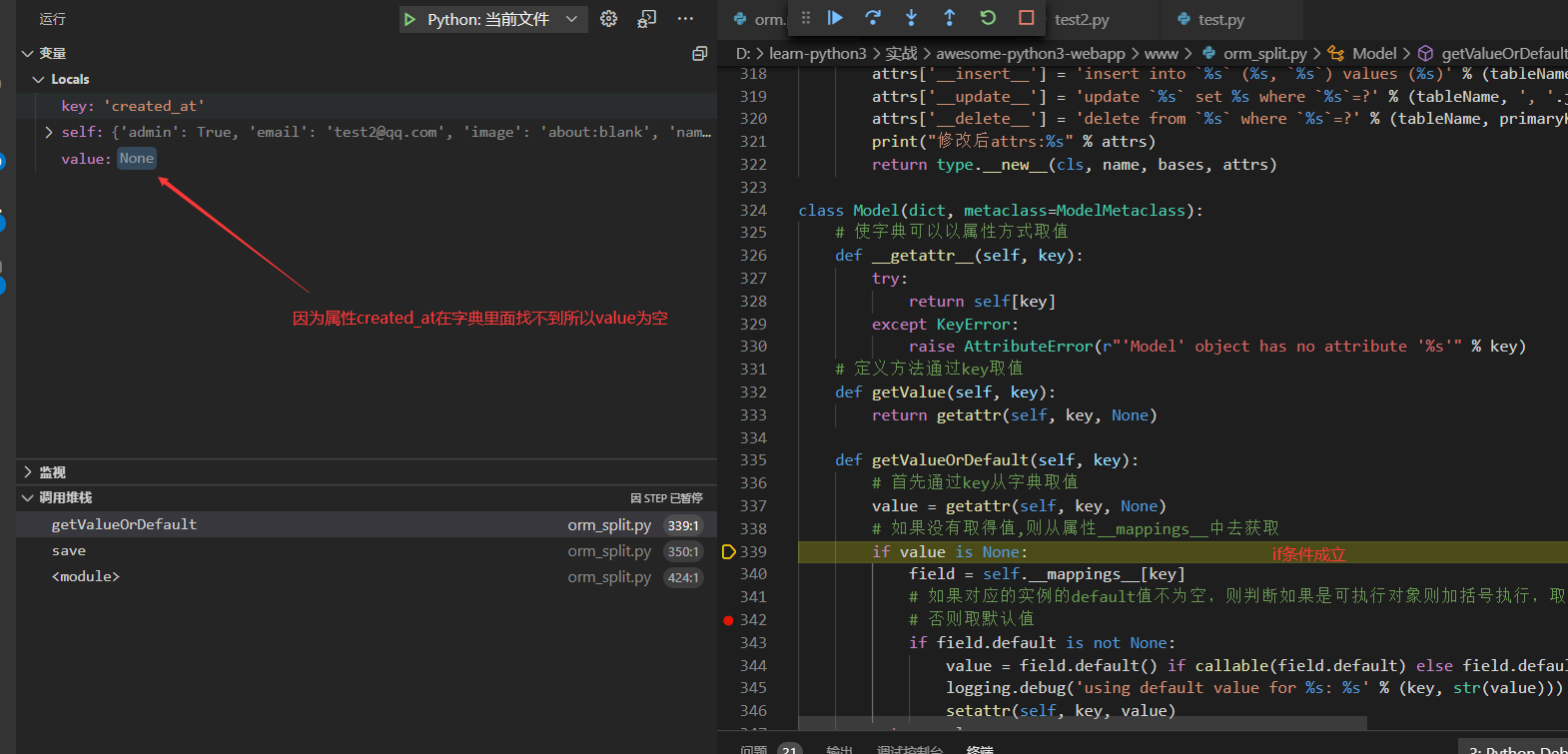
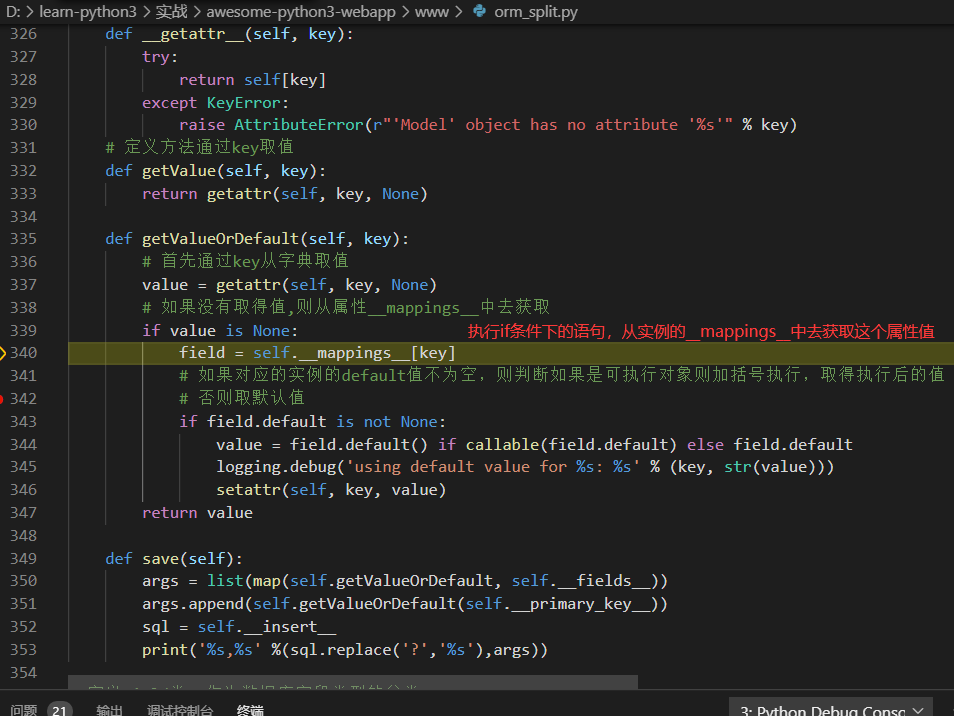
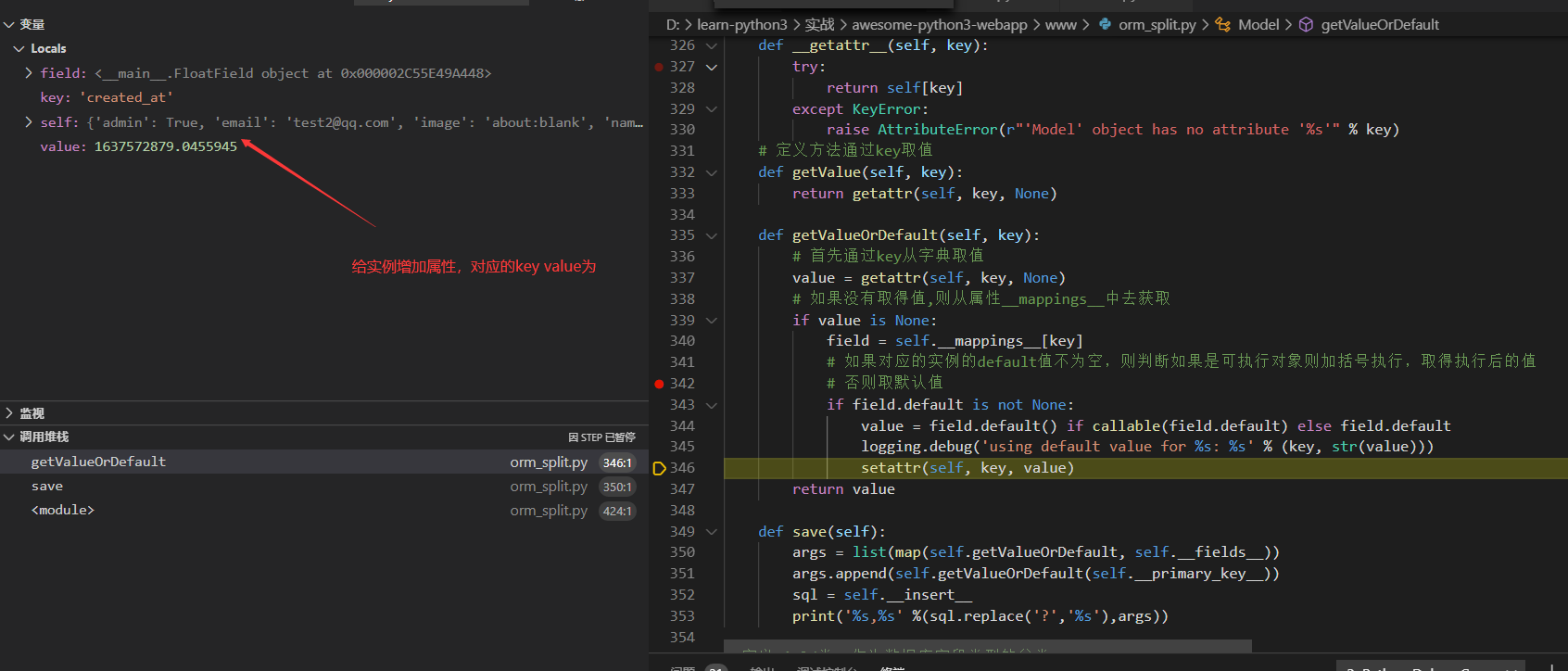
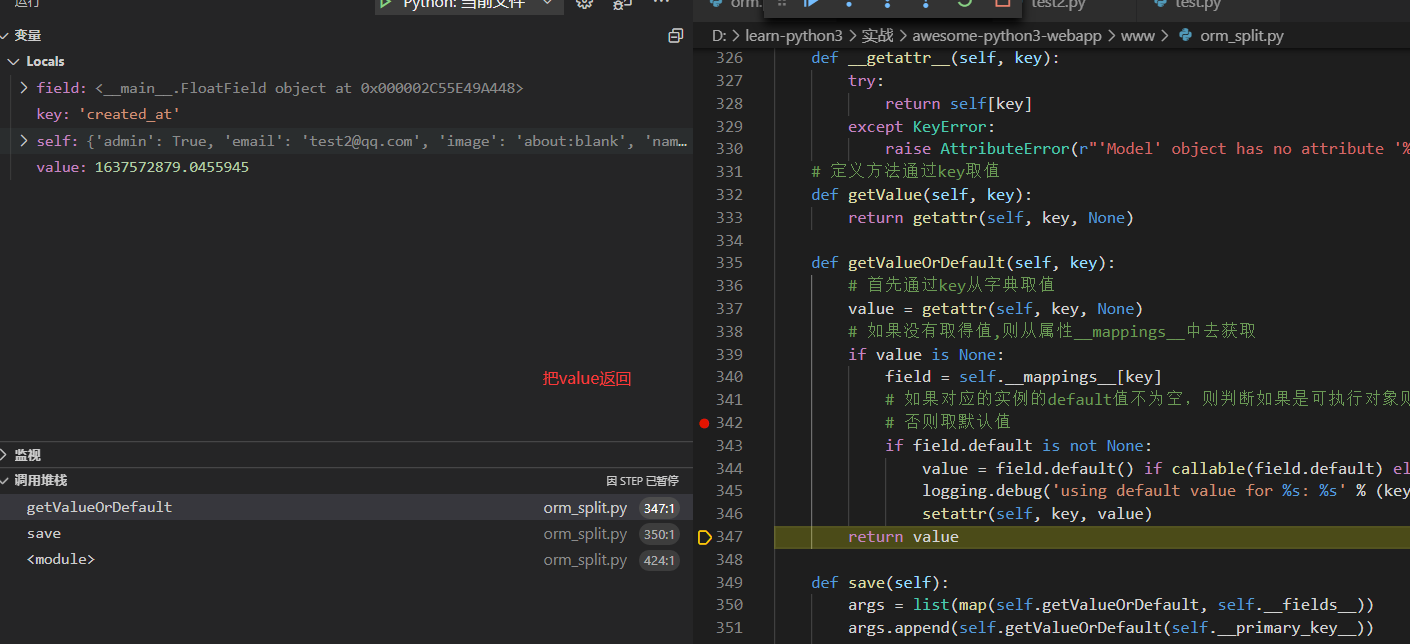
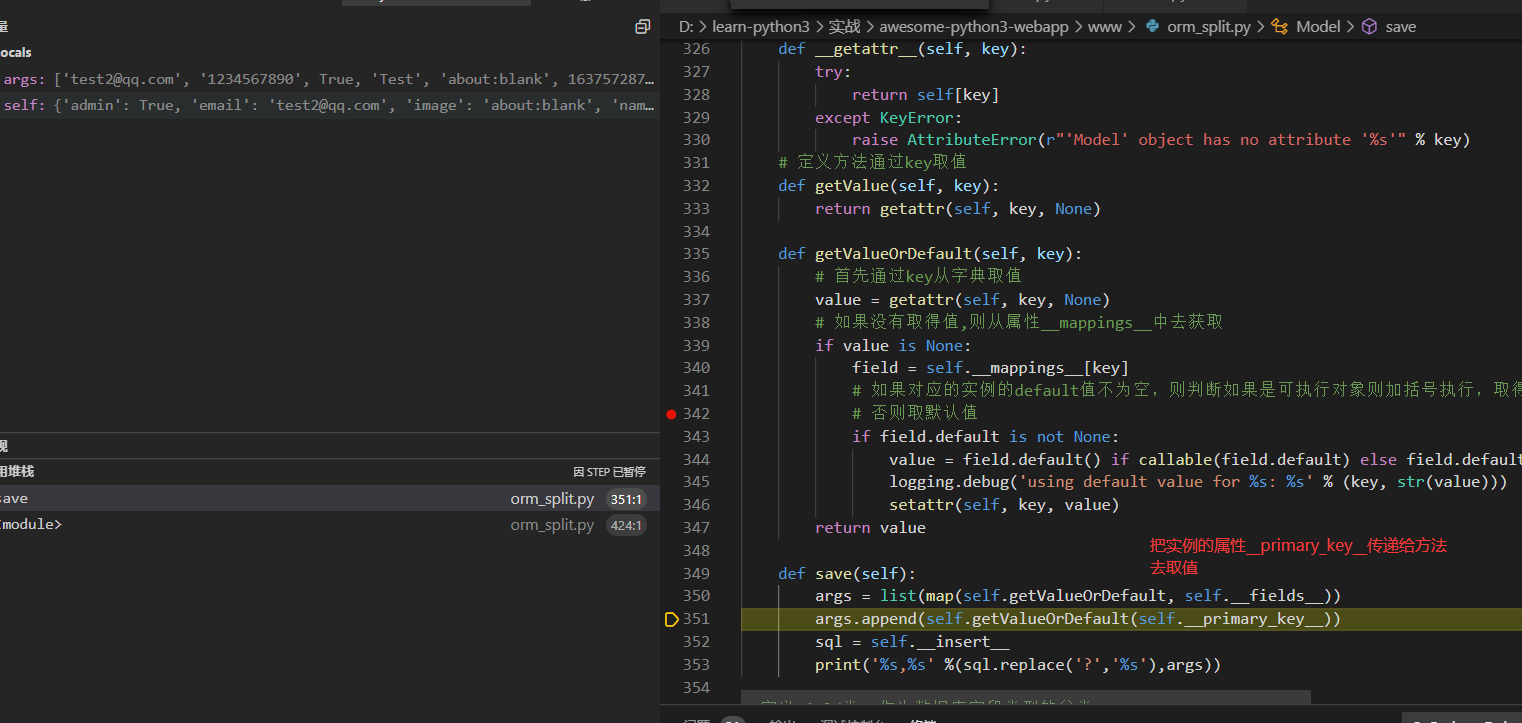
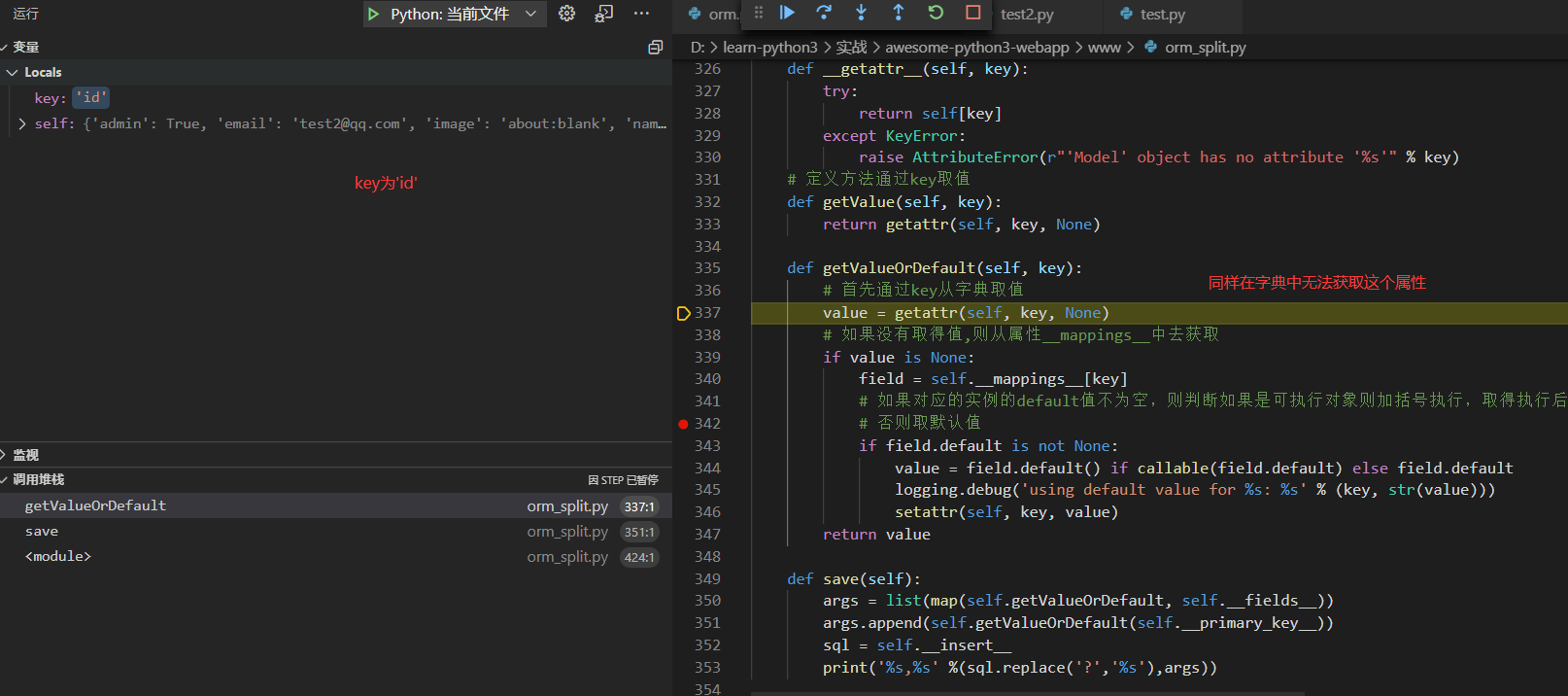
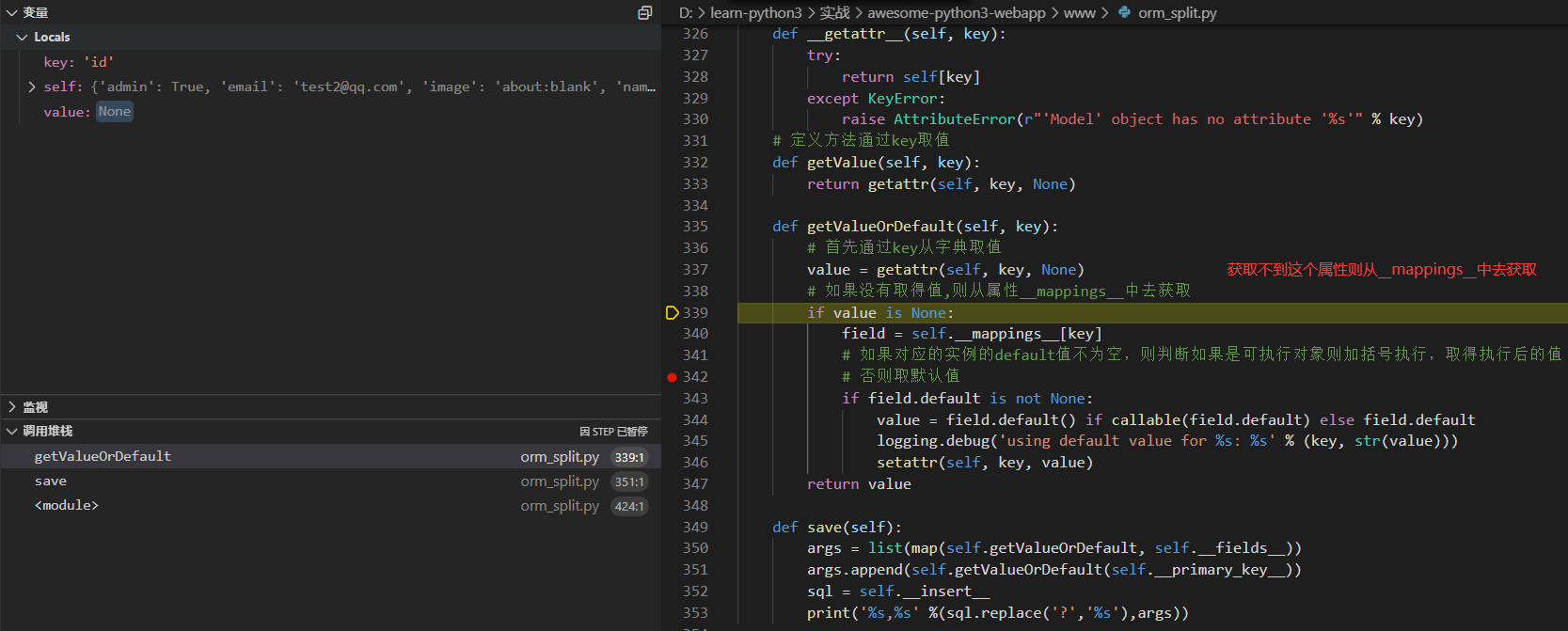
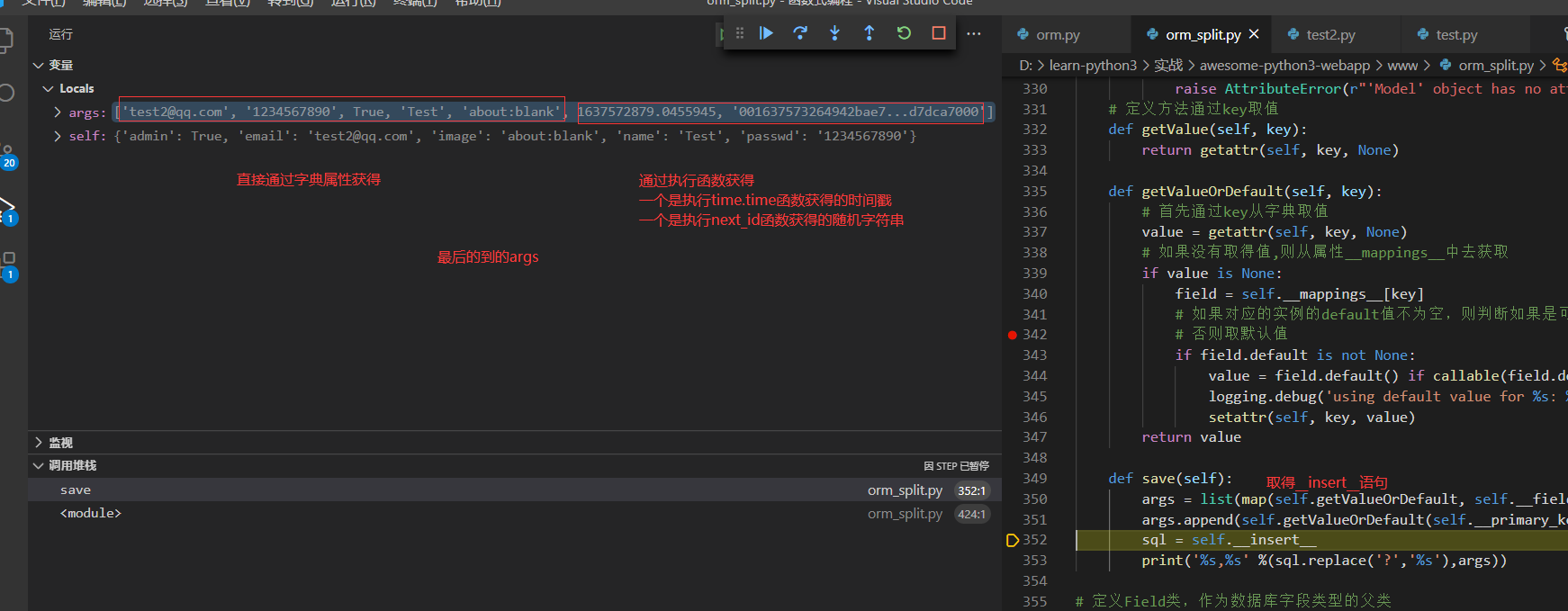
最后的打印输出如下,注意这里使用replace把?替换成%s了
insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (%s, %s, %s, %s, %s, %s, %s),['test2@qq.com', '1234567890', True, 'Test', 'about:blank', 1637573497.222869, '001637573497222ff192f5cb824488e9726d58d31b0d29f000']
如果连接了数据库,建立了连接池这执行save()方法即相当于往数据库插入一条数据
下面我们创建数据库连接池真实往数据库插入数据
orm_split.py添加一下创建数据库连接池以及使用连接池执行查询函数,和执行修改函数,为了简单一点我们先使用同步方式,而不使用异步
# 创建数据库连接池和执行insert update select函数 start
import pymysql
def create_pool(**kw):
host=kw.get('host', 'localhost')
port=kw.get('port', 3306)
user=kw['user']
password=kw['password']
db=kw['db']
# 创建全部变量,用于存储创建的连接池
global conn
conn = pymysql.connect(host=host, user=user, password=password, database=db,port=port)
# 字典存储数据库信息
kw = {'host':'localhost','user':'www-data','password':'www-data','db':'awesome'}
# 把字典传入创建连接池函数,执行即创建了全局连接池conn,可以在查询,执行等函数调用执行
create_pool(**kw)
def select(sql,args,size=None):
log(sql,args)
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql.replace('?','%s'),args or ())
if size:
rs = cursor.fetchmany(size)
else:
rs = cursor.fetchall()
cursor.close
logging.info('rows returned: %s' % len(rs))
return rs
def execute(sql,args):
cursor = conn.cursor(pymysql.cursors.DictCursor)
try:
cursor.execute(sql.replace('?','%s'),args)
rs = cursor.rowcount
cursor.close()
conn.commit()
except:
raise
return rs
# 创建数据库连接池和执行insert update select函数 end
其中查询函数select定义了默认参数size如果不输入则默认返回所有查询结果,如果传递参数例如1则返回1条结果
把执行insert,update,delete的函数统一定义为函数execute通过sql的不同来区分是插入,修改,删除操作
修改Model的save()方法,在save()方法里面调用execute函数执行sql语句
修改如下
def save(self):
args = list(map(self.getValueOrDefault, self.__fields__))
args.append(self.getValueOrDefault(self.__primary_key__))
sql = self.__insert__
print(sql,args)
rows = execute(sql,args)
print(rows)
if rows != 1:
logging.warning('failed to insert record: affected rows: %s' % rows)
我们已经通过前面的执行语句获取了sql以及对应的参数args所以直接传递给函数execute执行即可
下面我们通过实例调用save()方法
u = User(name='Test', email='test@qq.com', passwd='1234567890', image='about:blank',admin=True) u.save()
为了方便观察我们在save()方法里面定义了print打印sql,args以及执行insert语句影响的数据库条数,输出如下
insert into `users` (`email`, `passwd`, `admin`, `name`, `image`, `created_at`, `id`) values (?, ?, ?, ?, ?, ?, ?) ['test@qq.com', '1234567890', True, 'Test', 'about:blank', 1637637058.5980606, '0016376370585981a21e061a83146c49733e8c841747974000'] 1
rows是执行execute函数的返回
相当于执行了一条insert语句,影响的数据条数为1即往数据库插入一条数据
去数据库查询,可以查到我们刚刚插入的数据
mysql> select * from users; +----------------------------------------------------+-------------+------------+-------+------+-------------+------------------+ | id | email | passwd | admin | name | image | created_at | +----------------------------------------------------+-------------+------------+-------+------+-------------+------------------+ | 0016376370585981a21e061a83146c49733e8c841747974000 | test@qq.com | 1234567890 | 1 | Test | about:blank | 1637637058.59806 | +----------------------------------------------------+-------------+------------+-------+------+-------------+------------------+ 1 row in set (0.00 sec)
虽然编写orm会比较复杂,但是调用者只需要定义好一个字典然后调用save()方法就可以很容易地操作数据库
下面我们在类Model插入update()方法用于更新数据,update()方法如下
def update(self):
args = list(map(self.getValue, self.__fields__))
args.append(self.getValue(self.__primary_key__))
rows = execute(self.__update__, args)
print(self.__update__,args)
if rows != 1:
logging.warning('failed to update by primary key: affected rows: %s' % rows)
update方法和insert方法类似,不同的是update方法是在数据库中修改一条已经存在的数据,所以需要先根据关键字去查询到该条数据才能修改,而不能直接通过修改实例去修改
我们观察attrs的属性__update__
'update `users` set `email`=?, `passwd`=?, `admin`=?, `name`=?, `image`=?, `created_at`=? where `id`=?'
可以看到这里使用了关键字id进行条件匹配,所以我们使用id作为关键字查询
而attrs的__insert__属性值为
'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`
所以我们要拼接sql语句加上where id = ‘%s’
sql = '%s where `%s`=?' % (cls.__select__, cls.__primary_key__) print(sql)
拼接后的sql为
select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where `id`=?
格式化对于关系为
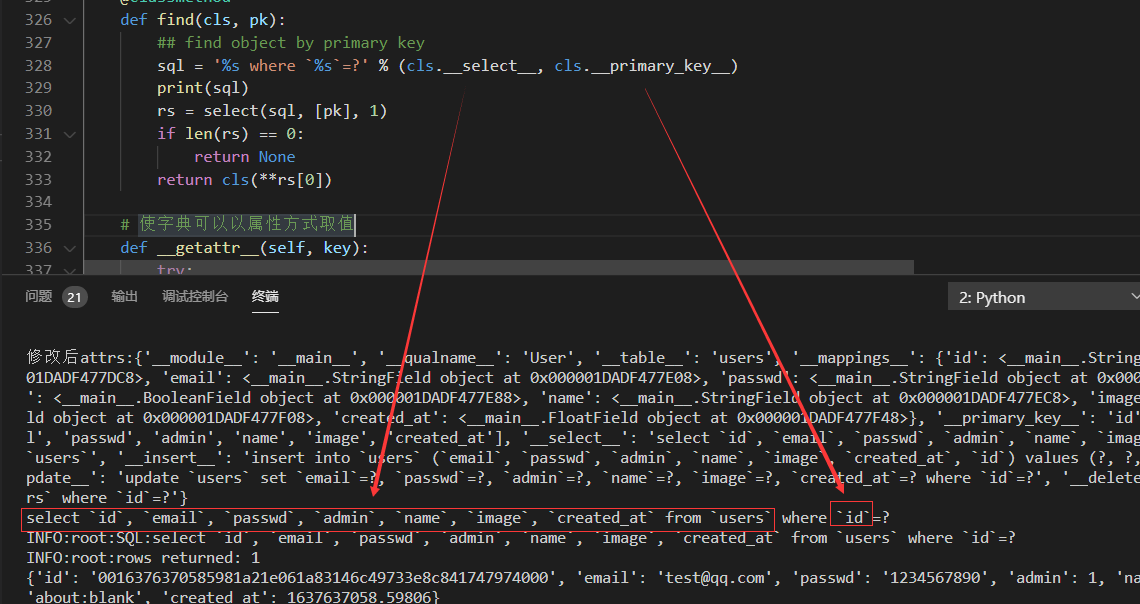
因为我们要在类内部查询对应的实例,所以需要定义类调用的方法find,传递关键字参数id进行查询
在Model内添加方法find(cls, pk)其中cls为类本身,pk为传递的关键字id的值,这个方法使用装饰器 @classmethod装饰
使用这个装饰器装饰的函数为类函数,可以通过类来调用,而不用通过实例调用,传递的第一个参数cls为类本身,和定义实例的函数self传递的参数为实例本身意思差不多
pk为查询的关键字id的值,函数select的参数size对应1代表返回一个结果,其实也可以不传递,因为id的值是根据时间戳和随机方法uuid生成的一串随机字符串,所以肯定是唯一的,结果只能是1个或者是0个
@classmethod
def find(cls, pk):
## find object by primary key
sql = '%s where `%s`=?' % (cls.__select__, cls.__primary_key__)
print(sql)
rs = select(sql, [pk], 1)
if len(rs) == 0:
return None
return cls(**rs[0])
注意:本查询函数返回为cls(**rs[0]),因为查询结果是一个list,元素为字典即数据库表内的字段和值对应关系的字典,取下标为0的元素即第一个字典,然后以字典作为参数传递给类User进行实例化,使用最后返回为一个实例,
而不能直接放rs[0]因为rs[0]是字典,字典不是实例自然也就没有对应的类方法update和remove了
下面我们通过类调用方法find去查找刚刚插入的实例
rs = User.find('0016376370585981a21e061a83146c49733e8c841747974000')
print(rs)
输出为
select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where `id`=?
INFO:root:SQL:select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where `id`=?
INFO:root:rows returned: 1
{'id': '0016376370585981a21e061a83146c49733e8c841747974000', 'email': 'test@qq.com', 'passwd': '1234567890', 'admin': 1, 'name': 'Test', 'image':
'about:blank', 'created_at': 1637637058.59806}
我们找到一条结果,结果就是一个实例
下面我们修改这个实例的一个属性例如修改email,然后再调用update()方法进行更新
rs.email = 'test2@qq.com' rs.update()
输出如下
INFO:root:rows returned: 1 update `users` set `email`=?, `passwd`=?, `admin`=?, `name`=?, `image`=?, `created_at`=? where `id`=? ['test@qq.com', '1234567890', 1, 'Test', 'about:blank', 1637637058.59806, '0016376370585981a21e061a83146c49733e8c841747974000']
返回结果显示影响的条数是1条,也打印了update语句,在数据库查询也修改成功了

同理我们在添加删除的方法
def remove(self):
args = [self.getValue(self.__primary_key__)]
print(self.__delete__, args)
rows = execute(self.__delete__, args)
if rows != 1:
logging.warning('failed to delete by primary key: affected rows: %s' % rows)
通过关键字id来删除
rs = User.find('0016376370585981a21e061a83146c49733e8c841747974000')
rs.remove()
②添加select方法
select方法对比修改数据库的insert,update,delete方法参数更加复杂
在上面的例子中我们已经演示了一个find的方法,即通过关键字id来查询,下面我们添加更多的select方法
查询方法都是查询数据库中已经有的数据,直接使用类方法即可
所以查询方法需要使用装饰器@classmethod装饰为类方法,现在暂时不需要理解怎么装饰的,只需要理解使用这个方法装饰的函数为类方法,直接使用类即可调用
默认传递的第一个参数cls为类本身,相当于实例方法默认的第一个参数self为实例本身一样
首先我定义一个通用根据条件查询所有满足条件的数据的函数findAll,我们需要使用原始的sql然后通过传递参数的方法传递一些查询条件,在定义函数之前我们先来了解MySQL加参数查询的几种方式。
①全表查询
select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`
②根据关键字查询
例如我们通过关键字id来查询
select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where id="00163764569648657ab15f6c89a483a8f2aa02ece349bba000"
③排序查询
通过order by定义排序字段
select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where id="00163764569648657ab15f6c89a483a8f2aa02ece349bba000" order by id
④查询部分
使用limit其中limit有两种使用方法
一,定义一个整数最多输出多少数据,例如limit 2输出前两天数据
二,定义两个整数输出一个区间的多少,例如limit 1,3输出区间的数据,类似于切片输出
select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` limit 1 select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` limit 1,2
其中上述查询的几个关键字'where','order by','limit'是互不冲突,也就是说可以单独使用也可以组合使用
所以我们定义的函数需要传递的几个参数为
where # 用于传递查询的关键字即对应的值,例如where='id="00163764569648657ab15f6c89a483a8f2aa02ece349bba000"'默认为None
args # 用于存储sql语句后对应的参数,默认为None
**kw # 字典,用于存储关键字键值对,例如{'orderBy':'id'} {'limit':2} {'limit':(1,2)}
下面编写findAll()函数,添加至Model类
@classmethod
def findAll(cls,where=None,agrs=None,**kw):
# 原始select语句 'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`'
# 原始是一个str,放在一个list中,即把这个str作为list的一个元素
sql = [cls.__select__]
print('SQL原始放入list中后是:%s' %(sql))
if where:
sql.append('where')
sql.append(where)
print('SQL加入where条件后是:%s' %(sql))
if agrs is None:
args = []
orderBy = kw.get('orderBy',None)
if orderBy:
sql.append('order by')
sql.append(orderBy)
print('SQL加入order by条件后是:%s' %(sql))
limit = kw.get('limit',None)
if limit:
sql.append('limit')
if isinstance(limit,int):
sql.append('?')
args.append(limit)
elif isinstance(limit,tuple) and len(limit) == 2:
sql.append('?,?')
args.extend(limit)
else:
raise ValueError('Invalid limit value: %s' % str(limit))
print('SQL加入limit条件后是:%s' %(sql))
rs = select(' '.join(sql),args)
# 查询结果是一个list其中的元素是字典
# 使用列表生成器把字典代入类中返回实例
return [cls(**r) for r in rs]
本次如果有条件where这把条件以字符串的方式传递例如
where="id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'"
如果有order by和limit则放入字典传递例如直接以键值对的方式传递
也可以先定义好字典kw再以**kw的方式传递
orderBy='id',limit=1
为了便于观察每一步sql的执行过程,我们在代码里面针对每一步对sql的操作执行了打印操作
下面我们来运行查询
本次查询数据库只有一条测试数据
①不加任何条件,全表查询
rs = User.findAll() print(rs)
输出如下
SQL原始放入list中后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`']
SQL加入where条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`']
SQL加入order by条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`']
SQL加入limit条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`']
SQL最后的查询语句是select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`,[]
INFO:root:SQL:select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`
INFO:root:rows returned: 1
[{'id': '00163764569648657ab15f6c89a483a8f2aa02ece349bba000', 'email': 'test@qq.com', 'passwd': '1234567890', 'admin': 1, 'name': 'Test', 'image': 'about:blank', 'created_at': 1637645696.48586}]
默认查询全表,从头到尾sql语句没有做过任何修改
②添加一个where条件
rs = User.findAll(where="id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'") print(rs)
输出如下
SQL原始放入list中后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`']
SQL加入where条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', 'where', "id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'"]
SQL加入order by条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', 'where', "id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'"]
SQL加入limit条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', 'where', "id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'"]
SQL最后的查询语句是select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000',[]
INFO:root:SQL:select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'
INFO:root:rows returned: 1
[{'id': '00163764569648657ab15f6c89a483a8f2aa02ece349bba000', 'email': 'test@qq.com', 'passwd': '1234567890', 'admin': 1, 'name': 'Test', 'image': 'about:blank', 'created_at': 1637645696.48586}]
我们可以看到只有where条件修改了,因为没有传递order和limit所以没有增加对应关键字
③添加order和limit条件
rs = User.findAll(where="id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'",orderBy='id',limit=1) print(rs)
输出如下
SQL原始放入list中后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`']
SQL加入where条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', 'where', "id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'"]
SQL加入order by条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', 'where', "id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'", 'order by', 'id']
SQL加入limit条件后是:['select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`', 'where', "id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'", 'order by', 'id', 'limit', '?']
SQL最后的查询语句是select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000' order by id limit ?,[1]
INFO:root:SQL:select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users` where id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000' order by id limit ?
INFO:root:rows returned: 1
[{'id': '00163764569648657ab15f6c89a483a8f2aa02ece349bba000', 'email': 'test@qq.com', 'passwd': '1234567890', 'admin': 1, 'name': 'Test', 'image': 'about:blank', 'created_at': 1637645696.48586}]
因为通过字典传递了orderBy参数对应的是需要排序的字段'id'
传递了limit参数对应的是一个整数例如1,或者是一个元组例如(1,3)
这里就不演示limit传递元组的例子了,结果是一样的
下面我们在定义一个查询函数,根据传递的字段名例如查询字段id返回该字典第1条数据对应的字段值
@classmethod
# selectField传递一个字段名称例如id
# 通过该字段去查询然后把查询到的第一个结果对应的值返回
def findNumber(cls,selectField,where=None,args=None):
sql = ['select %s _num_ from `%s`' % (selectField, cls.__table__)]
if where:
sql.append('where')
sql.append(where)
print('SQL通过findNumber查询语句是:%s,%s' %(' '.join(sql),args))
rs = select(' '.join(sql),args,1)
if len(rs) == 0:
return None
print('findNumber查询结果是%s' %(rs))
# 取该结果对应的值返回
return rs[0]['_num_']
查询测试例如我们需要查询字段id对应的第一条数据对应的值
rs = User.findNumber(selectField='id') print(rs)
输出如下
SQL通过findNumber查询语句是:select id _num_ from `users`,None
INFO:root:SQL:select id _num_ from `users`
INFO:root:rows returned: 1
findNumber查询结果是[{'_num_': '00163764569648657ab15f6c89a483a8f2aa02ece349bba000'}]
00163764569648657ab15f6c89a483a8f2aa02ece349bba000
还有一个查询函数,通过传递主键id的值来查询,在上一个例子中已经有介绍了
@classmethod
def find(cls, pk):
## find object by primary key
sql = '%s where `%s`=?' % (cls.__select__, cls.__primary_key__)
print(sql)
rs = select(sql, [pk], 1)
if len(rs) == 0:
return None
# print(type(cls(**rs[0])),type(rs[0]))
# 注意rs[0]是一个字典,使用cls(**rs[0])相当于把这个字典传递给类创建一个实例
# 虽然打印rs[0]和cls(**rs[0])看起来是一样的但是类型不一样,不能返回字典因为返回字典就无法调用类的方法
return cls(**rs[0])
以下是往类Model中添加selete后的完整代码
############################################
# 拆分解析往类Model添加方法select
import time,uuid
# 根据传递的整数生成一个字符串?,?,?...用于占位符
def create_args_string(num):
L = []
for n in range(num):
L.append('?')
return ', '.join(L)
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
# 排除Model类本身,即针对Model不做任何修改原样返回:
if name=='Model':
return type.__new__(cls, name, bases, attrs)
# 获取table名称:
# 从字典attrs中获取属性__table__,如果在类中没有定义这个属性则返回None
# 如果在属性中没有定义但是我们可以从参数name中获取到就是类名
# 例如我们对类User进行重新创建,在类User中已经定义了属性 __table__ = 'users'
# 所以我们优先得到的表名就是'users',假如没有定义则就是类名'User'
tableName = attrs.get('__table__', None) or name
# 输出日志
logging.info('found model: %s (table: %s)' % (name, tableName))
# 为了便于观察我们打印对类修改前的attrs字典
print("修改前attrs:%s" % attrs)
# 获取所有的Field和主键名:
# 定义一个空字典用于存储需要定义的类中除了默认属性以为定义的属性
# 例如本次我们针对类User则使用mappings字典存储'id','email','passwd','admin','name','image','create_at'的属性
# 它们对应的属性值是一个实例化以后的实例,例如id对应的属性值是通过类StringField实例化后的实例
mappings = dict()
# fields表用于存储普通的字段名称,即除了主键以外的其他字段
# 例如针对User类则在fields存储字段'email','passwd','admin','name','image','create_at'的名称
fields = []
# primaryKey用于存储主键字段名
# 例如针对类User的主键名为'id'
primaryKey = None
# 以key,value的方式遍历attrs字典
for k, v in attrs.items():
# 如果对应的value是Field的子集则把对应的key value追加至字典mappings
if isinstance(v, Field):
logging.info(' found mapping: %s ==> %s' % (k, v))
mappings[k] = v
# 然后通过实例的属性primary_key去找主键,如果找到了主键则赋值给primaryKey
# 如果不是主键的字段则追加至fields这个list
# 一个表只能有一个主键,如果有多个主键则抛出RuntimeError错误,错误提示为重复的主键
if v.primary_key:
# 找到主键:
if primaryKey:
raise RuntimeError('Duplicate primary key for field: %s' % k)
primaryKey = k
else:
fields.append(k)
# 如果表内没有定义主键则抛出错误主键没有发现
if not primaryKey:
raise RuntimeError('Primary key not found.')
# 已经把对应的key value存储至字典以后,从原attrs中属性中删除对应的key value
# 如果不删除则类属性和实例属性会冲突
# 例如类User需要从原attrs中删除key值为 'id','email','passwd','admin','name','image','create_at'的元素
for k in mappings.keys():
attrs.pop(k)
# 把存储除主键之外的字典list元素加一个``
# 例如原fields为 ['email', 'passwd', 'admin', 'name', 'image', 'created_at']
# map经过匿名函数把list中的所有元素处理加符号``,处理以后得到一个惰性序列然后通过list输出
# escaped_fields为 ['`email`', '`passwd`', '`admin`', '`name`', '`image`', '`created_at`']
escaped_fields = list(map(lambda f: '`%s`' % f, fields))
print(escaped_fields)
attrs['__mappings__'] = mappings # 保存属性和列的映射关系
# 保存表名
attrs['__table__'] = tableName
# 主键属性名
attrs['__primary_key__'] = primaryKey
# 除主键外的属性名
attrs['__fields__'] = fields
# 构造默认的SELECT, INSERT, UPDATE和DELETE语句:
attrs['__select__'] = 'select `%s`, %s from `%s`' % (primaryKey, ', '.join(escaped_fields), tableName)
attrs['__insert__'] = 'insert into `%s` (%s, `%s`) values (%s)' % (tableName, ', '.join(escaped_fields), primaryKey, create_args_string(len(escaped_fields) + 1))
attrs['__update__'] = 'update `%s` set %s where `%s`=?' % (tableName, ', '.join(map(lambda f: '`%s`=?' % (mappings.get(f).name or f), fields)), primaryKey)
attrs['__delete__'] = 'delete from `%s` where `%s`=?' % (tableName, primaryKey)
print("修改后attrs:%s" % attrs)
return type.__new__(cls, name, bases, attrs)
class Model(dict, metaclass=ModelMetaclass):
@classmethod
def findAll(cls,where=None,agrs=None,**kw):
# 原始select语句 'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`'
# 原始是一个str,放在一个list中,即把这个str作为list的一个元素
sql = [cls.__select__]
print('SQL原始放入list中后是:%s' %(sql))
if where:
sql.append('where')
sql.append(where)
print('SQL加入where条件后是:%s' %(sql))
if agrs is None:
args = []
orderBy = kw.get('orderBy',None)
if orderBy:
sql.append('order by')
sql.append(orderBy)
print('SQL加入order by条件后是:%s' %(sql))
limit = kw.get('limit',None)
if limit:
sql.append('limit')
if isinstance(limit,int):
sql.append('?')
args.append(limit)
elif isinstance(limit,tuple) and len(limit) == 2:
sql.append('?,?')
args.extend(limit)
else:
raise ValueError('Invalid limit value: %s' % str(limit))
print('SQL加入limit条件后是:%s' %(sql))
print('SQL最后的查询语句是%s,%s' %(' '.join(sql),args))
rs = select(' '.join(sql),args)
# 查询结果是一个list其中的元素是字典
# 使用列表生成器把字典代入类中返回实例
return [cls(**r) for r in rs]
@classmethod
# selectField传递一个字段名称例如id
# 通过该字段去查询然后把查询到的第一个结果对应的值返回
def findNumber(cls,selectField,where=None,args=None):
sql = ['select %s _num_ from `%s`' % (selectField, cls.__table__)]
if where:
sql.append('where')
sql.append(where)
print('SQL通过findNumber查询语句是:%s,%s' %(' '.join(sql),args))
rs = select(' '.join(sql),args,1)
if len(rs) == 0:
return None
print('findNumber查询结果是%s' %(rs))
# 取该结果对应的值返回
return rs[0]['_num_']
@classmethod
def find(cls, pk):
## find object by primary key
sql = '%s where `%s`=?' % (cls.__select__, cls.__primary_key__)
print(sql)
rs = select(sql, [pk], 1)
if len(rs) == 0:
return None
# print(type(cls(**rs[0])),type(rs[0]))
# 注意rs[0]是一个字典,使用cls(**rs[0])相当于把这个字典传递给类创建一个实例
# 虽然打印rs[0]和cls(**rs[0])看起来是一样的但是类型不一样,不能返回字典因为返回字典就无法调用类的方法
return cls(**rs[0])
# 使字典可以以属性方式取值
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
# 定义方法通过key取值
def getValue(self, key):
return getattr(self, key, None)
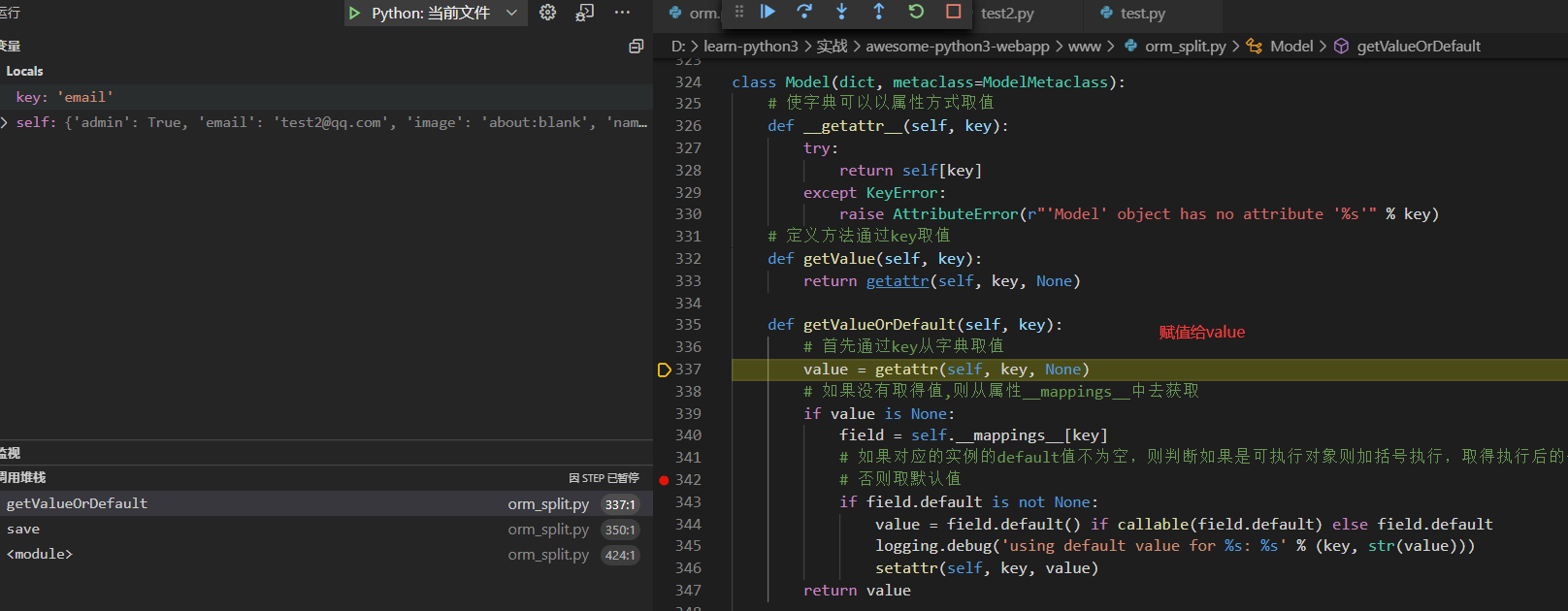
def getValueOrDefault(self, key):
# 首先通过key从字典取值
value = getattr(self, key, None)
# 如果没有取得值,则从属性__mappings__中去获取
if value is None:
field = self.__mappings__[key]
# 如果对应的实例的default值不为空,则判断如果是可执行对象则加括号执行,取得执行后的值
# 否则取默认值
if field.default is not None:
value = field.default() if callable(field.default) else field.default
logging.debug('using default value for %s: %s' % (key, str(value)))
setattr(self, key, value)
return value
def save(self):
args = list(map(self.getValueOrDefault, self.__fields__))
args.append(self.getValueOrDefault(self.__primary_key__))
sql = self.__insert__
print(sql,args)
rows = execute(sql,args)
print(rows)
if rows != 1:
logging.warning('failed to insert record: affected rows: %s' % rows)
def update(self):
args = list(map(self.getValue, self.__fields__))
args.append(self.getValue(self.__primary_key__))
rows = execute(self.__update__, args)
print(self.__update__,args)
if rows != 1:
logging.warning('failed to update by primary key: affected rows: %s' % rows)
def remove(self):
args = [self.getValue(self.__primary_key__)]
print(self.__delete__, args)
rows = execute(self.__delete__, args)
if rows != 1:
logging.warning('failed to delete by primary key: affected rows: %s' % rows)
# 定义Field类,作为数据库字段类型的父类
class Field(object):
# 初始化方法定义了4个属性,分别为name字段名(id),column_type字段属性(bigint),primary_key是否为主键(True or False),default默认值
def __init__(self, name, column_type, primary_key, default):
self.name = name
self.column_type = column_type
self.primary_key = primary_key
self.default = default
# 返回实例对象的时候好看一点默认返回为 <__main__.StringField object at 0x0000025CC313EF08>
# 定义了__str__返回为 <StringField:email>
# 可以省略使用默认也可以
def __str__(self):
return '<%s, %s:%s>' % (self.__class__.__name__, self.column_type, self.default)
# 定义字符串字段类,继承父类Field的初始化方法,name字段名属性默认为None,到时使用类User创建出来的实例的key就是字段名
# 例如创建了一个User实例,该实例是一个字典,它包含的key有id email name等就是数据库表的字段名
class StringField(Field):
def __init__(self, name=None, primary_key=False, default=None, ddl='varchar(100)'):
super().__init__(name, ddl, primary_key, default)
# 定义布尔类型字段类,通过name属性为None
# 字段类型默认为boolean,默认为非主键,默认值为False
class BooleanField(Field):
def __init__(self, name=None, default=False):
super().__init__(name, 'boolean', False, default)
# 定义整数类型字段类
class IntegerField(Field):
def __init__(self, name=None, primary_key=False, default=0):
super().__init__(name, 'bigint', primary_key, default)
# 定义浮点类型字段类,字段类型real相当于float
class FloatField(Field):
def __init__(self, name=None, primary_key=False, default=0.0):
super().__init__(name, 'real', primary_key, default)
# 定义文本类型字段类
class TextField(Field):
def __init__(self, name=None, default=None):
super().__init__(name, 'text', False, default)
# 定义函数,用于随机生成一个字符串作为主键id的值
# 加括号运行函数返回一个字符串字符串去前15位为时间戳乘以1000,然后不足15位使用0补齐
# 后面为使用uuid.uuid4().hex随机生成的一段字符串
# 最后补000
def next_id():
return '%015d%s000' % (int(time.time() * 1000), uuid.uuid4().hex)
# 定义用户User类
class User(Model):
# 自定义表名,如果不自定义可以使用类名作为表名
# 在使用metaclass重新定义类时,通过方法__new__内部的参数name可以获取到类名
__table__ = 'users'
# 定义字段名,id作为主键
id = StringField(primary_key=True, default=next_id, ddl='varchar(50)')
email = StringField(ddl='varchar(50)')
passwd = StringField(ddl='varchar(50)')
admin = BooleanField()
name = StringField(ddl='varchar(50)')
image = StringField(ddl='varchar(500)')
created_at = FloatField(default=time.time)
# 创建数据库连接池和执行insert update select函数 start
import pymysql
def create_pool(**kw):
host=kw.get('host', 'localhost')
port=kw.get('port', 3306)
user=kw['user']
password=kw['password']
db=kw['db']
# 创建全部变量,用于存储创建的连接池
global conn
conn = pymysql.connect(host=host, user=user, password=password, database=db,port=port)
# 字典存储数据库信息
kw = {'host':'localhost','user':'www-data','password':'www-data','db':'awesome'}
# 把字典传入创建连接池函数,执行即创建了全局连接池conn,可以在查询,执行等函数调用执行
create_pool(**kw)
def select(sql,args,size=None):
log(sql,args)
cursor = conn.cursor(pymysql.cursors.DictCursor)
cursor.execute(sql.replace('?','%s'),args or ())
if size:
rs = cursor.fetchmany(size)
else:
rs = cursor.fetchall()
cursor.close
logging.info('rows returned: %s' % len(rs))
return rs
def execute(sql,args):
cursor = conn.cursor(pymysql.cursors.DictCursor)
try:
cursor.execute(sql.replace('?','%s'),args)
rs = cursor.rowcount
cursor.close()
conn.commit()
except:
raise
return rs
# 创建数据库连接池和执行insert update select函数 end
u = User(name='Test', email='test4@qq.com', passwd='1234567890', image='about:blank',admin=True)
# u.save()
# u.save()
# print(u.getValue('id'))
# print(select("select * from users",[]))
# rs = User.findAll()
# print(rs)
# rs = User.findAll(where="id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'")
# print(rs)
# rs = User.findAll(where="id='00163764569648657ab15f6c89a483a8f2aa02ece349bba000'",orderBy='id',limit=1)
# print(rs)
rs = User.findNumber(selectField='id')
print(rs)
# 拆分解析往类Model添加方法select end
#$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$$
以上即为拆分解析orm的过程,为了便于理解我们拆分解析时使用了同步方法,我们博客使用的是异步方式,原理其实是一样的,只不过异步方式要在事件循环中获得结果,下面贴出使用异步连接数据库MySQL的所有orm.py代码
import asyncio,logging,aiomysql
def log(sql,args=()):
logging.info('SQL:%s' % sql)
# 定义创建连接池的协程函数
async def create_pool(loop,**kw):
logging.info('creart database connection pool...')
global __pool
__pool = await aiomysql.create_pool(
host=kw.get('host','localhost'),
port=kw.get('port',3306),
user=kw['user'],
password=kw['password'],
db=kw['db'],
charset=kw.get('charset','utf8'),
autocommit=kw.get('autocommit',True),
maxsize=kw.get('maxsize',10),
minsize=kw.get('minsize',1),
loop=loop
)
# 演示创建连接池
# 创建事件循环对象
loop = asyncio.get_event_loop()
# 定义连接池的参数
kw = {'user':'www-data','password':'www-data','db':'awesome'}
# 创建数据库连接池,执行完毕以后就创建了全局的连接池对象__pool
# 在执行搜索的select协程函数和执行修改的execute函数需要调用连接池对象创建数据库浮标对象
loop.run_until_complete(create_pool(loop=loop,**kw))
# 定义select协程函数
async def select(sql,args,size=None):
log(sql,args)
global __pool
with (await __pool) as conn:
# 使用数据库连接池对象__pool创建数据库浮标对象
cur = await conn.cursor(aiomysql.DictCursor)
# 查询语句通配符为'?'需要转换成MySQL语句通配符'%s'
await cur.execute(sql.replace('?','%s'),args or ())
# 如果传递了参数size则获取查询结果的前几个,size为正整数
# 否则返回所有查询结果
if size:
rs = await cur.fetchmany(size)
else:
rs = await cur.fetchall()
# 关闭数据库浮标
await cur.close()
logging.info('rows returned: %s' % len(rs))
return rs
# Insert,Update,Delete
async def execute(sql, args):
log(sql)
with (await __pool) as conn:
try:
cur = await conn.cursor()
await cur.execute(sql.replace('?', '%s'), args)
affected = cur.rowcount
await cur.close()
except BaseException as e:
raise
return affected
# 定义创建匹配符的函数,传递一个整数,返回为由num个'?'组成的字符串
def create_args_string(num):
L = []
for n in range(num):
L.append('?')
return ', '.join(L)
class ModelMetaclass(type):
def __new__(cls, name, bases, attrs):
# 排除Model类本身:
if name=='Model':
return type.__new__(cls, name, bases, attrs)
# 获取table名称:
# 从字典attrs中获取属性__table__,如果在类中没有定义这个属性则返回None
# 如果在属性中没有定义但是我们可以从参数name中获取到就是类名
# 例如我们对类User进行重新创建,在类User中已经定义了属性 __table__ = 'users'
# 所以我们优先得到的表名就是'users',假如没有定义则就是类名'User'
# 为了便于观察我们打印对类修改前的attrs字典
print("修改前attrs:%s" % attrs)
tableName = attrs.get('__table__', None) or name
# 输出日志
logging.info('found model: %s (table: %s)' % (name, tableName))
# 获取所有的Field和主键名:
# 定义一个空字典用于存储需要定义的类中除了默认属性以为定义的属性
# 例如本次我们针对类User则使用mappings字典存储'id','email','passwd','admin','name','image','create_at'的属性
# 它们对应的属性值是一个实例化以后的实例,例如id对应的属性值是通过类StringField实例化后的实例
mappings = dict()
# fields表用于存储普通的字段名称,即除了主键以外的其他字段
# 例如针对User类则在fields存储字段'email','passwd','admin','name','image','create_at'的名称
fields = []
primaryKey = None
# 以key,value的方式遍历attrs字典
for k, v in attrs.items():
if isinstance(v, Field):
logging.info(' found mapping: %s ==> %s' % (k, v))
mappings[k] = v
# 然后通过实例的属性primary_key去找主键,如果找到了主键则赋值给primaryKey
# 如果不是主键的字段则追加至fields这个list
# 一个表只能有一个主键,如果有多个主键则抛出RuntimeError错误,错误提示为重复的主键
if v.primary_key:
# 找到主键:
if primaryKey:
raise RuntimeError('Duplicate primary key for field: %s' % k)
primaryKey = k
else:
fields.append(k)
# 如果表内没有定义主键则抛出错误主键没有发现
if not primaryKey:
raise RuntimeError('Primary key not found.')
# 已经把对应的key value存储至字典以后,从原attrs中属性中删除对应的key value
# 如果不删除则类属性和实例属性会冲突
# 例如类User需要从原attrs中删除key值为 'id','email','passwd','admin','name','image','create_at'的元素
for k in mappings.keys():
attrs.pop(k)
# 把存储除主键之外的字典list元素加一个``
# 例如原fields为 ['email', 'passwd', 'admin', 'name', 'image', 'created_at']
# map经过匿名函数把list中的所有元素处理加符号``,处理以后得到一个惰性序列然后通过list输出
# escaped_fields为 ['`email`', '`passwd`', '`admin`', '`name`', '`image`', '`created_at`']
escaped_fields = list(map(lambda f: '`%s`' % f, fields))
# 保存属性和列的映射关系
attrs['__mappings__'] = mappings
attrs['__table__'] = tableName
# 主键属性名
attrs['__primary_key__'] = primaryKey
# 除主键外的属性名
attrs['__fields__'] = fields
# 构造默认的SELECT, INSERT, UPDATE和DELETE语句:
attrs['__select__'] = 'select `%s`, %s from `%s`' % (primaryKey, ', '.join(escaped_fields), tableName)
attrs['__insert__'] = 'insert into `%s` (%s, `%s`) values (%s)' % (tableName, ', '.join(escaped_fields), primaryKey, create_args_string(len(escaped_fields) + 1))
attrs['__update__'] = 'update `%s` set %s where `%s`=?' % (tableName, ', '.join(map(lambda f: '`%s`=?' % (mappings.get(f).name or f), fields)), primaryKey)
attrs['__delete__'] = 'delete from `%s` where `%s`=?' % (tableName, primaryKey)
print("修改后attrs:%s" % attrs)
return type.__new__(cls, name, bases, attrs)
class Model(dict, metaclass=ModelMetaclass):
@classmethod
# 原始select语句 'select `id`, `email`, `passwd`, `admin`, `name`, `image`, `created_at` from `users`'
# 原始是一个str,放在一个list中,即把这个str作为list的一个元素
async def findAll(cls, where=None, args=None, **kw):
## find objects by where clause
sql = [cls.__select__]
if where:
sql.append('where')
sql.append(where)
if args is None:
args = []
orderBy = kw.get('orderBy', None)
if orderBy:
sql.append('order by')
sql.append(orderBy)
limit = kw.get('limit', None)
if limit is not None:
sql.append('limit')
if isinstance(limit, int):
sql.append('?')
args.append(limit)
elif isinstance(limit, tuple) and len(limit) == 2:
sql.append('?, ?')
args.extend(limit)
else:
raise ValueError('Invalid limit value: %s' % str(limit))
rs = await select(' '.join(sql), args)
# 查询结果是一个list其中的元素是字典
# 使用列表生成器把字典代入类中返回一个实例为原始的list
return [cls(**r) for r in rs]
# selectField传递一个字段名称例如id
# 通过该字段去查询然后把查询到的第一个结果对应的值返回
@classmethod
async def findNumber(cls, selectField, where=None, args=None):
## find number by select and where
sql = ['select %s _num_ from `%s`' % (selectField, cls.__table__)]
if where:
sql.append('where')
sql.append(where)
rs = await select(' '.join(sql), args, 1)
if len(rs) == 0:
return None
# 取该结果对应的值返回
return rs[0]['_num_']
@classmethod
async def find(cls, pk):
## find object by primary key
rs = await select('%s where `%s`=?' % (cls.__select__, cls.__primary_key__), [pk], 1)
if len(rs) == 0:
return None
# print(type(cls(**rs[0])),type(rs[0]))
# 注意rs[0]是一个字典,使用cls(**rs[0])相当于把这个字典传递给类创建一个实例
# 虽然打印rs[0]和cls(**rs[0])看起来是一样的但是类型不一样,不能返回字典因为返回字典就无法调用类的方法
return cls(**rs[0])
def __init__(self, **kw):
super(Model, self).__init__(**kw)
# 使字典可以以属性方式取值
def __getattr__(self, key):
try:
return self[key]
except KeyError:
raise AttributeError(r"'Model' object has no attribute '%s'" % key)
def __setattr__(self, key, value):
self[key] = value
# 定义方法通过key取值
def getValue(self, key):
return getattr(self, key, None)
def getValueOrDefault(self, key):
# 首先通过key从字典取值
value = getattr(self, key, None)
# 如果没有取得值,则从属性__mappings__中去获取
if value is None:
field = self.__mappings__[key]
# 如果对应的实例的default值不为空,则判断如果是可执行对象则加括号执行,取得执行后的值
# 否则取默认值
if field.default is not None:
value = field.default() if callable(field.default) else field.default
logging.debug('using default value for %s: %s' % (key, str(value)))
setattr(self, key, value)
return value
async def save(self):
args = list(map(self.getValueOrDefault, self.__fields__))
args.append(self.getValueOrDefault(self.__primary_key__))
rows = await execute(self.__insert__, args)
if rows != 1:
logging.warning('failed to insert record: affected rows: %s' % rows)
async def update(self):
args = list(map(self.getValue, self.__fields__))
args.append(self.getValue(self.__primary_key__))
rows = await execute(self.__update__, args)
if rows != 1:
logging.warning('failed to update by primary key: affected rows: %s' % rows)
async def remove(self):
args = [self.getValue(self.__primary_key__)]
rows = await execute(self.__delete__, args)
if rows != 1:
logging.warning('failed to remove by primary key: affected rows: %s' % rows)
# 定义Field类,作为数据库字段类型的父类
class Field(object):
# 初始化方法定义了4个属性,分别为name字段名(id),column_type字段属性(bigint),primary_key是否为主键(True or False),default默认值
def __init__(self, name, column_type, primary_key, default):
self.name = name
self.column_type = column_type
self.primary_key = primary_key
self.default = default
# 返回实例对象的时候好看一点默认返回为 <__main__.StringField object at 0x0000025CC313EF08>
# 定义了__str__返回为 <StringField:email>
# 可以省略使用默认也可以
def __str__(self):
return '<%s, %s:%s>' % (self.__class__.__name__, self.column_type, self.name)
# 定义字符串字段类,继承父类Field的初始化方法,name字段名属性默认为None,到时使用类User创建出来的实例的key就是字段名
# 例如创建了一个User实例,该实例是一个字典,它包含的key有id email name等就是数据库表的字段名
class StringField(Field):
def __init__(self, name=None, primary_key=False, default=None, ddl='varchar(100)'):
super().__init__(name, ddl, primary_key, default)
# 定义布尔类型字段类,通过name属性为None
# 字段类型默认为boolean,默认为非主键,默认值为False
class BooleanField(Field):
def __init__(self, name=None, default=False):
super().__init__(name, 'boolean', False, default)
# 定义整数类型字段类
class IntegerField(Field):
def __init__(self, name=None, primary_key=False, default=0):
super().__init__(name, 'bigint', primary_key, default)
# 定义浮点类型字段类,字段类型real相当于float
class FloatField(Field):
def __init__(self, name=None, primary_key=False, default=0.0):
super().__init__(name, 'real', primary_key, default)
# 定义文本类型字段类
class TextField(Field):
def __init__(self, name=None, default=None):
super().__init__(name, 'text', False, default)