-
数据分析实战——12 | 数据集成
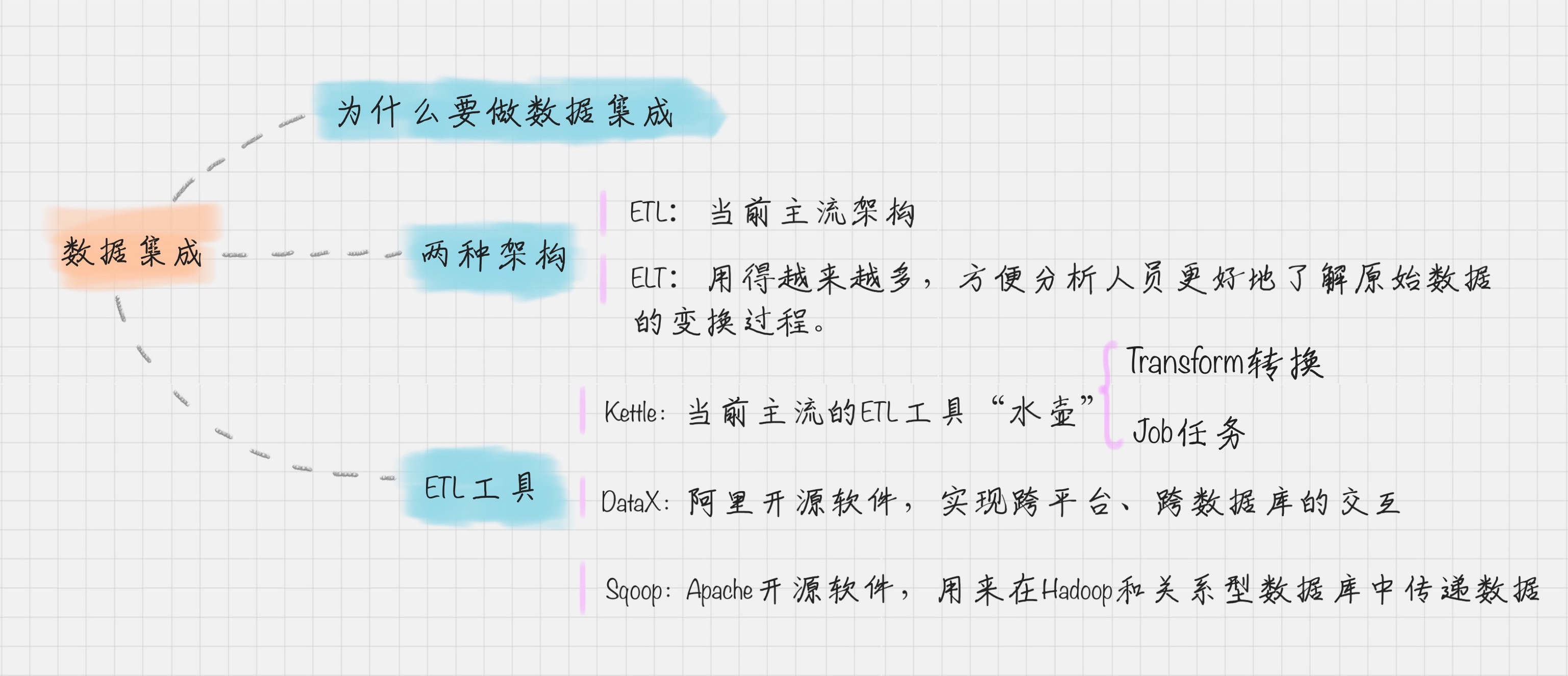
- 数据集成就是将多个数据源合并存放在一个数据存储中(如数据仓库),从而方便后续的数据挖掘工作
- 大数据项目中 80% 的工作都和数据集成有关,这里的数据集成有更广泛的意义,包括了数据清洗、数据抽取、数据集成和数据变换等操作
- 这是因为数据挖掘前,我们需要的数据往往分布在不同的数据源中,需要考虑字段表达是否一样,以及属性是否冗余
- 数据集成的两种架构:ELT 和 ETL
- 数据工程师的工作包括了数据的 ETL 和数据挖掘算法的实现
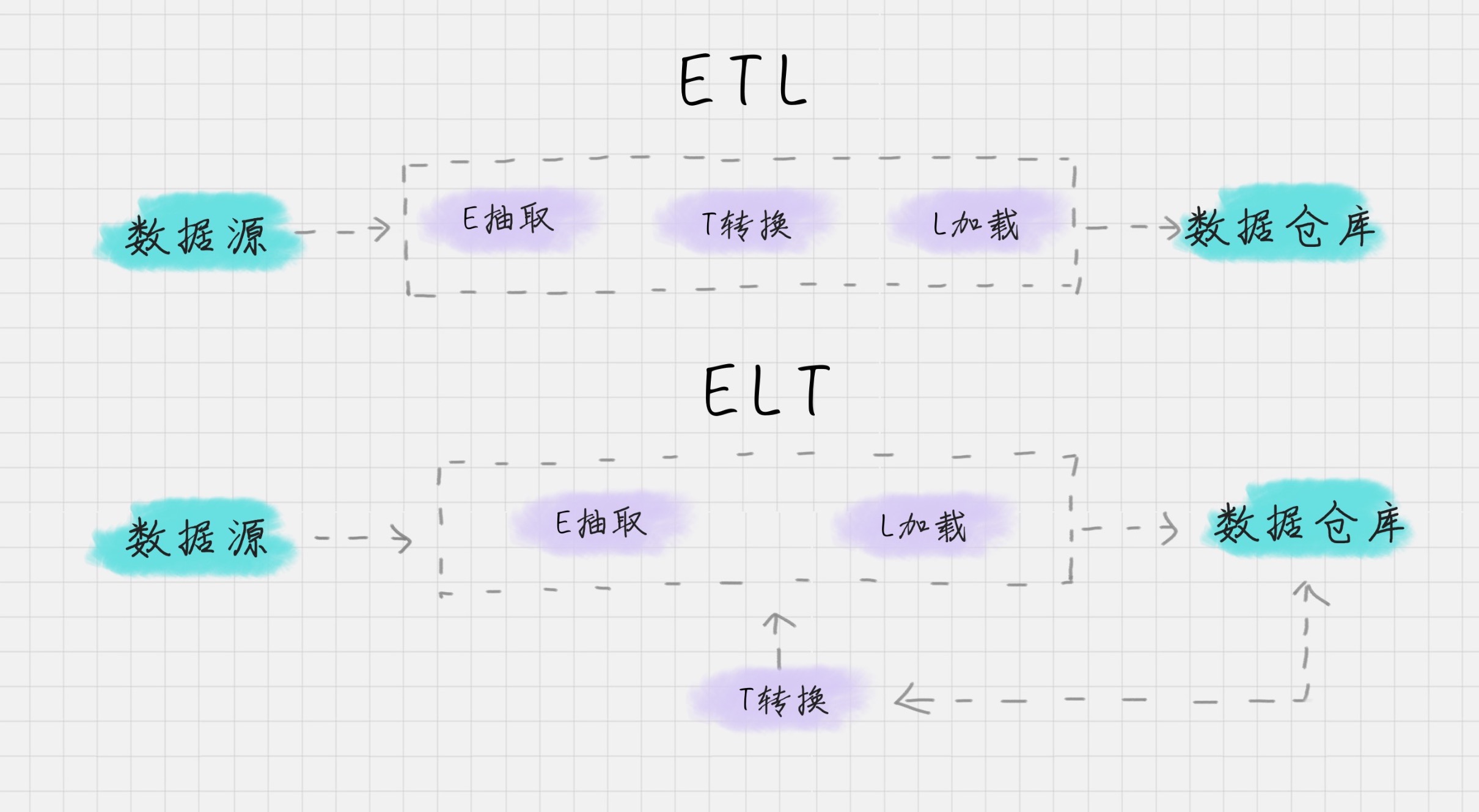
- 根据转换发生的顺序和位置,数据集成可以分为 ETL 和 ELT 两种架构
- ETL 的过程为提取 (Extract)——转换 (Transform)——加载 (Load),在数据源抽取后首先进行转换,然后将转换的结果写入目的地。
- ELT 的过程则是提取 (Extract)——加载 (Load)——变换 (Transform),在抽取后将结果先写入目的地,然后利用数据库的聚合分析能力或者外部计算框架,如 Spark 来完成转换的步骤。
-
- 目前数据集成的主流架构是 ETL,但未来使用 ELT 作为数据集成架构的将越来越多
- ELT 和 ETL 相比,最大的区别是“重抽取和加载,轻转换”,从而可以用更轻量的方案搭建起一个数据集成平台;节省时间
- 在 ELT 架构中,数据变换这个过程根据后续使用的情况,需要在 SQL 中进行,而不是在加载阶段进行
- ETL 工具有哪些?
- Kettle与Sqoop的比较
- kettle是传统ETL工具,Sqoop是针对大数据仓库的ETL工具
- Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
- Sqoop主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递
- kettle有图形化的操作界面,只需要描述你想做什么,而不是你想怎么做。
- sqoop没有图形化界面,具体的数据流向需要手工配置。
- kettle底层使用多线程以提高效率
- Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
- kettle可以利用transformation在数据传输过程中对数据的一些转换处理
- Sqoop只是一个用来将Hadoop和关系型数据库中的数据相互转移的工具
- kettle数据的具体流向可以指定,可以是各种数据的存储工具
- sqoop只是完成hdfs到关系型数据库 或者 关系型数据库到hdfs的数据传输,在传输的过程中保证传输数据的类型
- Kettle 工具的使用
- 该项目的目标是将各种数据放到一个壶里,然后以一种指定的格式流出
- Kettle 采用可视化的方式进行操作,来对数据库间的数据进行迁移。它包括了两种脚本:Transformation 转换和 Job 作业
- Transformation(转换):相当于一个容器,对数据操作进行了定义。你可以把转换理解成为是比作业粒度更小的容器。在通常的工作中,我们会把任务分解成为不同的作业,然后再把作业分解成多个转换。
- Job(作业):相比于转换是个更大的容器,它负责将转换组织起来完成某项作业。
- 如何创建 Transformation(转换)
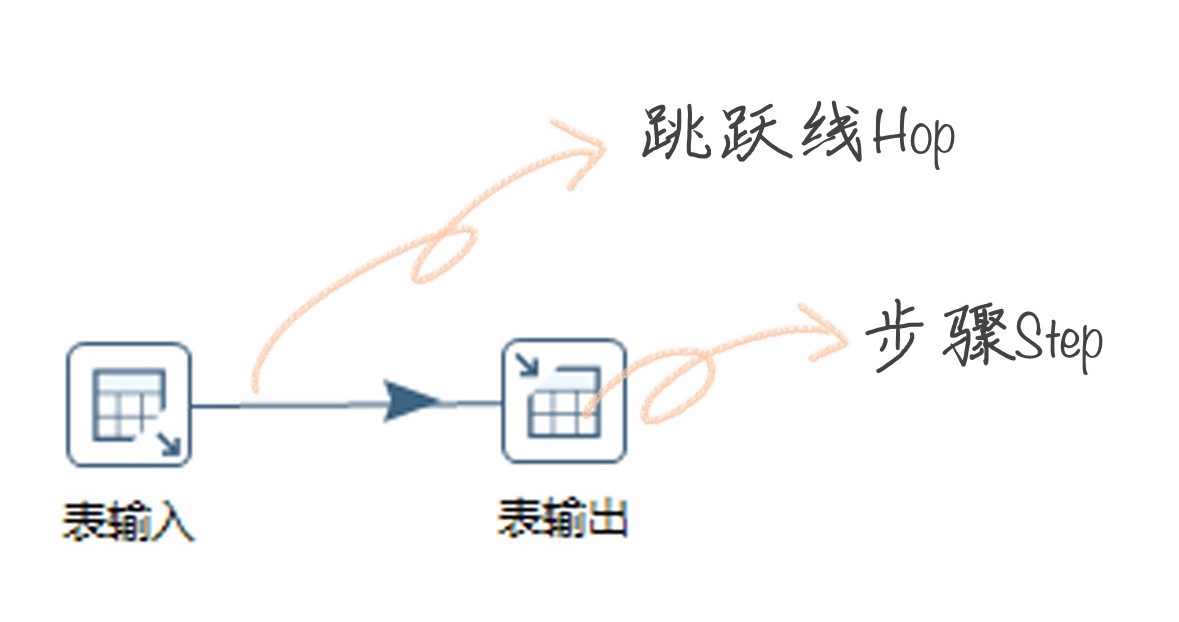
- Transformation 可以分成三个步骤,它包括了输入、中间转换以及输出。
- 在 Transformation 中包括两个主要概念:Step 和 Hop。Step 的意思就是步骤,Hop 就是跳跃线的意思。
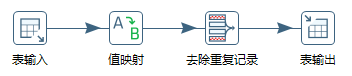
- Step(步骤):Step 是转换的最小单元,每一个 Step 完成一个特定的功能。在上面这个转换中,就包括了表输入、值映射、去除重复记录、表输出这 4 个步骤;
- Hop(跳跃线):用来在转换中连接 Step。它代表了数据的流向。
-
- 如何创建 Job(作业)
- 完整的任务,实际上是将创建好的转换和作业串联起来。在这里 Job 包括两个概念:Job Entry、Hop。
- Job Entry(工作实体):Job Entry 是 Job 内部的执行单元,每一个 Job Entry 都是用来执行具体的任务,比如调用转换,发送邮件等。
- Hop:指连接 Job Entry 的线。并且它可以指定是否有条件地执行。
- 在 Kettle 中,你可以使用 Spoon,它是一种一种图形化的方式,来让你设计 Job 和 Transformation,并且可以保存为文件或者保存在数据库中
- 案例 1:如何将文本文件的内容转化到 MySQL 数据库中
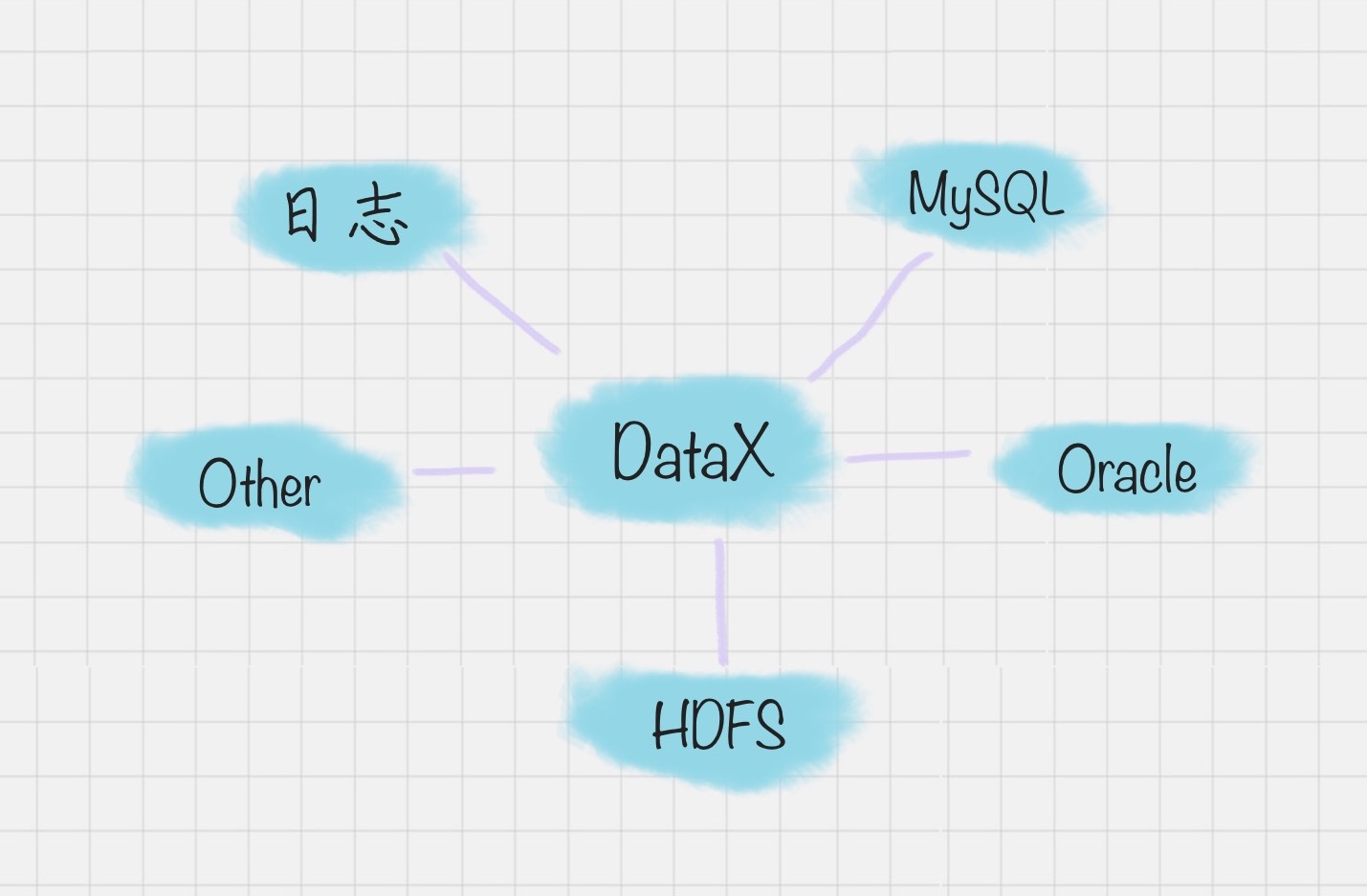
- 阿里开源软件:DataX
- 在以往的数据库中,数据库都是两两之间进行的转换,没有统一的标准,转换形式是这样的:
- 但 DataX 可以实现跨平台、跨数据库、不同系统之间的数据同步及交互,它将自己作为标准,连接了不同的数据源,以完成它们之间的转换。
- Apache 开源软件:Sqoop
- 用来在 Hadoop 和关系型数据库中传递数据。通过 Sqoop,我们可以方便地将数据从关系型数据库导入到 HDFS 中,或者将数据从 HDFS 导出到关系型数据库中。
- Hadoop 实现了一个分布式文件系统,即 HDFS。Hadoop 的框架最核心的设计就是 HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而 MapReduce 则为海量的数据提供了计算。
- 总结
-
相关阅读:
点击按钮生成遮罩层后这个按钮被遮住还可以点击解决办法
关于jq的load不用回调获取其中dom元素方法
移动端默认返回按键,使用h5+修改默认事件
移动端解决input focus后键盘弹出,高度被挤压的问题
模拟移动端上拉超过页面实际高度
软工作业
一周进度汇报
alhpa阶段回顾
一周进度汇报
一周进度汇报
-
原文地址:https://www.cnblogs.com/minimalist/p/12771825.html
Copyright © 2020-2023
润新知