GIL与Lock
Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要互斥锁lock?
锁的目的是为了保护共享的数据,同一时间只能有一个线程来修改共享的数据
GIT保证了一个进程内有多个线程,只有一个线程执行,保证python垃圾回收线程安全
结论:保护不同的数据就应该加不同的锁,针对不同的数据就应该加不同锁。
GIL 与Lock是两把锁,保护的数据不一样,前者是解释器级别的(当然保护的就是解释器级别的数据,比如垃圾回收的数据(垃圾回收线程)),后者是保护用户自己开发的应用程序的数据,很明显GIL不负责这件事,只能用户自定义加锁处理
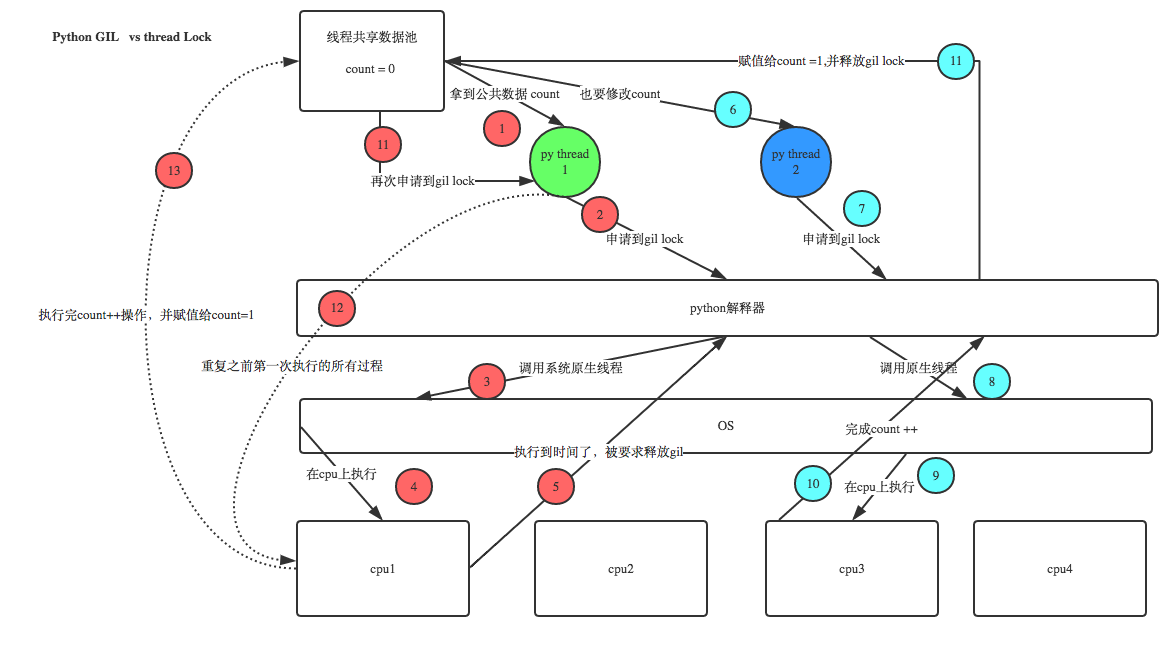
1、100个线程去抢GIL锁,即抢执行权限
2、肯定有一个线程先抢到GIL(暂且称为线程1),然后开始执行,一旦执行就会拿到lock.acquire()
3、极有可能线程1还未运行完毕,就有另外一个线程2抢到GIL,然后开始运行,但线程2发现互斥锁lock还未被线程1释放,于是阻塞,被迫交出执行权限,即释放GIL
4、直到线程1重新抢到GIL,开始从上次暂停的位置继续执行,直到正常释放互斥锁lock,然后其他的线程再重复2 3 4的过程
from threading import Thread from threading import Lock import time def work(): global n lock.acquire() temp=n time.sleep(0.1) n=temp-1 lock.release() if __name__ == '__main__': lock=Lock() n=100 l=[] for i in range(100): p=Thread(target=work) l.append(p) p.start() for p in l: p.join() print(n) # 结果肯定为0,由原来的并发执行变成串行,牺牲了执行效率保证了数据安全,不加锁则结果可能为99 # 0