一、引言
本文是总结斯坦福大学机器学习课程的第五次作业。作业分为两个部分,第一部分:根据水库的水位变化情况,要求使用正则化的线性回归预测大坝的出水量。第二部分:诊断调试机器学习算法和检查偏差和方差的影响。
作业,给出12个测试集数据,特征量只有一个x1反应的水库的水位情况,y是对应的大坝出水量。首先使用一元线性回归拟合12个样本序列,画图得出简单的一元线性回归并不能很好的拟合测试数据,出现欠拟合现象;因此,接下来采用多项式特征来解决欠拟合问题,作业中是使用的8次多项式,此时并没有添加正则项lambda=0,画图得出使用8次多项式拟合训练数据非常好,但是对于测试数据的误差却很大,明显是过度拟合了;下面,采用添加正则项解决过度拟合问题,分别取lambda=1,100,得出lambda=1的时候,训练集误差和测试集误差都比较小;接下来,取lambda为一系列离散(0,0.001,0.003,0.01,0.03...100)的值,然后画出训练集误差和测试集误差随lambda变化的曲线图,从图中大概可以看出当lambda=3的时候,交叉验证集误差最小;最后再测试集中,计算最后模型的泛化误差。
二、实验基础
在样本数目比较少,使用的假设空间的特征量却多的情况下,训练出的模型很容易出现过度拟合现象,即对训练数据拟合地非常好,但是对测试数据的拟合很差。这时候需要在代价函数中添加正则项作为“惩罚”,使震荡起伏的拟合曲线变的比较“光滑”。
线性回归的假设空间的表达式如下所示:

正则化的线性回归代价函数如下所示:

正则化线性回归代价函数对theta偏导的表达式如下图所示:

当假设模型出现欠拟合现象,称为high bias,这时候增加样本数目也不会起到很好的效果。在high bias情况下,学习曲线如下图所示:

当假设模型出现过度拟合现象,称为high variance,这时候增加样本数目可能起到帮助。在high variance情况下,学习曲线如下图所示:

matlab知识
fmincg函数与fminunc函数使用方法几乎一样,都是用于求解最优化问题。fminunc的使用方法如下图所示。第一步需要定义一个costFunction函数,传入参数为theta值,返回jVal为代价函数的代价值,以及gradient为对各个theta求偏导数;第二步定义options,‘GradObj’和'on'表示是打开梯度下降,'MaxIter',200表示是梯度下降迭代次数为200;第三步,将参数带入到fminunc函数中,其中@costFunction为函数句柄,句柄指向定义好的函数表达式,函数表达式的自变量为theta,initial_theta为初始化值。

numel - Number of array elements
This MATLAB function returns the number of elements, n, in array A, equivalent
to prod(size(A)).
三、实验目的
1、学习怎么解决欠拟合和过度拟合问题
2、学习怎么选择正则项参数lambda
3、学习归一化样本数据
4、学习在交叉验证集中找到最好的lambda,然后在测试集中求得模型的泛化误差
四、实验代码
第一部分代码:
%% Initialization
clear ; close all; clc
%% =========== Part 1: Loading and Visualizing Data =============
% We start the exercise by first loading and visualizing the dataset.
% The following code will load the dataset into your environment and plot
% the data.
%
% Load Training Data
fprintf('Loading and Visualizing Data ...
')
% Load from ex5data1:
% You will have X, y, Xval, yval, Xtest, ytest in your environment
load ('ex5data1.mat');
% m = Number of examples
m = size(X, 1);
% Plot training data
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
fprintf('Program paused. Press enter to continue.
');
pause;
%% =========== Part 2: Regularized Linear Regression Cost =============
% You should now implement the cost function for regularized linear
% regression.
%
theta = [1 ; 1];
J = linearRegCostFunction([ones(m, 1) X], y, theta, 1);
fprintf(['Cost at theta = [1 ; 1]: %f '...
'
(this value should be about 303.993192)
'], J);
fprintf('Program paused. Press enter to continue.
');
pause;
%% =========== Part 3: Regularized Linear Regression Gradient =============
% You should now implement the gradient for regularized linear
% regression.
%
theta = [1 ; 1];
[J, grad] = linearRegCostFunction([ones(m, 1) X], y, theta, 1);
fprintf(['Gradient at theta = [1 ; 1]: [%f; %f] '...
'
(this value should be about [-15.303016; 598.250744])
'], ...
grad(1), grad(2));
fprintf('Program paused. Press enter to continue.
');
pause;
%% =========== Part 4: Train Linear Regression =============
% Once you have implemented the cost and gradient correctly, the
% trainLinearReg function will use your cost function to train
% regularized linear regression.
%
% Write Up Note: The data is non-linear, so this will not give a great
% fit.
%
% Train linear regression with lambda = 0
lambda = 0;
[theta] = trainLinearReg([ones(m, 1) X], y, lambda);
% Plot fit over the data
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
hold on;
plot(X, [ones(m, 1) X]*theta, '--', 'LineWidth', 2)
hold off;
fprintf('Program paused. Press enter to continue.
');
pause;
%% =========== Part 5: Learning Curve for Linear Regression =============
% Next, you should implement the learningCurve function.
%
% Write Up Note: Since the model is underfitting the data, we expect to
% see a graph with "high bias" -- slide 8 in ML-advice.pdf
%
lambda = 0;
[error_train, error_val] = ...
learningCurve([ones(m, 1) X], y, ...
[ones(size(Xval, 1), 1) Xval], yval, ...
lambda);
plot(1:m, error_train, 1:m, error_val);
title('Learning curve for linear regression')
legend('Train', 'Cross Validation')
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 150])
fprintf('# Training Examples Train Error Cross Validation Error
');
for i = 1:m
fprintf(' %d %f %f
', i, error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.
');
pause;
第二部分代码:
%% =========== Part 7: Learning Curve for Polynomial Regression =============
% Now, you will get to experiment with polynomial regression with multiple
% values of lambda. The code below runs polynomial regression with
% lambda = 0. You should try running the code with different values of
% lambda to see how the fit and learning curve change.
%
lambda = 0;
[theta] = trainLinearReg(X_poly, y, lambda);
% Plot training data and fit
figure(1);
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
plotFit(min(X), max(X), mu, sigma, theta, p);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
title (sprintf('Polynomial Regression Fit (lambda = %f)', lambda));
figure(2);
[error_train, error_val] = ...
learningCurve(X_poly, y, X_poly_val, yval, lambda);
plot(1:m, error_train, 1:m, error_val);
title(sprintf('Polynomial Regression Learning Curve (lambda = %f)', lambda));
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 100])
legend('Train', 'Cross Validation')
fprintf('Polynomial Regression (lambda = %f)
', lambda);
fprintf('# Training Examples Train Error Cross Validation Error
');
for i = 1:m
fprintf(' %d %f %f
', i, error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.
');
pause;
%% =========== Part 8: Validation for Selecting Lambda =============
% You will now implement validationCurve to test various values of
% lambda on a validation set. You will then use this to select the
% "best" lambda value.
%
[lambda_vec, error_train, error_val] = ...
validationCurve(X_poly, y, X_poly_val, yval);
close all;
plot(lambda_vec, error_train, lambda_vec, error_val);
legend('Train', 'Cross Validation');
xlabel('lambda');
ylabel('Error');
fprintf('lambda Train Error Validation Error
');
for i = 1:length(lambda_vec)
fprintf(' %f %f %f
', ...
lambda_vec(i), error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.
');
pause;
%% ===================== Part 9: Compute generalization error in test set ============
[error_val, index] = min(error_val);
[theta] = trainLinearReg(X_poly, y, lambda_vec(index));
J = linearRegCostFunction(X_poly_test, ytest, theta, 0 );
fprintf('choose lambda = %f, generalization error in test set: %f
',lambda_vec(index),J);
pause;
第三部分代码:取lambda=1,100,分别画出拟合曲线图和学习曲线。如图5,6,7,8
%% =========== Part 7: Learning Curve for Polynomial Regression =============
% Now, you will get to experiment with polynomial regression with multiple
% values of lambda. The code below runs polynomial regression with
% lambda = 0. You should try running the code with different values of
% lambda to see how the fit and learning curve change.
%
lambda = 1;
[theta] = trainLinearReg(X_poly, y, lambda);
% Plot training data and fit
figure(1);
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
plotFit(min(X), max(X), mu, sigma, theta, p);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
title (sprintf('Polynomial Regression Fit (lambda = %f)', lambda));
figure(2);
[error_train, error_val] = ...
learningCurve(X_poly, y, X_poly_val, yval, lambda);
plot(1:m, error_train, 1:m, error_val);
title(sprintf('Polynomial Regression Learning Curve (lambda = %f)', lambda));
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 100])
legend('Train', 'Cross Validation')
fprintf('Polynomial Regression (lambda = %f)
', lambda);
fprintf('# Training Examples Train Error Cross Validation Error
');
for i = 1:m
fprintf(' %d %f %f
', i, error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.
');
pause;
%% =========== Part 7: Learning Curve for Polynomial Regression =============
% Now, you will get to experiment with polynomial regression with multiple
% values of lambda. The code below runs polynomial regression with
% lambda = 0. You should try running the code with different values of
% lambda to see how the fit and learning curve change.
%
lambda = 100;
[theta] = trainLinearReg(X_poly, y, lambda);
% Plot training data and fit
figure(1);
plot(X, y, 'rx', 'MarkerSize', 10, 'LineWidth', 1.5);
plotFit(min(X), max(X), mu, sigma, theta, p);
xlabel('Change in water level (x)');
ylabel('Water flowing out of the dam (y)');
title (sprintf('Polynomial Regression Fit (lambda = %f)', lambda));
figure(2);
[error_train, error_val] = ...
learningCurve(X_poly, y, X_poly_val, yval, lambda);
plot(1:m, error_train, 1:m, error_val);
title(sprintf('Polynomial Regression Learning Curve (lambda = %f)', lambda));
xlabel('Number of training examples')
ylabel('Error')
axis([0 13 0 100])
legend('Train', 'Cross Validation')
fprintf('Polynomial Regression (lambda = %f)
', lambda);
fprintf('# Training Examples Train Error Cross Validation Error
');
for i = 1:m
fprintf(' %d %f %f
', i, error_train(i), error_val(i));
end
fprintf('Program paused. Press enter to continue.
');
pause;
五、实验结果
上面第一部分拟合的曲线如下图所示:图1中红色的叉是样本点,蓝色的直线是我们通过线性回归拟合的模型。图2是学习曲线。
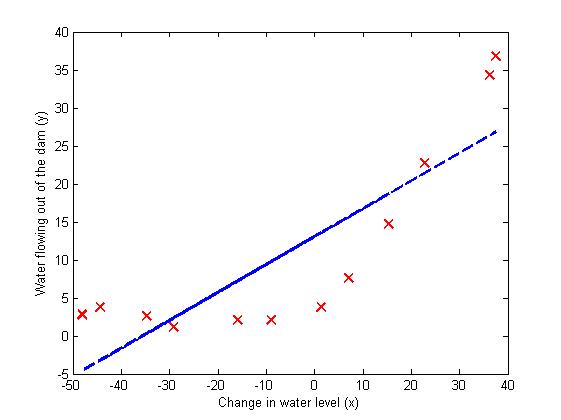

图1 图2
使用的线性假设空间表达式如下图所示:
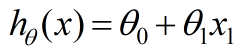
通过上面两个图发现这个简单的线性模型并不能很好的拟合样本序列。因此解决办法是:采用多项式特征。在这个作业中采用的是8次多项式,degree=8,表达式如下图所示:
 等价于下面表达式:
等价于下面表达式:

这时候因为每个特征量之间的差异很大(比如x=10,x的8次方之后100000000),所以需要对每个特征量进行归一化处理,使用的是matalb的featureNormalize函数。归一化之后,使用训练集数据训练假设空间,得到拟合曲线和学习曲线如下图所示:

图三 图四
图三,得出的假设模型对训练数据拟合的非常好,并且获得一个很小的训练集误差,但是从图四发现当x>40的时候,曲线急剧下降,原因是多项式过于复杂,导致了过度拟合现象。从图四的学习曲线也可以看出来,训练集误差很小,但是在交叉验证集上的误差却很大。一种解决过度拟合的方法是在代价函数中增加正则项,如下图所示:
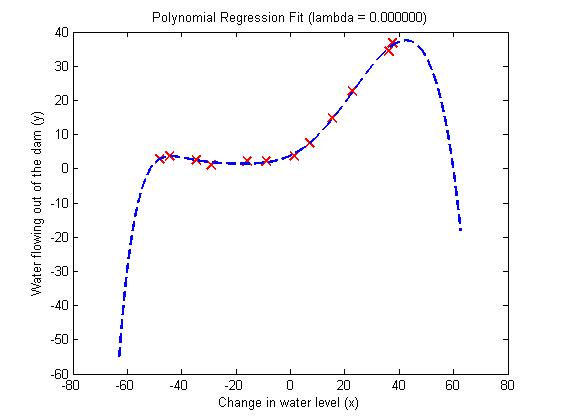
取lambda=1,100分别得到图5,图6和图7,图8。
从图中得出结论:lambda=1,训练出的曲线可以很好的拟合训练数据,同时训练集误差以及交叉验证集误差都比较低,没有high-bias和high-variance问题,很好的解决上面的过度拟合问题。lambda=100,训练出的曲线不能拟合训练数据,同时训练集误差和交叉验证集误差都很大。
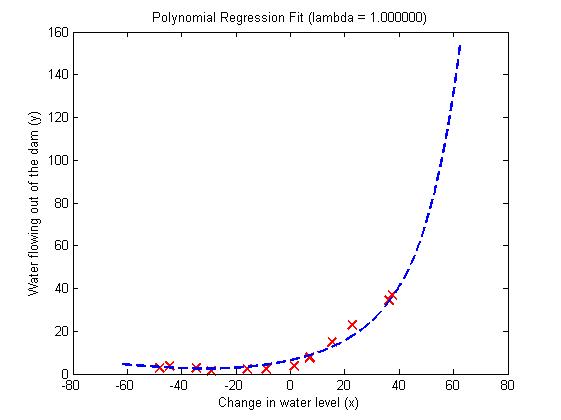

图5 图6
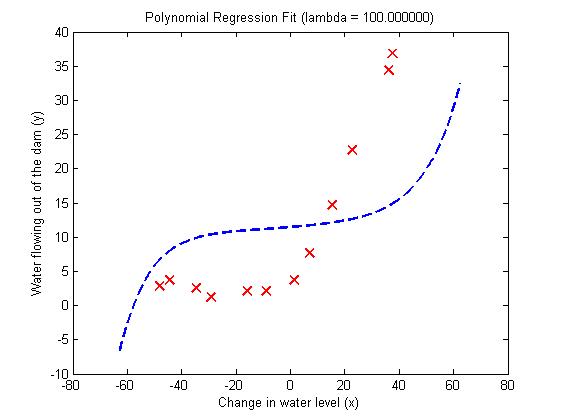

图7 图8
下面将lambda取一系列离散值。作业中取 lambda_vec = [0 0.001 0.003 0.01 0.03 0.1 0.3 1 3 10]'。然后画出训练集误差和交叉验证集误差随着lambda的变化的图。如图9
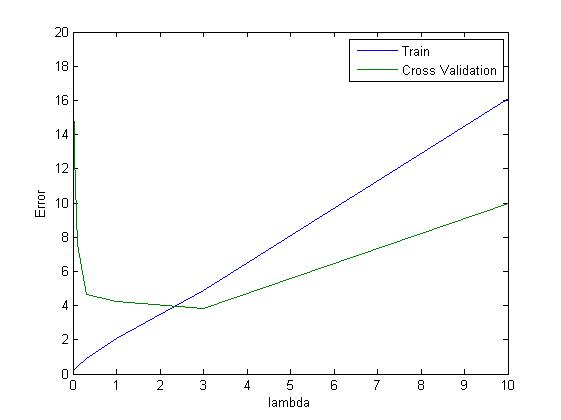
图9
当交叉验证集误差最小时,取得合适的lambda,大概在lambda=3交叉集误差最小。在选择了最好的lambda=3之后,接下来使用测试集数据计算模型的泛化误差。得泛化误差:3.859888