1、定义
散列(Hash,哈希)是一种对数据的处理方法,通过某种特定的算法将要检索的项与用来检索的索引(称为散列,或者散列值)关联起来,然后可以生成一种便于搜索的数据结构(称为散列表)。
c++11中增加了获得hash值的方法,通过hash,hash是实现了operator()的类,所以其对象是函数对象:
//template<class Key > struct hash; auto hashValue = std::hash<std::string>()("hello");
2、散列的常见应用:
散列常用作一种数据安全的方法,由一串数据中经过散列算法计算出来的资料指纹(data fingerprint),经常用来识别资料是否有被窜改,以保证资料确实是由原创者所提供。
散列算法的另一用途是用来加密的密码,由于散列算法所计算出来的散列值(Hash Value)具有不可逆(无法逆向演算回原本的数值)的性质,因此可有效的保护密码。
散列表就是使用散列函数将键名和键值关联起来的数据结构,c++中的unordered_map、unordered_set底层实现使用这种数据结构来保存数据。
3、unordered_map
unordered_map的基本原理:
使用一个下标范围比较大的数组来存储元素。将每个键映射到0到数组大小这个范围中的某个数,将键值放到这个单元中存储,这个函数称为散列函数;散列函数具体来说就是使每个元素的键都与一个函数值(即数组下标)相对应,用这个数组单元(称为桶)来存储这个元素。但是,不能够保证每个元素的键与存储单元一一对应的,有可能出现对于不同的元素却计算出了相同的桶号,在这种情况下不同的元素被存储到了相同的数组单元中,这就称为“冲突(碰撞)”,所以还要有方法来处理这种情况,即为“解决冲突”,比如如果得到的哈希地址冲突(该位置上已存储数据)的话就将这个数据与原数据组成链表存放,如下图的B、D、F桶处所示:
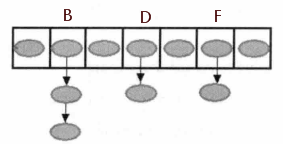
对于unordered_map插入元素的过程是:
①、通过hash函数得到key的hash值
②、得到桶号(一般为hash值对整个数组大小求模获得)
③、存放key和value在桶内。
unordered_map查找元素的过程是:
①、通过hash函数得到key的hash值
②、得到桶号(一般为hash值对整个数组大小求模获得)
③、比较桶的内部元素是否与key相等,若都不相等,则没有找到,相等的话取出value值。
根据unorder_map的查询和插入规则可知其查询、插入和删除操作不随数据量的增长而增大,时间复杂度是常数级别O(1)。
4、map与unordered_map
由于map内部使用的数据机构,所以map中元素会自动排序存放,unordered_map则不会。
map是根据key自动排序的,对于key的类型必须支持<比较操作,所以对于自定义类型的元素应该增加operator<()函数,eg:


#include <map> class CFoo { friend bool operator<(const CFoo& f1, const CFoo& f2); int m_iNum = 0; }; bool operator<(const CFoo& f1, const CFoo& f2) { return f1.m_iNum < f2.m_iNum; } map<CFoo, int> m; m.insert(pair<CFoo, int>(CFoo(), 3));
unordered_map中key如果是自定义类型的话定义unordered_map的时候需要传入模板参数列表的第三个和第四个参数,分别用来指定散列函数和解决冲突时使用的判断是否相等,eg:
#include <unordered_map> #include "boostfunctionalhash.hpp" class CFoo { public: int m_iNum = 0; string m_str; }; struct foo_hash_value { size_t operator()(const CFoo& p) { //std::hash<int> h; //return h(p.m_iNum); size_t seed = 0; boost::hash_combine(seed, p.m_iNum); boost::hash_combine(seed, p.m_str); return seed; } }; struct foo_is_equal { bool operator()(const CFoo& f1, const CFoo& f2) { return f1.m_iNum == f2.m_iNum; } }; std::unordered_map<CFoo, int, foo_hash_value, foo_is_equal> m;
5、CRC与MD5、SHA-1
CRC、MD5、SHA1都是通过对数据进行计算,来生成一个校验值,该校验值可以用来校验数据的完整性。
CRC不是hash算法,而是采用多项式除法,其校验值的长度跟其多项式有关系,一般为16位(CRC16)或32位(CR32),其计算效率比MD5和SHA1要高很多,但其安全性相对于MD5和SHA1要弱很多,一般只用作通信数据的校验。
MD5和SHA1使用的是hash算法,由于hash值具有不可逆性,无法通过hash值获得对应的原值,所以它们又经常用作数据加密。生成的校验值MD5是128位(16个字节),SHA1是160位(20个字节),SHA1的安全性比MD5还要高一点。如果我们想要通过加密后的值获得原加密之前的值,我们可以使用自己的加密算法或者使用非对称加密。比如使用非对称加密即为使用公钥对数据加密后进行保存,通过私钥对加密后的数据进行解密。常用的非对称加密算法有RSA、Elgamal。