1. 模块和包
- 容器:列表、元组、字符串、字典等,对数据的封装
- 函数:对语句的封装
- 类:对方法和属性的封装,即对函数和数据的封装
而模块(module)就是个程序,一个.py 文件,模块分为三类:
- Python 标准库:如 time、random 等
- 第三方模块:如 requests、beautiful 等
- 应用程序自定义模块:用户自定义模块
随机程序代码越写越多,每个文件里面的代码越来越长,越来越不容易维护。使用模块的好处:
- 模块化代码: 将不同功能的代码归类,提高代码的可维护性
- 避免重复造轮子:编写代码可以不必从零开始,可以引用别人已经写好的模块,Python 有很多优秀的第三方模块
- 命名空间:每个模块单独维护一个命名空间,不同模块相同函数名、变量名不会有冲突
Tips:自定义模块的时候,不要与内置的模块名有冲突,不然会影响内置模块
1.1 包
为了避免不同的人编写的模块名相同,Python 引入了按目录来组织模块的方法 —— 包(Package)
不同包下的模块,名字相同不会有冲突,只要顶层的包名不冲突就行。
如何创建一个包:
- 创建一个文件夹,里面存放相应模块文件,文件夹名字即为包名
- 在文件夹中创建一个
__init__.py文件,可以为空
1.2 导入模块
导入模块的几种常用方法:
>>> import 模块1, 模块2... # sys.path:搜索路径
>>> from 模块名 import 函数名
>>> from 模块名 import * # 导入模块中所有函数,不推荐,导致命名空间优势荡然无存
from one.two import main
>>> import 模块名 as newname # 当模块名比较长时,我们可以给它去个新名字,使用起来更方面
导入模块后,就需要使用模块中的函数,我们可以使用 模块名.函数名 或直接调用函数即可:
# calc.py
def add(x, y):
return x + y
import calc # 导入模块,使用 模块名.函数名 的方法调用函数
calc.add(4, 6)
from calc import add # 直接把函数名也导入,可以直接调用函数
add(4, 6)
不同包中的模块导入方法
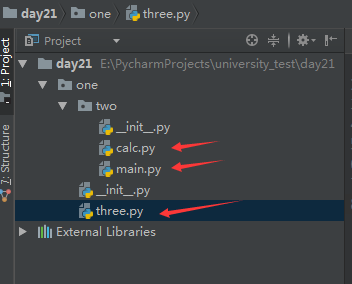
three.py 是个模块,two 是个包,两者同级。要想在 three.py 中导入 calc.py:
from one.two import calc
1.3 __name__ == '__main__'
有时我们在阅读别人的源代码时,经常看到代码中有 if __name__ == '__main__',它有什么作用呢?
- 在被调用文件上:用于被调用文件的测试
- 在执行文件上: 不想这个文件成为被调用文件
# calc.py
pi = 3.14
def main():
print('pi:', pi)
main()
现在我们想在bin.py 中,调用 cacl.py 中的 add()函数计算两个数的和:
# bin.py
from calc import pi
def calc_round_area(radius):
return pi * (radius ** 2)
def main():
print('round area:', calc_round_area(2))
main()
pi: 3.14
round area: 12.56
bin.py 把 main()函数也执行了,而不是我们想要的只执行calc_round_area() 函数。在有些时候我们只想 被调用模块的部分程序(函数)被调用,而不是全部程序。我们可以在 被调用模块中添加 if __name__ == '__main__',将不想被调用的函数放入里面即可,能被调用的不放入其中(开发相应的接口即可)。
# calc.py
pi = 3.14
def main():
print('pi:', pi)
if __name__ == '__main__':
main()
from calc import pi
def calc_round_area(radius):
return pi * (radius ** 2)
def main():
print('round area:', calc_round_area(2))
main()
我们再执行 bin.py, 发现只执行:
round area: 12.56
函数也是对象,每个对象都有一个__name__ 属性,在程序中,我们查看__name__ 属性为 '__main__',因此为 True:
# calc.py
....
print(__name__)
'__main__'
一旦我们引入到其他模块中,__name__ 属性就变成了 被引入模块的路径,而不再是 __main__,因此为 False,即不能执行被调用模块 if __name__ == '__main__' 的程序。
# bin.py
...
print(calc.__name__)
'calc'
另一个作用是不想这个模块文件称为被调用文件,我们将所有的调用方式都放入__name__==__main__下,没有开发接口,别人就不能调用模块中的任何函数了。
1.4 搜索路径
模块是一个 .py 文件,那么必然有个路径。每次导入模块时,首先在内置在解释器中找是否有这个模块(如:sys、time 模块),再搜索安装目录。下载安装的模块一般都是在 Python 安装路径下的 Lib 目录下,也可以使用 sys.path 查看:
import sys
sys.path
['', 'C:\Users\HJ\Anaconda3\python36.zip', 'C:\Users\HJ\Anaconda3\DLLs', 'C:\Users\HJ\Anaconda3\lib', 'C:\Users\HJ\Anaconda3', 'C:\Users\HJ\Anaconda3\lib\site-packages', 'C:\Users\HJ\Anaconda3\lib\site-packages\win32', 'C:\Users\HJ\Anaconda3\lib\site-packages\win32\lib', 'C:\Users\HJ\Anaconda3\lib\site-packages\Pythonwin']
对于自定义的模块,可以使用 sys 模块将其路径添加到 sys.path 中,需要注意的是,这是临时修改,永久修改需要修改系统环境变量。
sys.path.append('C:\Python36\test\')
BASE_DIR
每次这样将绝对路径添加到 sys.path 中,一旦将程序拷贝别人使用,就会出现没有这个模块的问题,我们可以借用 BASE_DIR 来将文件本身的路径添加到 sys.path 中。
# __file__ :拿到文件名,在 Pycharm 中之所以看到的是绝对路径,是 Pycharm 给我们自动添加的
# os.path.abspath(__file__) 可以拿到文件的绝对路径
import sys, os
BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.append(BASE_DIR)
2. 模块
2.1 time 模块
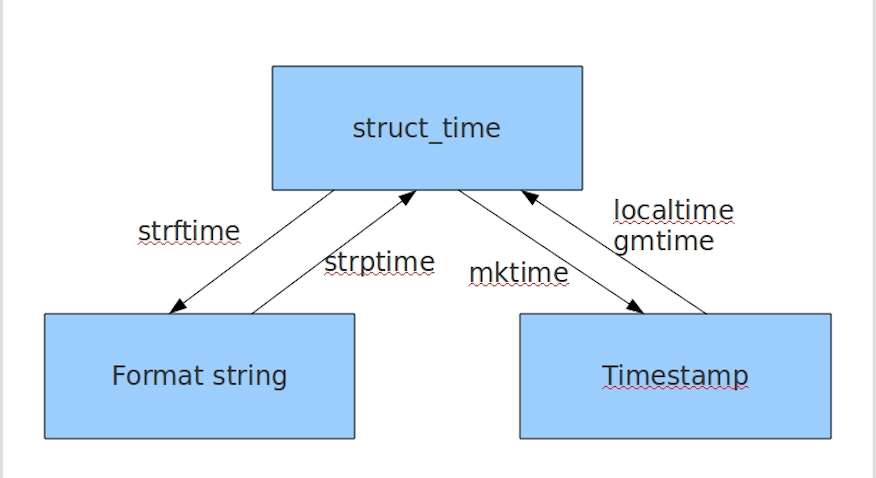
Python 中三种时间表示法:
- 时间戳(timestamp):时间戳是从 1970年1月1日 00:00:00 开始按秒计算的偏移量,返回的是浮点型
- 结构化时间(struct_time):共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
- 格式化的时间字符串:格式化后的时间,如
1970-1-1 00:00:00
import time
# 1. time():返回当前时间的时间戳
>>> time.time()
1542195047.3042223
# 2. localtime([secs]):将一个时间戳转换为当前时区的结构化时间,未指定时间戳则以当前时间为准
>>> time.localtime() # 查看当前时间的结构化时间
time.struct_time(tm_year=2018, tm_mon=11, tm_mday=14, tm_hour=19, tm_min=32, tm_sec=51, tm_wday=2, tm_yday=318, tm_isdst=0)
>>> time.localtime(1432195047.3042223) # 传入时间戳,查看某个时间的结构化时间
time.struct_time(tm_year=2015, tm_mon=5, tm_mday=21, tm_hour=15, tm_min=57, tm_sec=27, tm_wday=3, tm_yday=141, tm_isdst=0)
# 3. gmtime([secs]):与 localtime()类似,将一个时间戳转换为UTC时区(0时区)的struct_time。时间标准时间
# UTC:英国格林威治,全球每 15 度为一个时区,总共 24 个时区,格林威治为时间标准时间,中国为东八区,也就是说中国要比时间标准时间早八个小时
>>> time.gmtime() # 比中国晚早 8 小时
time.struct_time(tm_year=2018, tm_mon=11, tm_mday=14, tm_hour=11, tm_min=34, tm_sec=50, tm_wday=2, tm_yday=318, tm_isdst=0)
# 4. mktime(p_tuple):将结构化时间转换为时间戳,参数为结构化的时间
>>> time.mktime(time.localtime()) # 将当前时间的结构化时间转换为时间戳
1542195406.0
# 5. strftime(format[, t]):将结构化时间转换为字符串时间,第一个参数为格式化成的时间格式,第二个为结构化时间, %X 表示时分秒,中间的分隔符随意
>>> time.strftime('%Y-%m-%d %X', time.localtime()) # 将当前时间的结构化时间转换为字符串时间
'2018-11-14 19:39:22'
# 6. strptime(string,format):将一个格式化时间字符串转换为结构化时间,与 strftime()是逆操作
>>> time.strptime('2018:11:14:19:42:56', '%Y:%m:%d:%X')
time.struct_time(tm_year=2018, tm_mon=11, tm_mday=14, tm_hour=19, tm_min=42, tm_sec=56, tm_wday=2, tm_yday=318, tm_isdst=-1)
# 7. asctime([t]):将结构化时间转换为一个固定形式的字符串时间,默认为 time.localtime()
>>> time.asctime()
'Wed Nov 14 19:45:57 2018'
# 8. ctime([secs]):将时间戳转换为一个固定形式的字符串时间,默认为 time.time()
>>> time.ctime()
'Wed Nov 14 19:46:07 2018'
>>> time.ctime(1542195047.3042223)
'Wed Nov 14 19:30:47 2018'
# 9. sleep(secs):线程推迟指定的时间运行,单位为秒
>>> time.sleep(3)
# 10. clock():不同系统上含义不同,UNIX 系统上,返回的是 “进程时间”。Windows 系统上,第一次调用为进程运行实际时间,第二次调用为第一次调用到现在的运行时间,即两次调用的时间差。
>>> time.clock()
datetime 模块
datetime 模块也是一个时间模块,只需记得一些一个方法即可:
import datetime
print(datetime.datetime.now()) # 查看当前时间的结构化时间
2018-11-14 16:56:12.065709

2.2 random 模块
随机模块,产生一个随机数
import random
# 1. random():随机产生一个 0 ~ 1 的浮点数
>>> random.random()
0.42091646162129426
# 2. randint(start, stop):产生一个 start ~ stop 的随机整数,包含左右 [start, stop]
>>> random.randint(1, 3)
2
# 3. randrange(start,stop[,step]): 产生一个指定递增基础集合中的一个随机整数,基数缺省为 1 ,[start, stop)
>>> random.randrange(10, 20, 2) # 返回 [10, 20) 间的偶数
18
>>> random.randrange(10, 20, 3) # 返回 [10, 20) 间的其他数
13
>>> random.randrange(10, 20) # 返回 [10, 20) 间的任意一个数
17
# 4. choice(seq):在一个序列中随机获取一个元素
>>> random.choice([1, 2, 3])
2
>>> random.choice('hello')
'l'
# 5. sample(seq, k):从指定序列中随机获取指定长度 的片段,不会修改原有序列
>>> random.sample([1, 2, 3, 4], 2) # 获取两个元素
[2, 3]
# 6. uniform(start,stop):随机产生一个 start ~ stop 范围的浮点数
>>> random.uniform(1, 3)
2.4704091068940937
# 7. shuffle(seq):打乱列表中元素顺序
>>> n = [1, 2, 3]
>>> random.shuffle(n)
>>> n
[1, 3, 2]
随机验证码生成:
import random
def v_code():
"""
产生一个四个字符组成的随机验证码
:return: 验证码
"""
res = ''
for i in range(4):
num = random.randint(0, 9) # 产生一个 0~9 的随机整数
alf = chr(random.randint(65, 90)) # 产生一个 65~90 的随机整数,再用 chr()转换为大写字母
ret = random.choice([num, alf]) # 从 num、alf 中随机选取一个
res += str(ret)
return res
res = v_code()
print(res)
S3H6
2.3 os 模块
os 模块与操作系统的交互的接口
import os
# getcwd():获取当前工作目录
>>> os.getcwd()
'E:\电脑软件\cmder'
# chdir(path):改变当前工作目录,支持绝对路径和相对路径
>>> os.chdir('..') # 返回上一层目录
>>> os.chidr('E:\')
>>> os.getcwd()
E:\
# listdir(path='.'):列出指定目录下所有文件和目录
>>> os.listdir()
['.ipynb_checkpoints', 'bin', 'Cmder.exe', 'config', 'icons', 'LICENSE', 'README.md', 'SUMMARY.md', 'Untitled.ipynb', 'vendor', 'Version 1.3.6.678']
>>> os.listdir('E:\')
# mkdir(path):创建文件夹,若该文件夹存在,抛出 FileExistsError 异常
>>> os.mkdir('test')
# makedirs(path):创建多层目录
>>> os.makedirs('dir1/dir2') # 适用 Linux 和 win
>>> os.makedirs(r'E:ac') # 仅适用 win
# remove(path):删除指定文件,不能删除目录
>>> os.remove(r'E:aca.txt')
# rmdir('dir'):删除单个目录,若目录为空,则无法删除
>>> os.rmdir(r'E:ac')
# removedirs(path):若目录为空,则删除。并递归到上一级目录,如若也为空,则删除,依次类推
>>> os.removedirs(r'E:a')
# rename(old,new):重命名文件或文件夹
>>> os.chdir(r'E:\')
>>> os.getcwd()
'E:\'
>>> os.mkdir('a')
>>> os.rename('a', 'b')
# system("bash command") 运行shell命令,直接显示
>>> os.system('calc') # 调用系统内置计算器
# stat('path/filename'):查看文件/目录信息(如:创建时间、修改时间、字节等)
# st_size=7:文件多少个字节、st_atime:用户上一次的访问时间、st_mtime:上一次修改的时间、st_ctime:创建时间
>>> os.stat(r'E:a.txt')
os.stat_result(st_mode=33206, st_ino=1125899906882595, st_dev=646140012, st_nlink=1, st_uid=0, st_gid=0, st_size=7, st_atime=1542207918, st_mtime=1542207963, st_ctime=1542207918)
# sep:输出当前操作系统特定的路径分隔符,win 下为 \,Linux 为 /
>>> os.sep
'\'
# linesep:输出当前平台使用的行终止符,win下为
,Linux 下为
>>> os.linesep
'
'
# pathsep 输出用于分割文件路径的字符串 win下为;,Linux下为
>>> os.pathsep
';'
# name 输出字符串指示当前使用平台。win->'nt'; Linux->'posix'
>>> os.name
'nt'
# environ 获取系统环境变量
>>> os.envirom
# curdir:返回当前目录:(.)
>>> os.curdir
'.'
# pardir:获取当前目录的父目录字符串名:(..)
>>> os.pardir
'..'
# walk(path):返回指定路径下所有子目录,结果是一个三元组(路径,[包含目录],[包含文件])
>>> for i in os.walk(r'E:'):
... print(i)
...
('E:\b', [], ['a.txt'])
os.path 模块
import os
# abspath(path):返回文件或目录规范化的绝对路径
>>> os.path.abspath('a.txt')
'E:\b\a.txt'
# split(path):将 path 分割成目录和文件名二元组返回
>>> os.path.split(r'E:a.txt')
('E:\b', 'a.txt')
>>> os.path.split(os.path.abspath('a.txt'))
('E:\b', 'a.txt')
# splitext(path):分割文件拓展名
>>> os.path.splitext(os.path.abspath('a.txt'))
('E:\b\a', '.txt')
# dirname(path):去掉文件名,返回目录,即返回 os.path.split[0]
>>> os.path.dirname(r'E:a.txt')
'E:\b'
# basename(path):去掉目录,返回文件名,即返回 os.path.split[1]
>>> os.path.basename(r'E:a.txt')
'a.txt'
# exists(path):如果 path 存在,返回 true,否则为 false
>>> os.path.exists(r'E:')
True
# isabs(path):如果 path 是绝对路径,返回 true,否则为 false
>>> os.path.isabs(r'E:')
True
# isfile(path):判断指定路径是否存在且是一个文件
>>> os.path.isfile(r'E:')
False
# isdir(path):判断指定路径是否存在且是一个目录
>>> os.path.isdir(r'E:')
True
# join(path1[, path2[,...]]):拼接多个路径,第一个绝对路径之前的参数将被忽略
>>> a = r'E:a'
>>> b = r'ca.txt' # 相对路径
>>> os.path.join(a, b)
'E:\a\b\c\a.txt'
>>> a = r'E:a'
>>> b = r'F:ca.txt' # 第一个绝对路径之前的参数将被忽略
>>> os.path.join(a, b)
'F:\c\a.txt'
>>> a = r'E:a'
>>> b = r'E:da.txt' # 第一个绝对路径之前的参数将被忽略
>>> os.path.join(a, b)
'E:\d\a.txt'
# getatime(path):返回 path 所指向的文件或目录的最后存取时间
>>> os.path.getatime(r'E:a.txt')
1542207918.4124079
# getmtime(path):返回 path 所指向的文件或目录的最后修改时间
>>> os.path.getmtime(r'E:a.txt')
1542207963.2649732
# getctime(path):返回 path 所指向的文件或目录的创建时间
>>> os.path.getctime(r'E:a.txt')
1542207918.4124079
# getsize(path):返回 path 所指向的文件或目录的大小(字节)
>>> os.path.getsize(r'E:a.txt')
7
图片爬取全代码:
# 图片爬取全代码
import requests
import os
url = 'https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=2079998410,926856509&fm=26&gp=0.jpg'
root = r'E:\pics\'
path = root + url.split('/')[-1]
try:
if not os.path.exists(root): # 目录不存在,则新建
os.mkdir(root)
if not os.path.exists(path): # path 不存在就爬取,存在就打印 文件已经存在
r = requests.get(url)
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print('保存文件成功')
else:
print('文件已经存在')
except:
print('爬取失败')
2.4 sys 模块
import sys
# exit(n):退出程序,正常退出是 exit(0)
>>> exit(0)
attempt to call a nil value
# version:获取 Python 解释器程序的版本信息
>>> sys.version
'3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)]'
# path:返回模块的搜索路径,初始化时使用 PythonPath 环境变量的值
>>> sys.path
# platform:返回操作系统平台名称
>>> sys.platform
'win32'
argv 变量
argv 命令行参数 List,第一个元素是程序本身路径,如允许 python hello.py 获得的 sys.argv 就是 ['hello.py'],允许 python hello.py poost 获得的 sys.argv 就是 ['hello.py', 'post']。
# hello.py
#!/usr/bin/env python3 # 任何平台都能使用
# -*- coding: utf-8 -*- # 编码格式
'一个测试 avgv 变量的模块'
__author__ = 'Hubery_Jun'
import sys
def test():
args = sys.argv
if len(args) == 1:
print('Hello, world')
elif len(args) == 2:
print('Hello, %s' % args[1])
else:
print('Too many arguments')
if __name__ == '__main__':
test()
在命令行运行 hello.py:
$ E:PycharmProjectsuniversity_testday21onefour>python shenzhen_work.py
Hello, world
$ E:PycharmProjectsuniversity_testday21onefour>python shenzhen_work.py rose
Hello, rose
Python shell 交互环境中:
>>> import hello
>>> hello.test()
Hello world
FTP 上传下载功能简单实现
# ftp.py
import sys
def test():
command = sys.argv[1]
path = sys.argv[2]
# 上传
if command == 'post':
print('post 请求方式')
# 下载
elif command == 'get':
print('get 请求方式')
print('下载路径为 %s' % path)
if __name__ == '__main__':
test()
命令行中运行 ftp.py
$ python ftp.py get E:/download/
get 请求方式
下载路径为 E:/download/
进度条实现
import time
import sys
for i in range(20):
sys.stdout.write('#')
time.sleep(0.1)
sys.stdout.flush()
2.5 json 模块
之前我们学过 eval 方法可以将一个字符串处理成 Python 对象,对于普通的数据类型,eval 可以处理,但是对于特殊的数据了新,eval 就不管用了。json 适用于任何语言的数据交互,写入文件的必须是字符串类型。
序列化
把对象(变量)从内存中变成可存储或传输的过程称为 序列化,也叫 pickling,其他语言中称之为 serialization,marshalling,flattening等。反过来把变量内容从序列化的对象重新读取到内存中称之为 反序列化,即 unpickling。
json
为了在不同编程语言之间能够互相传输,就必须把对象序列化为标准格式,如:XML,但最好的是 JSON。因为 json 表示出来的就是一个字符串,可以被任何语言读取,也方便存储到磁盘或通过网络传输,而且比 XML 更快,更可以在 Web 页面上读取,非常方便。
json 表示的对象就是标准的 JavaScript 语言的对象,json 和 Python 内置的数据类型对应关系如下:
| json 类型 | Python 类型 | json 类型 | Python 类型 |
|---|---|---|---|
| {} | dict | [] | list |
| 'string' | str | 1234.56 | int 或 float |
| true/false | true/false | null | None |
# 序列化
import json
dic = {'name': 'rose', 'age': 18} # type(dic) 为 <class 'dict'>
dic_sec = json.dumps(dic) # 将 Python 的数据类型转换为 json (字符串)数据类型,type(dic_sec) 为 <class 'str'>
f = open('test.json', 'w')
f.write(dic_sec) # 将 json 数据写入一个文件中
f.close()
# dic_sec = json.dumps(dic)
# f.write(dic_sec)
# 等价于 json.dump(dic, f)
# 反序列化
import json
f = open('test.json', 'r')
data = json.loads(f.read()) # 等价于 data = json.load(f)
f.close()
type(data) # <class 'dict'>
Tips:
json字符串是双引号,不认单引号。无论数据是怎样创建的,只要满足json格式(即双引号),就可以json.loads出来,不一定非要dumps的数据才能loads
2.6 pickle 模块
pickle 模块与 json 模块类似,用法一致,去区别在于 pickle 模块将数据序列化为 字节型,而 json 序列化为 字符串型。
pickle 只能用于 Python,而且版本不同也有可能不同,因此只能用来保存不那么重要的数据。支持函数、类。
# 序列化
import pickle
dic = {'name': 'rose', 'age': 18}
dic_str = pickle.dumps(dic) <class 'bytes'>
f = open('text.pkl', 'wb')
f.write(dic_str) # pickle.dump(dic, f)
f.close()
# 反序列化
import pickle
f = open('text.pkl', 'rb')
data = pickle.loads(f.read()) # data = pickle.load(f)
print(data)
f.close()
2.7 shelve 模块
与 json、pickle 类似,也是用于数据传输。只有一个open函数,返回类似字典的对象,可读可写 key 必须为字符串,而值可以是 python 所支持的数据类型。
import shelve
f = shelve.open(r'shelve.txt')
# 存储(会产生三个文件:xxx.bak、xxx.dat、xxx.dir)
# f['info'] = {'name': 'rose', 'age': 18} # f 相当于一个空字典,写操作相当于给字典赋值
# f.close()
print(f.get('info')['name']) # 读取操作(类似于字典取值)
----------------------------------------------------------
rose
2.8 XML 模块
xml 是实现不同语言或程序之间进行数据交换的协议,跟 json 差不多,但 json 使用起来更简单。xml 比 json 出现更早,早前不同语言之间数据交换都是 xml,现在仍然有很多公司、语言在用,但 json 是未来趋势。
import xml.etree.ElementTree as et
tree = et.parse('test.xml') # 解析 text.xml
root = tree.getroot() # 获取根节点
# node.tag:获取标签名
# node.attrib:获取属性名
# node.text:获取文本内容
# root.findall('node_name') 查看根节点下所有叫 node_name 的标签
# node.find('node_name') 查看某个标签下某个子标签(子节点)
# root.iter('node_name') 查看根节点下所有叫 node_name 的标签
# node.set('属性名', '属性值') 修改某个节点的属性
# root.remove('node_name') 删除某个节点
# tree.write('text.xml') 不管是删除还是修改都要将修改后的文件写入原文件中
- findall:查找的是所有某个节点
- find:查找某个节点,当有多个时,只返回第一个
country = root.find('country')
print(country.tag, country.attrib)
rank = country.find('rank')
print(rank.tag, rank.attrib, rank.text)
country {'name': 'Liechtenstein'}
rank {'updated': 'yes'} 2
XML 文档操作
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
import xml.etree.ElementTree as et
tree = et.parse('test') # 解析(读取)
root = tree.getroot() # 获取根节点
# print(root.tag) # 打印根节点名称
# 遍历 xml 文档
# for country in root:
# # print(country.tag, country.attrib)
# for i in country:
# print(i.tag, i.text)
# # 只遍历所有 year 节点
# for year in root.iter('year'):
# print(year.tag, year.text)
# # 修改
# for year in root.iter('year'):
# new_year = int(year.text) + 3
# year_text = str(new_year)
# year.set('updated', 'yes')
# tree.write('test')
# # 删除
# for country in root.findall('country'):
# rank = int(country.find('rank').text)
# if rank > 50:
# root.remove(country)
# tree.write('test')
生成 xml 文档
使用 Python 也可以手动生成 xml 文档。
import xml.etree.ElementTree as et
new_xml = et.Element('root_node') # 创建一个名为 root_node 的根节点
node = et.SubElemnt(father_node, node, attrib={'key': 'value'}) # 创建一个名为 node 的结点,父节点为 father_node
node.text = 'value' # 设置某个节点的文本内容
ts = et.ElementTree(new_xml) # 生成文档树对象
ts.write('test.xml', encoding='uft-8', xml_declaration=True)
et.dump(new_xml) # 打印生成的格式
import xml.etree.ElementTree as et
new_xml = et.Element('data') # 生成一个名叫 data 的根节点
name = et.SubElement(new_xml, 'name', attrib={'enrolled': 'yes'}) # 创建一个 name 节点,父节点为 new_xml 即 data
age = et.SubElement(name, 'age', attrib={'checked': 'no'}) # 创建一个 age 节点,父节点为 name
sex = et.SubElement(name, 'sex')
sex.text = '33'
ts = et.ElementTree(new_xml) # 生成文档树对象
ts.write('test.xml', encoding='uft-8', xml_declaration=True)
et.dump(new_xml) # 打印生成的格式
生成的 xml 文档:
<!--test.xml-->
<?xml version='1.0' encoding='utf-8'?>
<data>
<name enrolled="yes">
<age checked="no" />
<sex>33</sex>
</name>
</data>
2.9 logging 模块
logging 模块将日志打印到标准输出中,且只显示大于等于 WARNING 级别的日志,默认日志级别为 WARING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),默认的日志格式为日志级别:Logger名称:用户输出消息。
logging 模块有两种输出日志的方法:第一是利用 basicConfig 函数进行相应的配置,第二是 logger 对象输出。
2.9.1 basicConfig 函数
basicConfig() 函数有很多参数,通过更改其中参数可来设定日志输出形式以及格式等,具体参数如下:
- filename:用指定的文件名创建 FileHandle ,这样日志会被存储到指定的文件中。
- filemode:文件打开方式,在指定了 filename 后,默认为 :'a'(追加),可以指定为 'w'(覆盖)
- format:指定 handle 使用的日志显示格式
- datefmt:指定日期时间格式
- level:设置 rootlogger 的日志级别
- stream:用指定的 stream 创建 StreamHandle。可以指定输出到
sys.stderr,sys,stdout(输出到屏幕)或文件f=open('test.log', 'w')(输出到文件中),默认为输出到屏幕。若同时列出了 filename 和 stream 两个参数,则 stream 参数会被忽略。
Format 参数中可能用到的格式化串:
- %(name)s :Logger的名字
- %(levelno)s :数字形式的日志级别
- %(levelname)s :文本形式的日志级别
- %(pathname)s :调用日志输出函数的模块的完整路径名,可能没有
- %(filename)s :调用日志输出函数的模块的文件名
- %(module)s :调用日志输出函数的模块名
- %(funcName)s :调用日志输出函数的函数名
- %(lineno)d :调用日志输出函数的语句所在的代码行
- %(created)f :当前时间,用UNIX标准的表示时间的浮 点数表示
- %(relativeCreated)d :输出日志信息时的,自Logger创建以 来的毫秒数
- %(asctime)s :字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
- %(thread)d :线程ID。可能没有
- %(threadName)s :线程名。可能没有
- %(process)d :进程ID。可能没有
- %(message)s:用户输出的消息
示例:
import logging
logging.basicConfig(
level=logging.DEBUG,
# 当前时间,模块名,行号,等级名,输出信息
format='%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s',
#datefmt='%a, %d %b %Y %H:%M:%S',
#filename='test.log'
)
logging.debug('debug message')
logging.info('info message')
logging.warning('waring message')
logging.error('error message')
logging.critical('critical message')
输出:
2018-11-19 17:04:06,070 logging_test.py [line:10] DEBUG debug message
2018-11-19 17:04:06,071 logging_test.py [line:11] INFO info message
2018-11-19 17:04:06,071 logging_test.py [line:12] WARNING waring message
2018-11-19 17:04:06,071 logging_test.py [line:13] ERROR error message
2018-11-19 17:04:06,071 logging_test.py [line:14] CRITICAL critical message
basicConfig() 函数配置日志不够灵活,而且不能同时输出在屏幕的同时,保存到文件,而 logger 对象恰好可以解决。
2.9.2 logger 对象
logging.basicConfig() 用默认日志格式(Format)为日志系统建立一个默认的流处理器(StreamHandler),设置基础配置(如日志级别等)并加到 root logger(根 Logger中)这几个 logging 模块级别的函数。另一个模块级别的函数 logging.getLogger([name]) 返回一个 logger 对象,如果没有指定名字将返回 root logger。
一个 logger 对象:
import logging
logger = logging.getLogger() # 创建一个 logger 对象
#logger.setLevel('DEBUG') 设定日志等级
fh = logging.FileHandler('log.log') # 创建一个 handle,用于写入日志文件
ch = logging.StreamHandler() # 创建一个 handle,用于输出到屏幕
# 指定日志显示格式
fomatter = logging.Formatter('%(asctime)s %(filename)s [line:%(lineno)d] %(levelname)s %(message)s')
# logger 对象添加多个 fh、ch 对象(既输出到文件中,也输出到屏幕上)
logger.addHandler(fh)
logger.addHandler(ch)
# 各等级日志输出信息
logger.debug('debug message')
logger.info('info message')
logger.warning('waring message')
logger.error('error message')
logger.critical('critical message')
waring message
error message
critical message
默认只输出三个级别,可以通过 logger.setLevel('DEBUG') 设定日志级别。可用的日志级别有logging.DEBUG、logging.INFO、logging.WARNING、logging.ERROR、logging.CRITICAL。
logging 库提供了多个组件:
- Logger:Logger 对象
- Handler:发送日志到文件中或屏幕上
- Filter:过滤日志信息
- Format:指定日志显示格式
Logger 对象提供了应用程序可直接使用的接口,Logger 是一个树形层级结构,输出信息之前要获得一个 Looger 对象(如果没有指定名字,那么就是 root Looger 根)。
两个 logger 对象
logger1 = logging.getLogger('mylogger')
logger2 = logging.getLogger('mylogger')
logger1.setLevel(logging.DEBUG)
logger2.setLevel(logging.INFO)
fh = logging.FileHandler('new_log.log')
ch = logging.StreamHandler()
logger1.addHandler(fh)
logger1.addHandler(ch)
logger2.addHandler(fh)
logger2.addHandler(ch)
logger1.debug('debug message')
logger1.info('info message')
logger1.warning('waring message')
logger1.error('error message')
logger1.critical('critical message')
logger2.debug('debug message')
logger2.info('info message')
logger2.warning('waring message')
logger2.error('error message')
logger2.critical('critical message')
info message
waring message
error message
critical message
info message
waring message
error message
critical message
可以看出输出了两次从 INFO 级别开始的日志,导致出现这种情况出现的原因有两个:
- logger1 和 logger2 两个所创建的对象对应的是同一个 Logger 实例(只要
logging.getLogger(name) 中的 name 相同,则就是同一个实例,有且仅有一个)。在 logger2 实例中将mylogger的日志级别设置为logging.INFO,所有遵从了后来设置的日志级别。
对于上述情况,我们只需设置不同的 name 即可。
一个 logger 和 一个 logger1 对象
# 一个 logger 和 一个 logger1 对象
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger1 = logging.getLogger('mylogger')
logger1.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
logger.addHandler(ch)
logger1.addHandler(ch)
logger.debug('debug message')
logger.info('info message')
logger.warning('waring message')
logger.error('error message')
logger.critical('critical message')
logger1.debug('debug message')
logger1.info('info message')
logger1.warning('waring message')
logger1.error('error message')
logger1.critical('critical message')
info message
waring message
error message
critical message
debug message
debug message
info message
info message
waring message
waring message
error message
error message
critical message
critical message
之所以会出现两次,是因为我们通过 logger = logging.getLogger()显示的创建了root Logger,而logger1 = logging.getLogger('mylogger')创建了root Logger的孩子(root.)mylogger,logger2。而子孙既会将消息发布给给它的 Handler 处理,也会传递给它的祖先 Logger 处理。
只要将 logger 输出注释掉就行 # logger.addHandler(ch)。
Filter
import logging
logger = logging.getLogger()
logger1 = logging.getLogger('mylogger')
# 输出到屏幕(控制台)
ch = logging.StreamHandler()
# 定义一个 filter
f = logging.Filter('mylogger')
ch.addFilter(f)
logger.addHandler(ch)
logger1.addHandler(ch)
# # 设置等级
# logger.setLevel(logging.DEBUG)
# logger1.setLevel(logging.DEBUG)
logger.debug('logger debug message')
logger.info('logger info message')
logger.warning('logger warning message')
logger.error('logger error message')
logger.critical('logger critical message')
logger1.debug('1')
logger1.info('2')
logger1.warning('3')
logger1.error('4')
logger1.critical('5')
3
3
4
4
5
5
2.10 configparser 模块
可以用来生成某种固定格式的配置文件,并具有增删改查操作。
import configparser
config = configparser.ConfigParser() # 相当于一个空字典 {}
config['DEFAULT'] = {
'ServerAliveInterval': '45',
'Compression': 'yes',
'CompressionLevel': '9'
}
config['bitbucket.org'] = {}
config['bitbucket.org']['User'] = 'hg'
config['topsecret.server.com'] = {}
topsecret = config['topsecret.server.com']
topsecret['Host Port'] = '50022'
topsecret['ForwardX11'] = 'no'
config['DEFAULT']['ForwardX11'] = 'yes'
with open('config.ini', 'w') as f:
config.write(f)
# config.ini
[DEFAULT]
serveraliveinterval = 45
compression = yes
compressionlevel = 9
forwardx11 = yes
[bitbucket.org]
user = hg
[topsecret.server.com]
host port = 50022
forwardx11 = no
增删改查操作
import configparser
config = configparser.ConfigParser()
#-------------------------查---------------------------
config.read('config.ini') # 读取文件
# 打印所有块名,除默认 DEFAULT 以外
print(config.sections()) #['bitbucket.org', 'topsecret.server.com']
# 判断某行是否在里面
print('bytebong.com' in config) # False
# 查询某个块下某个值
print(config['bitbucket.org']['user']) # hg
# 查询默认块下某个值
print(config['DEFAULT']['compression']) # yes
# 遍历某个块的所有键信息 遍历时会打印 default 的信息
for key in config['bitbucket.org']:
print(key)
# user
# serveraliveinterval
# compression
# compressionlevel
# forwardx11
# 查询某个块的所有键信息,以列表形式显示
print(config.options('bitbucket.org')) # ['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11']
# 查询某个块的所有键信息,以列表二元组形式显示
print(config.items('bitbucket.org'))
# [('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')]
#---------------增-----------------------
# 增加块
config.add_section('yuan')
# 增加块下键值信息
config.set('yuan', 'k1', '1111')
#-----------删-----------------
# 删除块
config.remove_section('topsecret.server.com')
# 删除块下键值
config.remove_option('bitbucket.org', 'user')
config.write(open('new_config.ini', 'w'))
Tips:DEFAULT 用来存储必要的信息,以便每次遍历时能打印。增删改操作必须重新写入文件,可以是同文件名
2.11 hashlib 模块
在加密操作中,Python 3.x 用 hashlib 模块替代了 md5 和 sha 模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法。
MD5 算法
import hashlib
m = hashlib.md5() # 创建一个对象
m.update('hello'.encode('utf8')) # 对 hello 进行加密
print(m.hexdigest()) # 5d41402abc4b2a76b9719d911017c592
m.update('admin'.encode('utf8')) # 对 admin 进行加密
print(m.hexdigest()) # dbba06b11d94596b7169d83fed72e61b
m2 = hashlib.md5()
m2.update('helloadmin'.encode('utf8'))
print(m2.hexdigest()) # dbba06b11d94596b7169d83fed72e61b
m 对象加密字符串 hello,再加密 admin 得到的结果和 m2 对象之间加密 helloadmin 的结果一样。
以上加密算法虽然比较厉害,但还是可以通过撞库反解,所有可以在加密算法中添加自定义 key 再加密。
import hashlib
m = hashlib.md5('dfkey'.encode('utf8')) # 添加自定义 key,(随意)
m.update('hello'.encode('utf8'))
print(m.hexdigest()) # a674e0a8aa1a489ce67538a28c60abbf
sha256 算法
与 md5 算法用法一致:
m = hashlib.sha256()
m.update('hello'.encode('utf8'))
print(m.hexdigest())
2cf24dba5fb0a30e26e83b2ac5b9e29e1b161e5c1fa7425e73043362938b9824
还有一个 hmac 模块,它内部对我们创建 key 和内容再处理然后加密:
import hmac
h = hmac.new('rose'.encode('utf8'))
h.update('hello'.encode('utf8'))
print(h.hexdigest()) # a3b661e7d63a4eb65acb8223f96e2241
2.12 hamc 模块
实现标准的 Hmac 算法
方法:
# 产生一个新的哈希对象,并返回
# 随机 key,msg,哈希算法(默认 md5)
h = hmac.new(key, msg=None, digestmod=None)
# 获取哈希对象的散列值
h.digest()
# 和 digest() 一样,但返回的是一串十六进制数字
h.hexdigest()
# 用新的字符串 msg2 去更新哈希对象
h.update(msg2)
示例:
import hmac
key = b'I love python'
msg = b'python'
h = hmac.new(msg, key, digestmod='md5')
digest = h.digest()
hexdigest = h.hexdigest()
print(digest)
print(hexdigest)
msg2 = b'pycharm'
h.update(msg2)
print(h.hexdigest())
b'xdaxf3x0cxa5x175Ckax9exa9
x1dx0c{<'
daf30ca51735436b619ea90d1d0c7b3c
c976aa6fb6689c16a804eac9bf18d311
Tips: msg 和 key 必须是 bytes 类型
2.13 struct 模块
在网络通信中,大多数数据以二进制形式(binary data)传输。当传递的是字符串时,没有必要担心太多问题。但是若传递的数 int、float 等类型时,就需要将它们打包成二进制形成,再进行网络传输。而 struct 模块就提供了这样的机制。
2.13.1 pack 和 unpack
struct 提供用 format specifier 方式对数据进行打包和解包(packing and unpacking):
>>> import struct
>>> pack_data = struct.pack('hhl', 1, 2, 3) # h 两个 2 进制位,l 4个,总共 8个
>>> pack_data
b'x01x00x02x00x03x00x00x00'
>>> unpack_data = struct.unpack('hhl', pack_data)
>>> unpack_data
(1, 2, 3)
>>> struct.pack('i', 1234134) # 表示 1234134 安装 i 格式化,i 为 int,长度为 4,因此这里是将数字转换为 4 个二进制数
b'xd6xd4x12x00'
字符串:
import struct
msg = b'python' # 必须是字节型
s = struct.pack('5s', msg)
print(s)
print(struct.unpack('5s', s))
print(s.size)
b'pytho'
(b'pytho',)
16

需要注意的是解包浮点数,精度会有所变化,这是由一些比如操作系统等客观因素所决定:
>>> import struct
>>> data_pack = struct.pack('f', 12.2)
>>> struct.unpack('f', data_pack)
(12.199999809265137,)
2.13.2 字节顺序
打包后的字节顺序默认由操作系统决定,struct 模块也提供了可以自定义顺序的功能。对于一些底层通讯字节顺序很重要,不同的字节顺序会导致字节大小的不同。
我们只需要在 format 字符串前面加上特定的符号即可表示不同的字节顺序存储方式,如:采用小端存储:
data_pack = struct.pack('<hhl', 1,2,3)

2.13.3 利用 buffer,使用 pack_into 和 unpack_from 方法
使用二进制打包数据大部分场景都是对性能要求比较高的使用环境,pack 方法每次都需要重新创建一个内存空间用于返回,也就是每次都要分配相应的内存,这是一种很大的浪费。
struct 模块的 pack_into()、unpack_from() 方法,正好可以用来解决这种问题。它会对一个提取分配好的 buffer 进行字节填充,而不是每次都产生一个新对象进行存储。
pack_into(format, buffer, offerset, v1, v2...) # 格式, buffer, 偏移量(必须), 值
示例:
import struct
import ctypes
values = (1, b'python', 2.7)
s = struct.Struct('I6sf')
prebuffer = ctypes.create_string_buffer(s.size) # 创建一个 buffer 对象
data_pack = s.pack_into(prebuffer, 0, *values)
data_unpack = s.unpack_from(prebuffer, 0)
print(data_pack)
print(data_unpack)
None
(1, b'python', 2.700000047683716)
pack_into() 和 unpack_from() 都是对 buffer 对象进行操作,没有产生多余的内存浪费。而且可以将多个 struct 对象 pack 到一个 buffer 对象里,然后指定不同的 offset 进行 unpack:
import struct
import ctypes
import binascii
value1 = (1, b'python', 2.7)
value2 = 9999
s1 = struct.Struct('I6sf')
s2 = struct.Struct('I')
prebuffer = ctypes.create_string_buffer(s1.size + s2.size) # 创建一个 buffer 对象
print('pack之前', binascii.hexlify(prebuffer))
data_pack_s1 = s1.pack_into(prebuffer, 0, *value1)
data_pack_s2 = s2.pack_into(prebuffer, s1.size, value2)
data_unpack_s1 = s1.unpack_from(prebuffer, 0)
data_unpack_s2 = s2.unpack_from(prebuffer, s1.size)
print(data_unpack_s1)
print(data_unpack_s2)
print('pack之后', binascii.hexlify(prebuffer))
pack之前 b'0000000000000000000000000000000000000000'
(1, b'python', 2.700000047683716)
(9999,)
pack之后 b'01000000707974686f6e0000cdcc2c400f270000'