一. 背景
老的库source_db是安装在window server 2003上, 新库target_db为华为云的SqlServer 2008(RDS), 老库数据迁移到新库上。
二. 迁移步骤
1. 为了保证在迁移过程中源库数据不再被更新,先将库设置为只读。
方法1:可以使用如下命令来设置sql server数据库的只读特性。
USE [zssg] GO ALTER DATABASE [TESTDB] SET READ_ONLY WITH NO_WAIT GO
方法2:也可以可视化界面设置(Sqlserver managament studio 2008), 右键数据库 -> 属性,进入如下页面

2. 源库导出数据到目标库
右键数据库 -> 任务 -> 导出数据, 如下图:
直接下一步
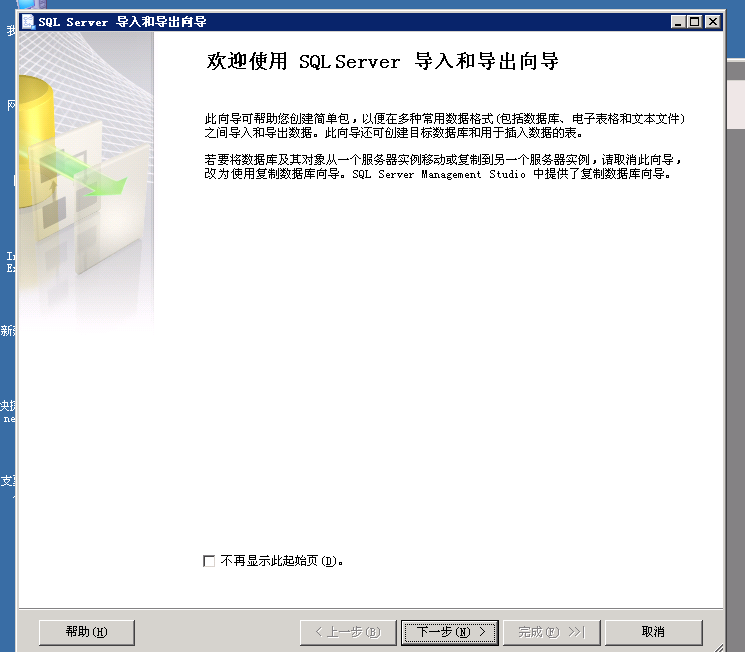
源库的服务器名称会自动带出来, 也可以自己手动编辑(IP,端口)的格式, 比如: 192.168.1.20,1433。
输入账户名密码后,点击“刷新”, 选择数据库, 然后点击“下一步”。

填写目标库的信息, 然后下一步。
全选表和视图, 然后点击“编辑映射”

立即运行,如下:
点击“完成”, 开始迁移
迁移成功,如下:
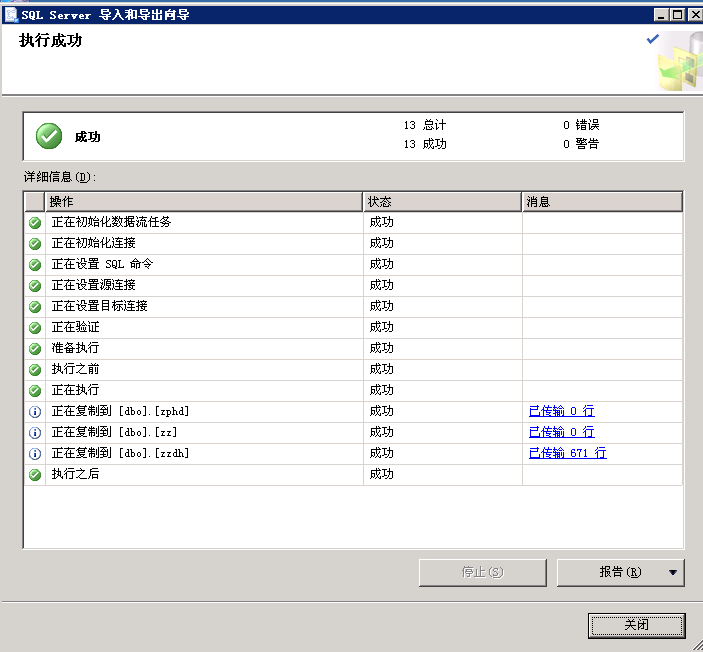
进入我们目标库,发现迁移过来的表结构, 丢失了所有的表主键、索引、自增序列。 故我们需要进行再处理。
三、迁移后表结构处理
处理逻辑:
1. 目标库所在服务器再新建一个库(命名为mid_db), 把源库的表结构(不包含数据)拷贝过来(可以通过navicat的数据传输,如下图)
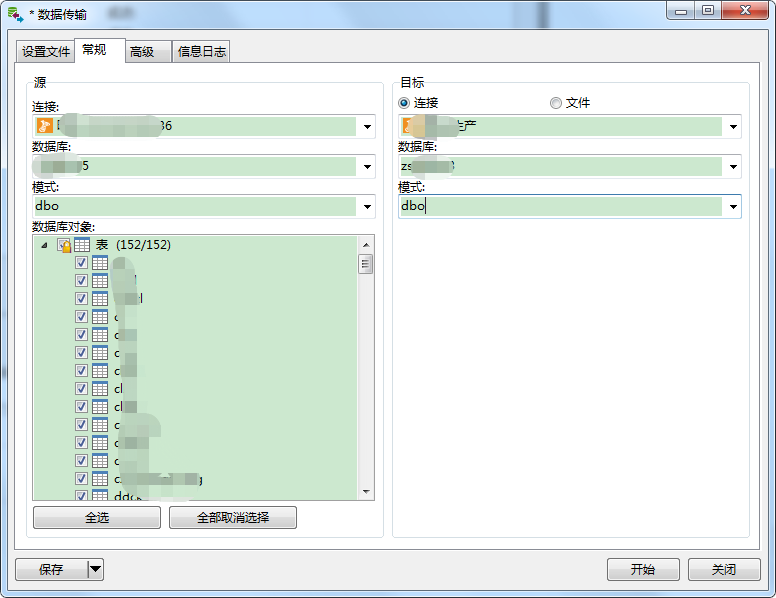
2. 点击tab中的“高级”,如下设置:(表选项只需要勾选“包含自动递增”, 索引等那些先不要加,否则做数据插入会很慢!), 然后点击右下角的“开始”, 进行表结构迁移到mid_db库
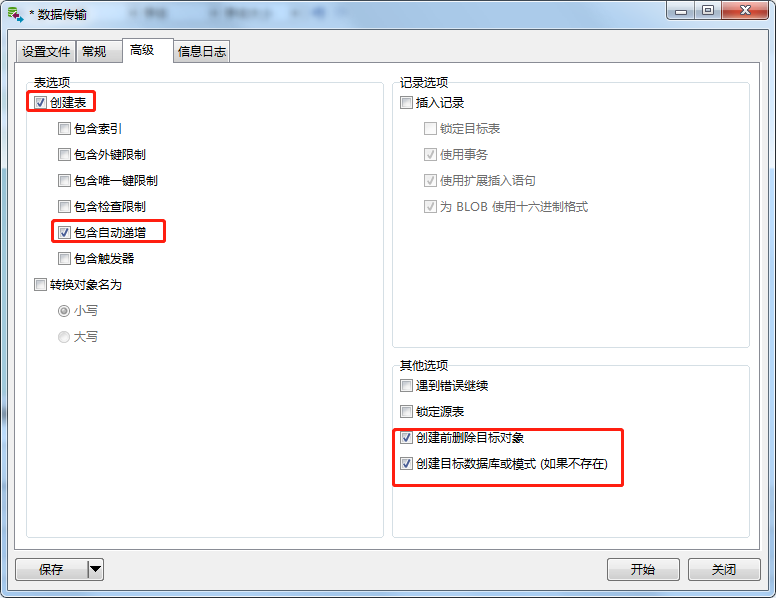
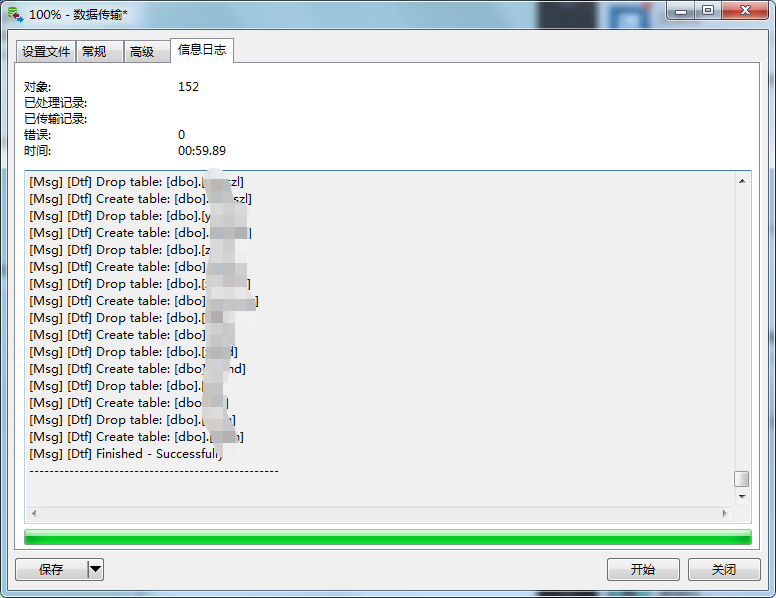
3. 拷贝表结构完毕, 如下图:
4. 对mid_db库的所有表进行重命名(如下为构建重命名的sql, 表名增加统一的前缀newfix_)
select 'exec sp_rename ''' + name + ''',''newfix_' + name + ''';' from sys.tables;
执行查询结果的sql, 重命名完毕。
5. 把mid_db的所有表结构拷贝到target_db中。(方法为同上 3.1 - 3.4 步骤)
6. 构建insert语句, 把target表的不带newfix_前缀的表数据拷贝到带前缀newfix_的表
-- 有自增字段的 select name,'set identity_insert newfix_' +name+' ON; insert into newfix_'+name+ '('+columns+ ') select '+columns+ ' from '+ name+ ' where 1=1;'+'set identity_insert newfix_' +name+' OFF;' from ( SELECT a.name, columns = stuff(( SELECT ',[' + b.name + ']' FROM sys.columns B join sys.tables c on B.object_id = c.object_id where c.name = a.name FOR xml path('')) , 1 , 1 , '') FROM sys.tables A where 1=1 and a.name not like 'newfix_%' group by a.name )aa where exists( select 1 from syscolumns where id=object_id('newfix_' + aa.name) and status=0x80 ) order by aa.name; select *from sys.tables A where 1=1 and a.name not like 'newfix_%' -- 没有自增字段的 select name,'insert into newfix_'+name+ '('+columns+ ') select '+columns+ ' from '+ name+ ' where 1=1;' from ( SELECT a.name, columns = stuff(( SELECT ',[' + b.name + ']' FROM sys.columns B join sys.tables c on B.object_id = c.object_id where c.name = a.name FOR xml path('')) , 1 , 1 , '') FROM sys.tables A where 1=1 and a.name not like 'newfix_%' group by a.name )aa where not exists( select 1 from syscolumns where id=object_id('newfix_' + aa.name) and status=0x80 ) order by aa.name;
执行上面查询结果的SQL, 成功把数据插入到有自增机制的带newfix_前缀的新表中。
7. 把target_db的所有不带newfix_的表重命名为 oldfix_, 把所有带newfix_表重命名为去掉newfix_的表
select 'exec sp_rename ''' + name + ''',''oldfix_' + name + ''';' from sys.tables where name not like 'newfix_%'; select 'exec sp_rename ''' + name + ''',''' + REPLACE (name, 'newfix_','') + ''';' from sys.tables where name like 'newfix_%';
执行如上的查询结果, 实现了表的替换。
8. 查询source_db的所有索引,用于构建target_db库的所有表的索引。
BEGIN WITH tx AS ( SELECT a.object_id, b.name AS schema_name, a.name AS table_name, c.name AS ix_name, c.is_unique AS ix_unique, c.type_desc AS ix_type_desc, d.index_column_id, d.is_included_column, e.name AS column_name, f.name AS fg_name, d.is_descending_key AS is_descending_key, c.is_primary_key, c.is_unique_constraint FROM sys.tables AS a INNER JOIN sys.schemas AS b ON a.schema_id = b.schema_id AND a.is_ms_shipped = 0 INNER JOIN sys.indexes AS c ON a.object_id = c.object_id INNER JOIN sys.index_columns AS d ON d.object_id = c.object_id AND d.index_id = c.index_id INNER JOIN sys.columns AS e ON e.object_id = d.object_id AND e.column_id = d.column_id INNER JOIN sys.data_spaces AS f ON f.data_space_id = c.data_space_id ) SELECT Drop_Index = CASE WHEN ( a.is_primary_key = 1 OR a.is_unique_constraint = 1 ) THEN 'ALTER TABLE ' + a.table_name + ' DROP CONSTRAINT ' + a.ix_name + ';' ELSE 'DROP INDEX ' + a.ix_name COLLATE SQL_Latin1_General_CP1_CI_AS + ' ON ' + a.schema_name + '.' + a.table_name + ';' END, Create_Index = CASE WHEN ( a.is_primary_key = 1 OR a.is_unique_constraint = 1 ) THEN 'ALTER TABLE ' + a.table_name + ' ADD CONSTRAINT ' + a.ix_name + CASE WHEN a.is_primary_key = 1 THEN ' PRIMARY KEY' ELSE ' UNIQUE' END + '(' + indexColumns.ix_index_column_name + ');' ELSE 'CREATE ' + CASE WHEN a.ix_unique = 1 THEN 'UNIQUE ' ELSE '' END + a.ix_type_desc + ' INDEX ' + a.ix_name COLLATE SQL_Latin1_General_CP1_CI_AS + ' ON ' + a.schema_name + '.' + a.table_name + '(' + indexColumns.ix_index_column_name + ')' + CASE WHEN IncludeIndex.ix_included_column_name IS NOT NULL THEN ' INCLUDE (' + IncludeIndex.ix_included_column_name + ')' ELSE '' END + ' ON [' + a.fg_name + '];' END, CASE WHEN a.ix_unique = 1 THEN 'UNIQUE' END AS ix_unique, a.ix_type_desc, a.ix_name, a.schema_name, a.table_name, indexColumns.ix_index_column_name, IncludeIndex.ix_included_column_name, a.fg_name, a.is_primary_key, a.is_unique_constraint FROM ( SELECT DISTINCT ix_unique, ix_type_desc, ix_name, schema_name, table_name, fg_name, is_primary_key, is_unique_constraint FROM tx ) AS a OUTER APPLY ( SELECT ix_index_column_name = STUFF( ( SELECT ',' + column_name + CASE WHEN is_descending_key = 1 THEN ' DESC' ELSE '' END FROM tx AS b WHERE schema_name = a.schema_name AND table_name = a.table_name AND ix_name = a.ix_name AND ix_type_desc = a.ix_type_desc AND fg_name = a.fg_name AND is_included_column = 0 ORDER BY index_column_id FOR XML PATH ('') ), 1, 1, '' ) ) IndexColumns OUTER APPLY ( SELECT ix_included_column_name = STUFF( ( SELECT ',' + column_name FROM tx AS b WHERE schema_name = a.schema_name AND table_name = a.table_name AND ix_name = a.ix_name AND ix_type_desc = a.ix_type_desc AND fg_name = a.fg_name AND is_included_column = 1 ORDER BY index_column_id FOR XML PATH ('') ), 1, 1, '' ) ) IncludeIndex where 1=1 ORDER BY a.schema_name, a.table_name, a.ix_name END
取Create_Index列数据执行
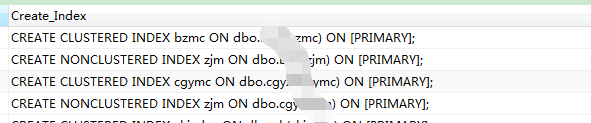
执行完毕后,则所有索引创建完毕。
9. 删除无用的中间表 oldfix_前缀的。
select 'drop table ' + name + ';' from sys.tables where name like 'oldfix_%';
10. 删除无用的中间库 mid_db
drop database mid_db;
其他的函数、视图和触发器可进行单独迁移(使用如上的SSMS或者navicat都可以), 不再赘述。
四、总结
1. 采用中间库mid_db的原因是源库source_db无法一步到位迁移成功到target_db, 因为SSMS工具做数据迁移后, 新库的表索引和自增序列等信息会丢失, mid_db和target_db的区别是多了自增属性。(target_db表不能直接修改字段为自增, 必须先drop column后 add column ,会导致数据丢失,故我们采用表数据拷贝的方式,防止数据丢失)
2. target_db的表在插入数据之前, 保证表是没有索引的, 否则会奇慢无比(频繁插入导致表索引字段记录不断重排), 插入完毕后再创建索引。
3. SSMS工具对同一个机子的不同数据库间做数据迁移速度也很慢, 故不使用SSMS进行 target_db到mid_db的数据迁移, 而是把mid_db表拷贝到target_db, 然后在target_db中进行insert的表数据拷贝。