再附上一篇翻译文档
http://blog.csdn.net/xiaoyi_zhang/article/details/52269242
再给一个百度上找的例子(侵权删):
# -*- coding: utf-8 -*-
from sklearn.cluster import KMeans
from sklearn.externals import joblib
import numpy
final = open('c:/test/final.dat' , 'r')
data = [line.strip().split(' ') for line in final]
feature = [[float(x) for x in row[3:]] for row in data]
#调用kmeans类
clf = KMeans(n_clusters=9)
s = clf.fit(feature)
print s
#9个中心
print clf.cluster_centers_
#每个样本所属的簇
print clf.labels_
#用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数
print clf.inertia_
#进行预测
print clf.predict(feature)
#保存模型
joblib.dump(clf , 'c:/km.pkl')
#载入保存的模型
clf = joblib.load('c:/km.pkl')
'''
#用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数
for i in range(5,30,1):
clf = KMeans(n_clusters=i)
s = clf.fit(feature)
print i , clf.inertia_
'''- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
初学者讲解如下:
参考http://www.cnblogs.com/meelo/p/4272677.html
sklearn对于所有的机器学习算法有一个一致的接口,一般需要以下几个步骤来进行学习:
1、初始化分类器,根据不同的算法,需要给出不同的参数,一般所有的参数都有一个默认值。 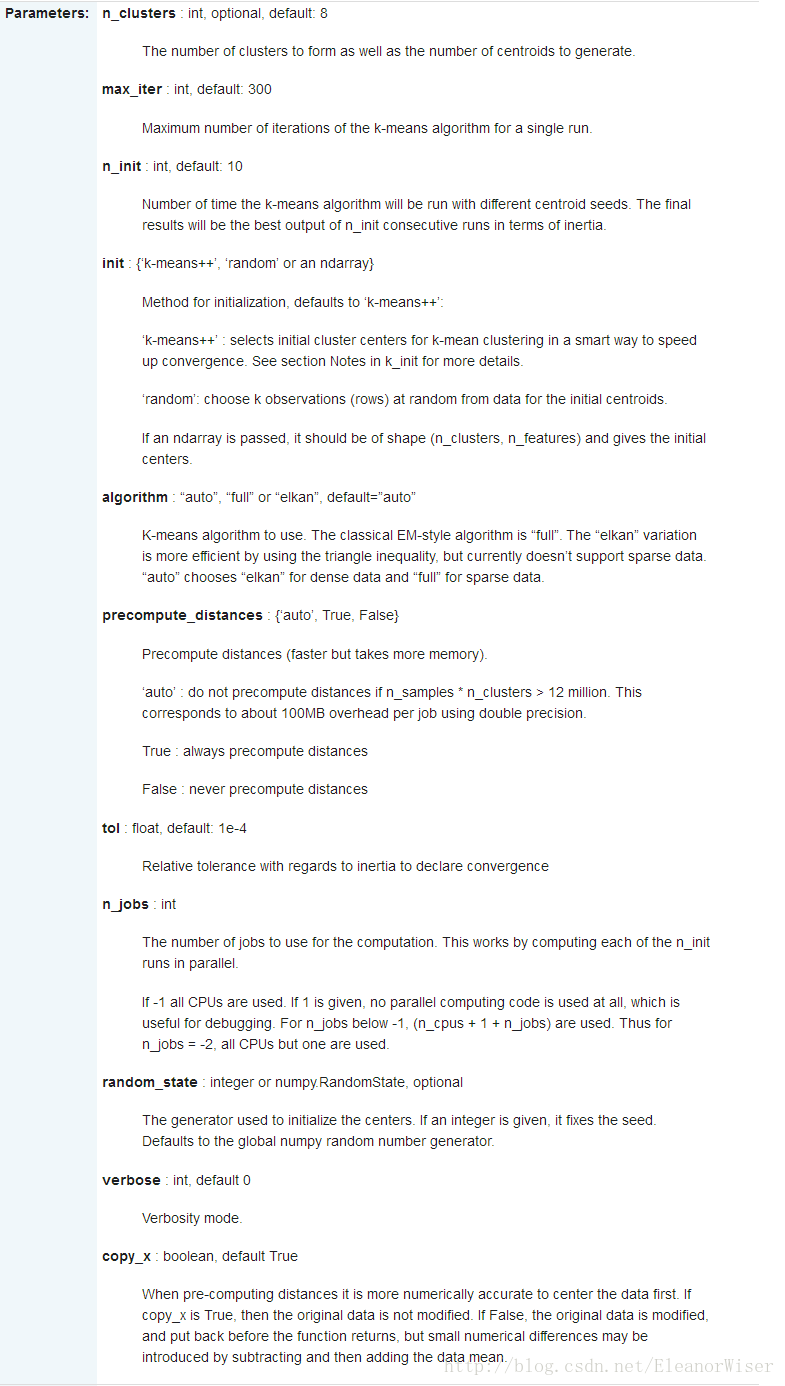
(1)对于K均值聚类,我们需要给定类别的个数n_cluster,默认值为8;
(2)max_iter为迭代的次数,这里设置最大迭代次数为300;
(3)n_init设为10意味着进行10次随机初始化,选择效果最好的一种来作为模型;
(4) init=’k-means++’ 会由程序自动寻找合适的n_clusters;
(5)tol:float形,默认值= 1e-4,与inertia结合来确定收敛条件;
(6)n_jobs:指定计算所用的进程数;
(7)verbose 参数设定打印求解过程的程度,值越大,细节打印越多;
(8)copy_x:布尔型,默认值=True。当我们precomputing distances时,将数据中心化会得到更准确的结果。如果把此参数值设为True,则原始数据不会被改变。如果是False,则会直接在原始数据
上做修改并在函数返回值时将其还原。但是在计算过程中由于有对数据均值的加减运算,所以数据返回后,原始数据和计算前可能会有细小差别。
属性: 
(1)cluster_centers_:向量,[n_clusters, n_features]
Coordinates of cluster centers (每个簇中心的坐标??);
(2)Labels_:每个点的分类;
(3)inertia_:float,每个点到其簇的质心的距离之和。
比如我的某次代码得到结果: 
2、对于非监督机器学习,输入的数据是样本的特征,clf.fit(X)就可以把数据输入到分类器里。
3、用分类器对未知数据进行分类,需要使用的是分类器的predict方法。