测试最后的一个重要的过程就是生成一份完整的测试报告,生成测试报告的主要是通过python的一个第三方模块HTMLTestRunner.py生成,但是生成的测试报告不是特别的美观,而且没有办法统计测试结果分类,同时也没有办法把测试结果的图片保存下来。通过github 查找到一个改版后的HTMLTestRunner,但是发现美观是美观些,但是有些小问题,而且也不能把我的测试结果截图显示,所以自己又在其基础上增加了图片、测试结果的饼图分布、对测试结果进行错误、失败、通过进行分类。
生成的报告
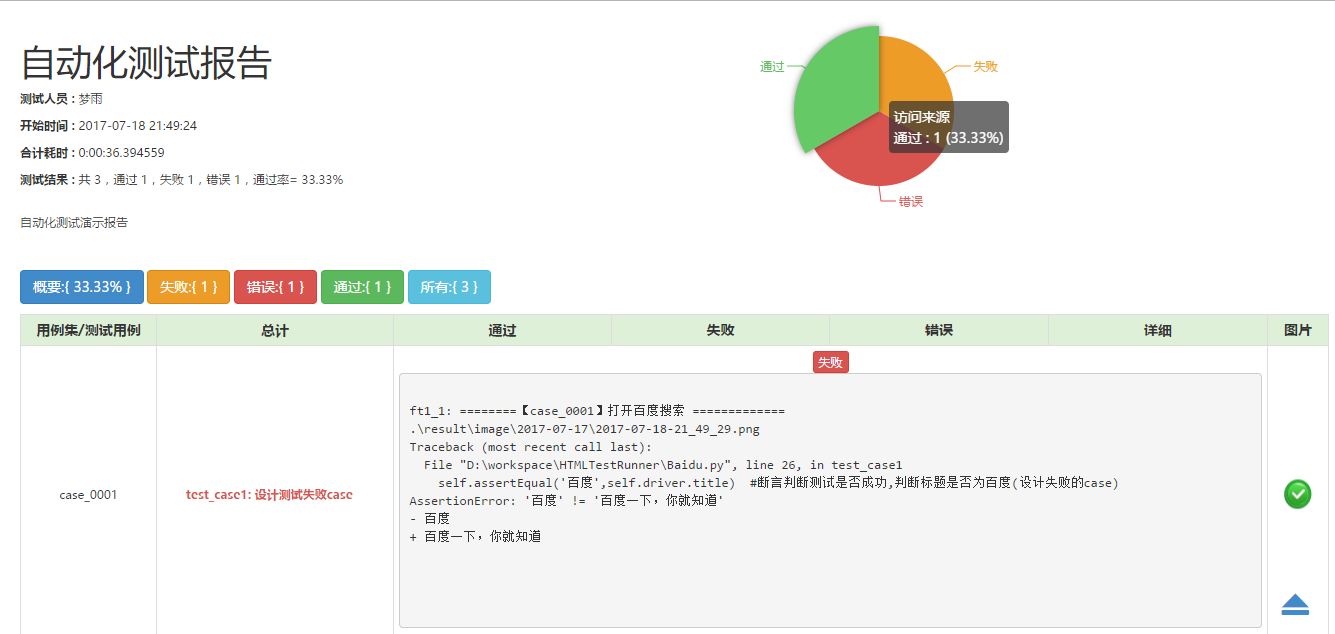
下面看下如何生成报告,接下来我们为写一个测试演示的代码生成一份报告,生成报告的时候主要利用unittest和HTMLTestReport构建。
# -*- coding: utf-8 -*- from selenium import webdriver import unittest import os,sys,time import HTMLTestReport class Baidu(unittest.TestCase): def setUp(self): self.driver = webdriver.Chrome() self.driver.implicitly_wait(30) self.driver.maximize_window() self.base_url = "https://www.baidu.com" self.driver.get(self.base_url) def test_case1(self): '''设计测试失败case''' print ("========【case_0001】打开百度搜索 =============") current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time())) # 必须打印图片路径HTMLTestRunner才能捕获并且生成路径,image**\**.png 是获取路径的条件,必须这样的目录 pic_path = '.\result\image\' + '2017-07-17\' + current_time +'.png' #设置存储图片路径,测试结果图片可以按照每天进行区分 print (pic_path) #打印图片路径 time.sleep(2) self.driver.save_screenshot(pic_path) #截图,获取测试结果 self.assertEqual('百度',self.driver.title) #断言判断测试是否成功,判断标题是否为百度(设计失败的case) def test_case2(self): '''设计测试过程中报错的case''' print ("========【case_0002】搜索selenium =============") self.driver.find_element_by_id("kw").clear() self.driver.find_element_by_id("kw").send_keys(u"selenium") self.driver.find_element_by_id('su').click() time.sleep(2) current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time())) pic_path = '.\result\image\'+ '2017-07-17\' + current_time + '.png' print (pic_path) self.driver.save_screenshot(pic_path) #截图测试结果 self.assertIn1('selenium',self.driver.title) #断言书写错误,导致case出错 def test_case3(self): '''设计测试成功的case''' print ("========【case_0003】 搜索梦雨情殇博客=============") self.driver.find_element_by_id("kw").clear() self.driver.find_element_by_id("kw").send_keys(u"梦雨情殇") self.driver.find_element_by_id('su').click() time.sleep(2) current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time())) pic_path = '.\result\image\'+ '2017-07-17\' + current_time + '.png' print (pic_path) self.driver.save_screenshot(pic_path) self.assertIn('梦雨情殇',self.driver.title) def tearDown(self): self.driver.quit() if __name__ == "__main__": '''生成测试报告''' current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time())) testunit = unittest.TestSuite() #构建测试套件 testunit.addTest(Baidu("test_case1")) testunit.addTest(Baidu("test_case2")) testunit.addTest(Baidu("test_case3")) report_path = ".\result\SoftTestReport_" + current_time + '.html' #生成测试报告的路径 fp = open(report_path, "wb") runner = HTMLTestReport.HTMLTestRunner(stream=fp, title=u"自动化测试报告",description='自动化测试演示报告',tester='梦雨') runner.run(testunit) fp.close()
过程很简单,过程需要理解整个过程,HTMLTestReport代码已经共享,请下载整体工程。