-
初识机器学习
从数据中寻找规律
- 使用模型刻画(拟合)规律:正确的总体趋势;对每一点都有偏差
- 机器学习发展的源动力:从历史数据找出规律,把这些规律用到对未来自动做出决定;用数据代替专家;经济驱动,数据变现
- 业务系统的变化
- 离线学习:之前的数据,批处理,训练
- 在线学习:实时学习,用户每产生一条数据,就训练一次
机器学习的典型应用
- 关联规则:啤酒+尿布:啤酒和纸尿布,人群一般同时购买——一般家庭大采购由丈夫承担,当买完纸尿布这类的必需品后,丈夫一般会自我奖励啤酒:调整货架,提升销量
- 用户细分精准营销:移动公司神州行,全球通,动感地带等套餐:聚类:将用户按照特定标准,分为几类
- 朴素贝叶斯:垃圾邮件
- 决策树:信用卡欺诈
- ctr预估:互联网广告:预测点击概率
- 协同过滤:推荐系统:买了A的用户,也买了B,提升整体销量
- 自然语言处理:情感分析,实体识别(文章中人名,地名等主干提出来)
- 图像识别:深度学习
- 语音识别,人脸识别,自动驾驶,机器翻译...
数据分析和机器学习的区别
- 数据特点:交易数据-行为数据
- 交易数据:LT的话费账单,银行账户;少量数据;采样分析
- 行为数据:搜索历史,购买历史;海量数据;全量分析(从大量数据中提取用户行为);NoSQL
- 解决业务问题不同:OLAP报告过去的事情-预测未来的事情
- 技术手段不同:用户驱动,交互式分析(OLAP),回答企业正在发生什么-数据驱动,自动进行知识发现(数据挖掘),基于正在发生的事情预测未来
- 参与者不同:数据分析师-数据+算法
- 目标用户:公司高层-普通个体
机器学习算法分类
- 结果集中是否有结果Y:有监督学习,无监督学习,半监督学习
- 有监督学习:模型中有X有Y,结果已经打上了标签,预先知道了结果,训练模型:分类算法,回归算法
- 无监督学习:模型中没有Y,聚类
- 半监督学习:强化学习,有一些Y值,训练模型一开始可能不好,但之后会越来越好
- 解决问题:分类和回归,聚类,标注
- 生成模型,判别模型
- 生成模型:告诉数据是否的概率,属于某一类的概率
- 判别模型:直接告诉数据是否,哪一类
- 训练模型的思想
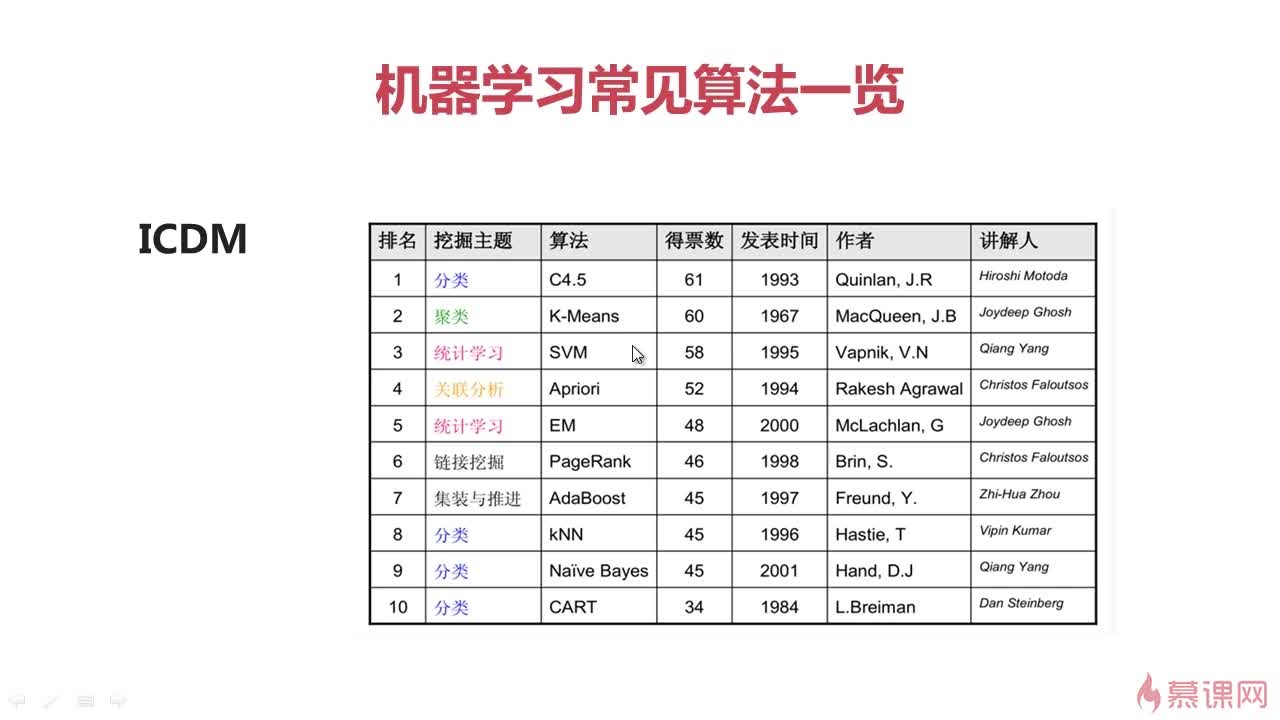
- 机器学习常用算法:10大常用算法简介

机器学习解决问题的框架:预测和聚类
- 确定目标
- 业务需求
- 数据
- 特征工程(数据清洗,提取,转换,结构化等,把数据的特征提取出来,最重要,占处理时间的70%,最影响产出效果)
- 训练模型
- 定义模型
- 定义损失函数(做预测可能出现偏差,定义偏差,评价模型优秀和一般)
- 优化算法
- 模型评估
-
相关阅读:
Fabric1.4 kafka共识的多orderer集群
Ajax跨域解决方案大全
Java常见集合的默认大小及扩容机制
Java通过http协议发送Get和Post请求
JAVA实现汉字转拼音
centos7安装jdk11
springcloudalibaba与nacos服务注册流程图
AutoGenerator自动生成代码
CentOS7安装PostgreSQL
发布jar包到服务器读取resource目录下文件
-
原文地址:https://www.cnblogs.com/mengnan/p/9307720.html
Copyright © 2020-2023
润新知