数组
一维数组
声明
格式:存储在每个元素中的值的类型 + 数组名 + 数组中的元素数(值>=1的常量表达式)
如:int a[10];
例题:定义数组a的引用。 int a[6] = {0,2,4,6,8,10};
答:int (&p) [6] = a; //p是数组a的引用,数组引用可用于函数实参传递
初始化
(1) int a[6] = {0,2,4,6,8,10}; //基本初始化
(2) int x[4] = {0}; //x的值为{0,0,0,0},若只初始化部分元素,其后的元素会被初始化为0
int y[4] = {1}; //y的值为{1,0,0,0}
(3) int *a = new int[n]; //当数组大小未知时的 动态声明一维数组;其中n为常量,为初始数组大小
delete []a; //当数组使用完毕,需要释放空间;
字符常量&字符串常量(C语言)
字符常量:用单引号括起来的单个字符,比如:‘A’;
字符串常量:用双引号括起来的字符序列,比如:"A",其表示字母A和空字符(null)两个字符.
字符数组
字符数组既可以用一组花括号括起来,逗号隔开的字符常量进行初始化,也可以用一个常量字符串(末尾有空字符)进行初始化。
方式1:char ca1[] = {'C', '+', '+'}; //末尾没有null字符,3个元素
方式2:char ca2[] = {'C', '+', '+', '\0'}; //末尾显示地添加null字符,4个元素
方式3:char ca3[] = "C++"; //末尾自动添加null字符,4个元素
附:C风格字符串包括字符串常量和末尾添加了'\0'的字符数组,即ca3和ca2都是C风格字符串;
'\0'表示null结束符,在处理C风格字符串的标准库函数时,参数必须以结束符null结束。
二维数组
声明&初始化
//按行初始化
int ia[3][4] = {
{0,1,2,3},
{4,5,6,7},
{8,9,10,11}
};
//顺序初始化
int ia[3][4] = {0,1,2,3,4,5,6,7,8,9,10,11};
//初始化每行第一个元素,其余元素为0
int ia[3][4] = {{0},{4},{8}};
//初始化第一行元素,其余元素为0
int ia[3][4] = {0,1,2,3};
//附:如果对二维数组的所有元素都赋值,则第一维(行数)可以省略
int ia[][3] = {1,2,3,4,5,6};
相当于:
int ia[2][3] = {1,2,3,4,5,6};
动态声明
//声明,a[m][n]
int **a = new int* [m];
for(int i=0;i<m;i++){
a[i] = new int [n]; }
//释放(动态声明的数组,使用后需要释放内存)
for(int i=0;i<m;i++){
delete []a[i];
delete []a;
行优先存储&列优先存储
在C/C++中,二维数组按照行优先顺序连续存储
行优先存储:在内存中,先将二维数组的第一行按顺序存储,接着是第二行、第三行......
列优先存储:在内存中,先将二维数组的第一列按顺序存储,接着是第二列、第三列......

数组指针&指针数组&数组名的指针操作
指针运算
算术运算:指针加上一个整数的结果是另一个指针;

关系运算:当指向同一个数组中的元素时,可以进行<,<=,>,>=运算
指针数组&数组指针
指针数组:一个数组里面装着指针,即指针数组是一个数组,定义为: int *a[10];

数组指针:是一个指向数组的指针,实际还是指针,只是指向整个数组,定义为: int (*p)[10];
附:[]的优先级高于*;指针数组和数组指针主要看后面两个字是什么;
举例1:
//二维数组的数组名是一个数组指针 int a[4][10]; int (*p)[10]; p = a; //a的类型是int (*)[10]
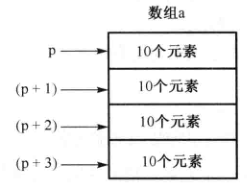
说明:p可以被替换为a; a是常量,不能进行赋值操作;int(*p)[10]中的10表示指针指向的数组有10个元素;
举例2:
int a[10]; int (*p)[10]=&a; //a的类型是int *; &a的类型int (*)[10] int *q = a;
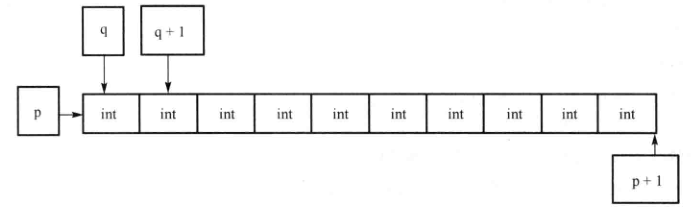
说明:p是指向有10个元素整型数组的指针,*p的大小是40个字节,p+1跳过40个字节;q是指向整型的指针,*q的大小是4个字节,q+1跳过4个字节。
数组名的指针操作
//1.在表达式中使用数组名时,该名字会自动转换成指向数组首元素(第0元素)的指针
int ia[] = {0,2,4,6,8};
int *ip = ia; //指针ip指向了数组ia的首元素
//2.如果希望指针指向数组中另一个元素,这可以使用下标操作给某个元素定位,然后用取地址操作符&获取该元素的存储地址
ip = &ia[4]; //ip指向了数组ia的末尾元素8
//3.在指向数组某个元素的指针上加上(减去)一个整型数值,可以计算出指向数组另一元素的指针值
ip = ia; //ip指向ia[0] int *ip2 = ip + 4; //ip2指向ia[4]
//4.如果要修改第4个元素为9,则有下面集中方法
ia[4] = 9; //或 *(ia+4) = 9; //或 ip[4] = 9; //或 *(ip+4) = 9;
附1:对于int a[10];
(1)&a[0] 为首元素的地址,即指向首元素的指针,&a[0]等价于a;
(2)&a为指向数组的指针,与a的类型不同(a的类型为int (*)[10]),但是指向的单元相同;
(3)数组的首地址是常量,不可以进行赋值操作;
附2:当数组作为函数实参传递时,传递给函数的是数组首元素的地址;将数组某一个元素的地址当作实参时,传递的是此元素的地址;

高维数组中的指针运算
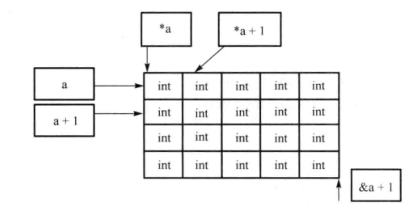
以二维数组 int a[4][5]为例:
&a:类型为int(*)[4][5],二维数组的首地址;
a+i:类型为int(*)[5],指向数组a[i]第0个元素a[i][0]的指针;
*(a+i)=a[i]:类型为int*;
*(*(a+i)+j)=a[i][j],类型为int;
数组的应用
一维数组:线性表的线性存储;哈希表
二维数组:对称矩阵的压缩;图的邻接矩阵;
字符串
字符串&子串&子序列
字符串:由零个或多个字符组成的有限串行;
子串:字符串中任意个连续的字符组成的子序列,其中空串是任意串的子串,任意串是其自身的子串;
子序列:不要求字符连续,但顺序与在主串中一致;
C风格字符串
char ca2[] = {'C', '+', '+', '\0'}; //末尾显示地添加null字符,4个元素
char ca3[] = "C++"; //末尾自动添加null字符,4个元素
C风格字符串包括字符串常量和末尾添加了'\0'的字符数组,即ca3和ca2都是C风格字符串;
'\0'表示null结束符,在处理C风格字符串的标准库函数时,参数必须以结束符null结束。
标准库提供的字符串处理函数
strlen&strcmp&strcat&strcpy&strncat&strncpy

附:strlen(s)计算不为'\0'字符数组元素个数,以'\0'为结束标志,不包含'\0';
memcpy&memset
*memcpy(*dest,*src,n):从源src所指的内存地址的起始位置拷贝n个字节到目标dest所指的内存地址的起始位置,返回指向dest的指针;
*memset(*s,int ch,n):将s中前n个字节用ch替换并返回s,作用是在一段内存中填充某个给定的值;
结构体&共用体&枚举
结构体struct
struct 结构体类型名{
类型名1 成员名1;
类型名2 成员名2;
...
类型名n 成员名n;
}
注:结构体类型只说明该类型的组成情况,没有分配内存空间,只有定义属于结构体类型的变量时,系统才会分配空间给该变量;
(1)结构体类型定义中不允许对结构体本身的递归定义,但可以使用指针指向本类型。如
struct person{ 类型名1 成员名1; ... struct person *per;//指向本类型的指针 }
(2)结构体定义中可以包含另外的结构体,结构体是可以嵌套的;
(3)结构体变量可以在定义时进行初始化赋值;
struct person{
char name[20];
char sex;
}boy1={"zhangbing",'M'};
共用体union
union 共用体名{
数据类型 成员名;
数据类型 成员名;
...
数据类型 成员名;
}变量名;
共用体与结构体的区别:
(1)共同体只存放了一个被选中的成员,而结构体的所有成员都存在。
(2) 对于共同体的不同成员赋值,将会对其他成员重写,原来的成员值就不存在了,而对于结构体的不同成员赋值是互不影响的。
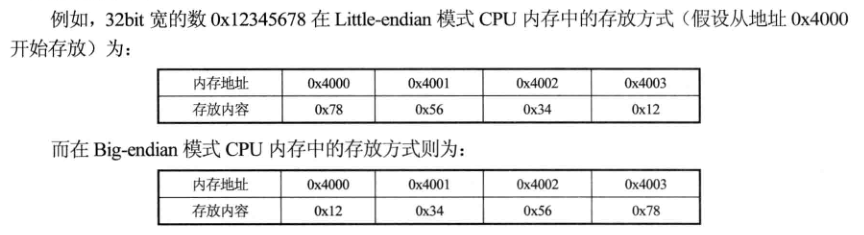
大端存储格式&小端存储格式:
(1)共用体和结构体的存放顺序是所有成员都从低地址开始存放。
(2)小端存储格式:字数据的低字节存储在低地址中。
(3)大端存储格式:字数据的高字节存储在低地址中。
枚举enum
enum 枚举类型名{枚举常量1[=整型常数],枚举常量2[=整型常数],......}[变量名列表]
如:
enum spectrum{red,orange,yellow,green,blue};
sizeof

注:sizeof计算长度将'\0'计算在内,strlen以'\0'为结束标志,不将'\0'计算在内;
struct空间计算(对齐)
1)整体空间是占用空间最大的成员类型所占字节数的整数倍;
2)数据对齐原则:内存按照结构体成员的先后顺序排列,当排到该成员变量时,前面已经摆放的空间大小是该成员类型大小的整数倍,不够则补齐,依次向后类推;


上述语句1输出为24,语句2输出为16;
union空间计算
1)取占用内存最多的成员空间作为自己的空间;
2)但也要考虑对齐问题;

上述联合体的空间大小是12,数组b占用9个字节,考虑对齐,需要是4(int占用空间)整数倍,补齐为12;
枚举空间计算
enum只是定义了一个常量集合,里面没有元素,枚举类型当作int存储,所以枚举类型的sizeof值都为4;
运算符及其优先级
1)自增、自减、负号运算符的结合方向是从右向左,k=-i++等效于k=-(i++);但是注意“先用后变”,所以等于 k=-i,i++;
2)逻辑操作符(||,&&)先计算左操作数,再计算右操作数,只有在仅靠做操作数无法确定值时,才去求解右操作数;
3)位运算符:左移低位补0,右移(int高位补符号位,unsigned int高位补0);
优先级:~>左移右移>与、或、非

4)运算时,较小的类型会被转换为较大的类型
![]()
5)移位运算>关系>与,或,异或>逻辑运算
C处理器&作用域&static&const&内存管理
C处理器
1)宏定义与宏替换:#define 标识符 字符串
2)文件包含: #include <>
3)条件编译:#if/ifdef/ifndef #elif #else #endif
全局变量
使用extern关键字引用一个已经定义过的全局变量。
static
1)隐藏:未加static前缀的全局变量和函数都具有全局可见性,其他源文件也能访问;
2)默认初始化为0;
3)保持局部变量内容的持久:静态局部变量始终存在着,生存期为整个源程序,只进行一次初始化且具有“记忆性”;
const
声明常量
内存管理与释放
1)栈(stack):由编译器自动分配释放,存放函数的参数值,局部变量的值等,速度快;
2)堆(heap):由程序员分配释放,若程序员不释放,程序结束时由操作系统回收,分配方式类似于链表,速度慢;
3)程序的局部变量存在于堆栈中,全局变量存在于全局(静态)存储区中,动态申请数据存在于堆中;
4)malloc/free 是C/C++语言标准库函数,new/delete是C++运算符;new自动计算分配空间,malloc手动计算字节数
函数
参数传递
1)形参:出现在函数定义中,整个函数体内可以使用,离开该函数则不能使用;
2)实参:出现在主调函数中,进入被调函数后,实参变量也不能使用;
3)函数调用方式:值传递,指针(地址)传递,引用传递(C++)
4)非引用类型的形参以相应实参的副本初始化,对非引用形参的任何修改仅作用于局部副本,不影响实参本身,对引用形参的任何修改会直接影响实参本身。
5)用*定义指针,用&定义引用;
内联函数
用inline修饰
1)成员函数为内联函数:在类中定义的成员函数全部默认为内联函数,加或不加inline都行;类中声明的成员函数加了inline则为内联函数,没加inline时如果在类外定义了加了inline时,也为内联函数;
2)普通函数为内联函数:普通函数声明或定义前加inline使其成为内联函数;
3)内联扩展可以消除函数调用时的时间开销;
默认参数
1)默认参数只能在函数声明中设定一次,只有无函数声明时,才可以在函数定义中设定;
2)默认参数定义的顺序为从右到左,如果一个参数设定了默认值,则其右边的参数都要有默认值;
3)默认参数调用时,遵循参数调用顺序,自左向右逐个调用;
4)默认值可以是全局变量,全局常量,函数,但不可以是局部变量;

函数重载
1)在一定作用域内,可以有一组相同函数名,不同参数列表的函数,这组函数被称为重载函数;
2)进行函数重载时,要求同名函数在参数个数上不同,或者参数类型上不同;

函数模板与泛型
1)泛型编程:以独立于任何特定类型的方式编写代码,与面向对象编程一样,都依赖于某种形式的多态性;
2)函数模板定义以关键字template开始,模板非类型形参是模板定义内部的常量值;

3)宏定义是在预处理阶段进行代码替换,内联函数是在编译阶段插入代码,宏定义有类型检查,内联函数没有类型检查;
4)类模板

函数的递归
递归的精髓在于能否将原始问题转换为属性相同但规模较小的问题,需要满足1)递归表达式,2)边界条件;

指针与引用
指针
1)指针声明: string *p1,*p2;
2)typedef 类型名 标识符; //typedef没有产生新的数据类型,只是给已存在的类型起一个“别名”;
3)C++提供了一种特殊指针类型void*,可以保存任何类型对象的地址;
4)指向指针的指针:用**表示
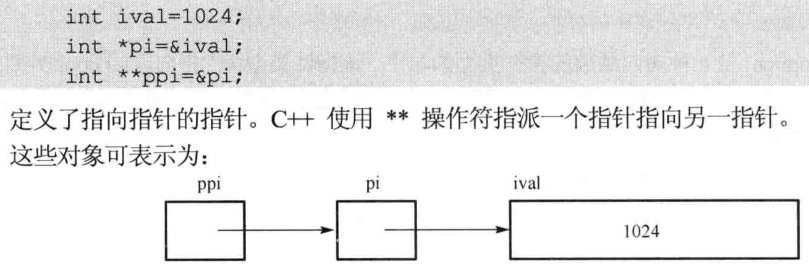
5)函数指针:指向函数而非指向对象的指针

6)可以用typedef简化函数指针的定义,cmpFcn是一种指向函数的指针类型的名字;
![]()
7)指向函数的指针可用于调用它所指向的函数

引用
1)引用是对象的另一名字,是一个特殊的变量,该变量的内容是绑定在这个引用上面的对象的地址,使用变量时,系统根据地址找到绑定的变量,再进行操作;
2)C++规定一旦定义了引用,就必须把它和另一个变量绑定起来,并且不能修改这个绑定;
3)不能定义引用类型的引用,但是可以定义任何其他类型的引用;
4)引用不能为空,创建时需初始化;
5)sizeof(引用)得到的是所指向的变量的大小,sizeof(指针)得到的是指针本身的大小;
6)当使用&运算符取一个引用地址时,其值为所引用变量的地址,而对指针使用&运算,取的是指针变量的地址;
类
1)访问标号:public、private、protected
2)类对成员的访问有:内部访问(由类中的成员函数对类的成员的访问);对象访问(在类外部,通过类的对象对类的成员的访问);
类成员简介
1)成员函数:声明成员函数是必须的,定义成员函数是可选的,每个成员函数都有一个隐形的this
2)构造函数:特殊的成员函数,构造函数和类同名,没有返回类型,一个类可以有多个构造函数,每个构造函数须有与其他构造函数不同数目或类型的形参;
3)析构函数:析构函数可以完成所需资源的回收,作为类构造函数的补充
构造函数与析构函数的调用顺序
1)单继承:派生时,构造函数和析构函数不能继承,需要重新定义,并在构造函数的初始化列表中调用基类的构造函数;
创建派生类对象时,先通过派生类的构造函数调用基类的构造函数,完成基类成员的初始化,再对派生类新增成员进行初始化;
删除派生类对象时,先执行派生类的析构函数,再执行基类的析构函数;
2)多继承:派生类的构造函数初始化列表需要调用各个基类的构造函数;
基类构造函数按照基类构造函数在类派生列表中的出现次序调用;析构函数的顺序依然按照构造函数运行的逆序进行;
3)虚继承:首先调用虚基类的构造函数,调用顺序是此虚基类在当前类派生列表中出现的顺序;
成员函数的重载、覆盖、隐藏
重载(overload)
相同的范围(同一个类中);相同的函数名字;不同的参数列表;virtual关键字可有可无;
覆盖(override)
在派生类中覆盖基类的同名函数,要求基类函数必须是虚函数,且
1)与基类的虚函数有相同的参数个数;
2)与基类的虚函数有相同的参数类型;
3)与基类的虚函数有相同的返回类型
覆盖的特征:不同的范围(位于派生类和基类);相同的函数名字;相同的参数;基类函数必须有virtual关键字;
重载和覆盖的区别:
1)覆盖是父类和子类的关系,是垂直关系;重载是同一个类中不同方法之间的关系,是水平关系;
2)覆盖要求参数列表相同;重载要求参数列表不同;
3)覆盖要求返回类型相同,重载不要求;
4)覆盖关系中,调用方法体是根据对象的类型来决定的,重载关系是根据调用时的实参表与形参表去选择方法体的;
隐藏(hide,oversee)
某些情况下,派生类中的函数屏蔽了基类中的同名函数,包括
1)两个函数参数相同,但基类函数不是虚函数;
2)两个函数参数不同,无论基类是否是虚函数,基类函数都会被屏蔽;
面向对象编程
继承
利用已有的数据类型来定义新的数据类型,基类/父类,派生类/子类
1)单继承:从一个基类派生的继承
class <派生类名>:<继承方式> <基类名>{
<派生类新定义成员>
}
<继承方式>:public(公有基类);private(私有基类);protected(保护基类);
2)多继承:从多个基类派生的继承
class <派生类名>:<继承方式1><基类名1>,<继承方式2><基类名2>,...{
<派生类新定义成员>
}
public&private&protected

1)公有继承(public):基类的公有成员和保护成员作为派生类的成员时,他们保持原有的状态,而基类的私有成员仍是私有的,不能被派生类的子类访问;
公有继承时,派生类的对象可以访问基类中的公有成员,派生类的成员函数可以访问基类中的公有成员和保护成员;
2)私有继承(private):基类的公有成员和保护成员都是作为派生类的私有成员,并且不能被这个派生类的子类访问;
私有继承时,基类的成员只能由直接派生类访问,无法再往下继承;
3)保护继承(protected):基类的所有公有成员和保护成员都作为派生类的保护成员,并且只能被它的派生类成员函数或友元访问,基类的私有成员仍是私有的;
虚函数多态
“一个接口,多种方法”,比如一个函数名(调用接口)对应着几个不同的函数原型(方法);
参考资料:
《王道程序员面试宝典》