Hadoop---目录结构介绍
1.Hadoop目录结构
1.一级目录介绍
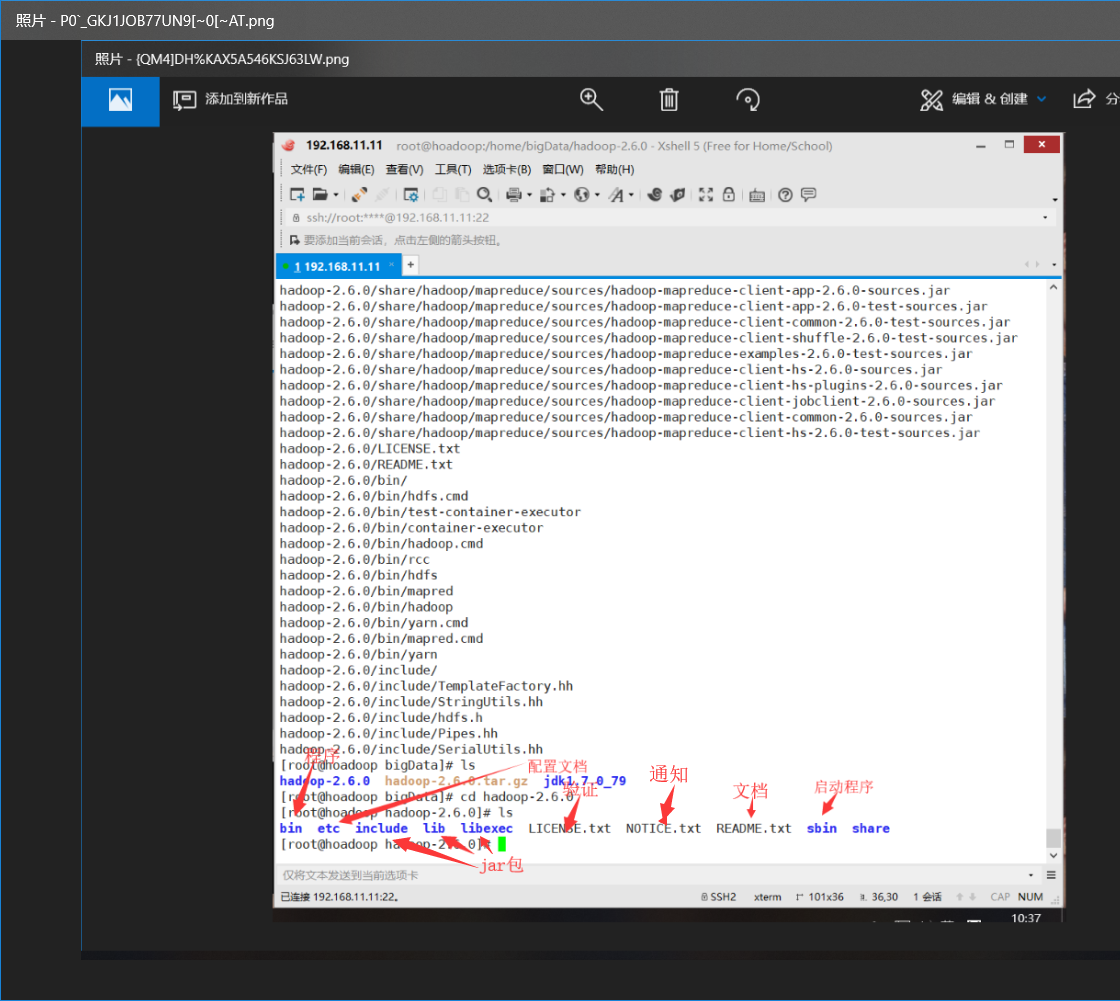
2.etc详解:
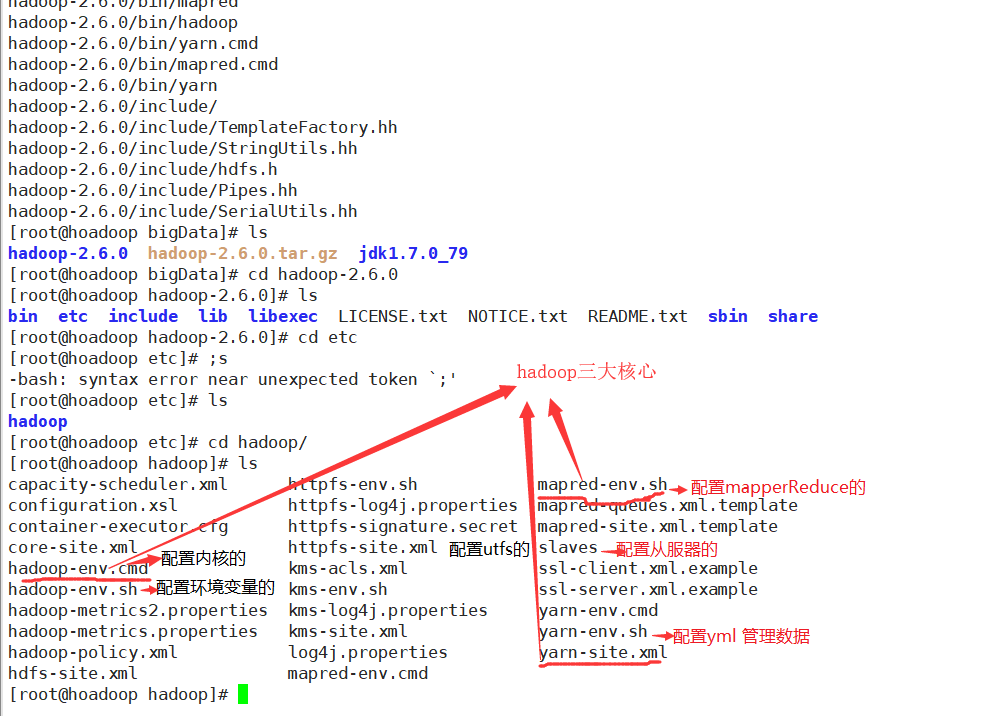
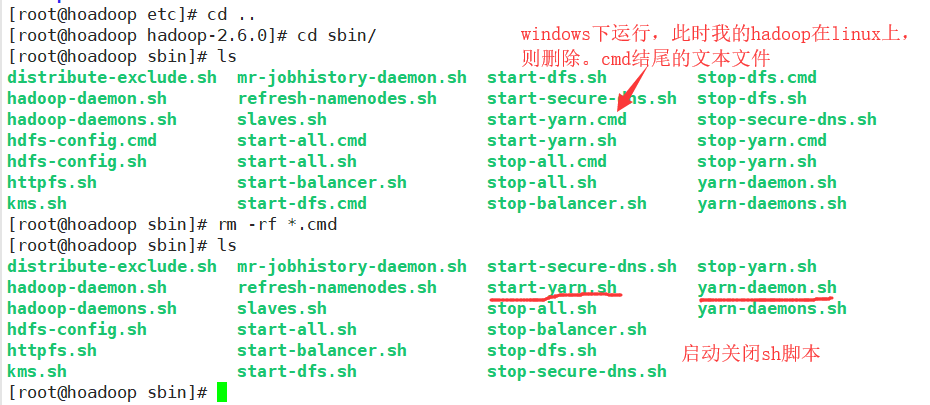
3sbin
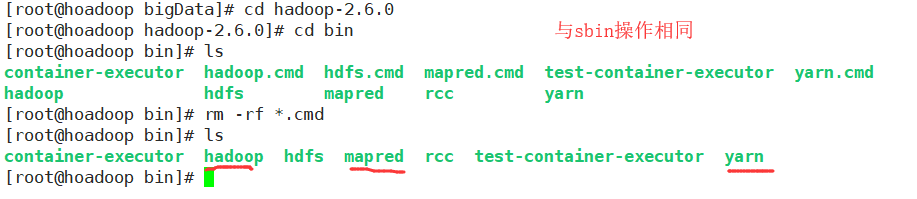
4.bin
5.share

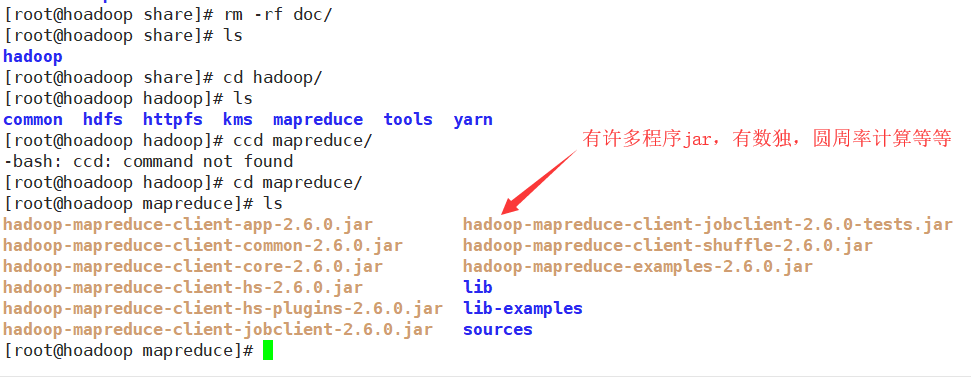
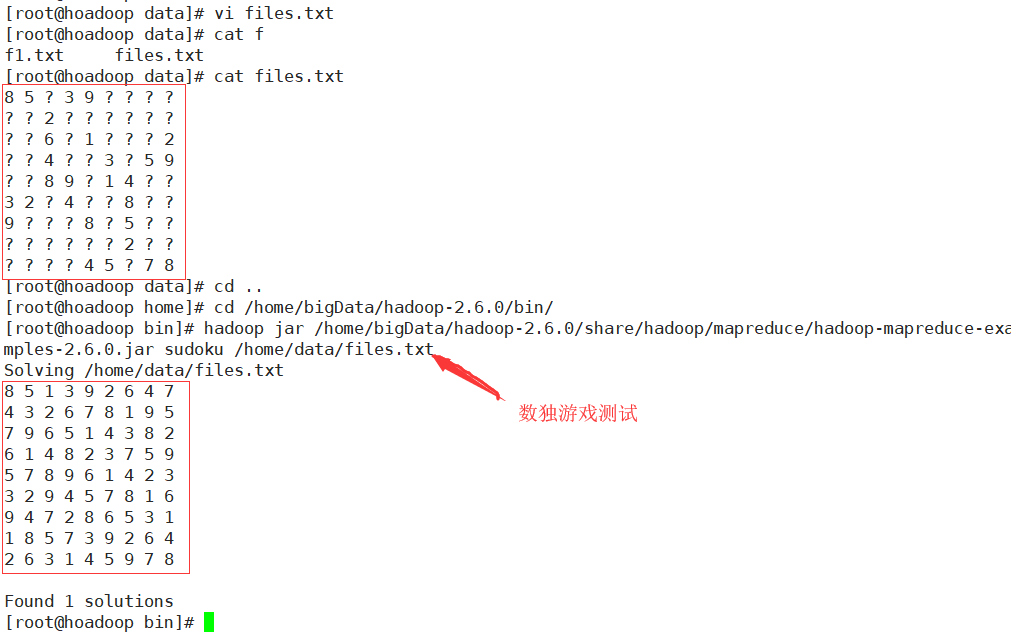
6.一个数独测试
2.hadoop的历史
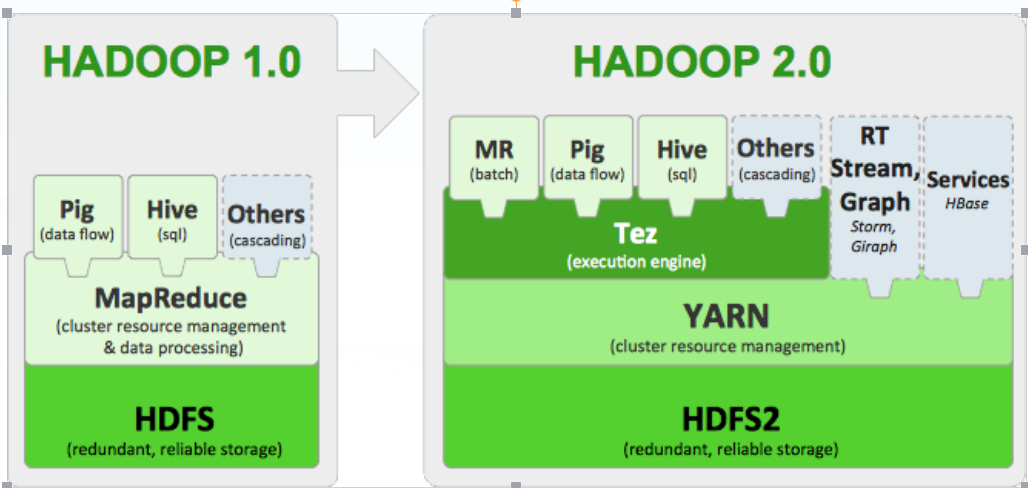
3. Hadoop的作用
1.数据分析功能
数据分析能力是大数据平台的建设重心,也是大数据分析工具的存在意义。大数据分析平台的数据分析功能受到多个方面的影响,除了软件设计技术和内建架构,搭载的数据分析模型也相当重要,直接决定了大数据分析平台所能承担的数据分析任务。
2.数据清洗功能
在大数据应用技术中,前端的数据清洗功能远比我们想象的更重要。没有好的清洗自然也不可能有后续的数据建模和数据挖掘。数据清洗功能不仅受技术发展的限制,也和数据类型以及数据量息息相关。
3.数据可视化功能
数据可视化是当下最热门的大数据应用技术,数据可视化就是将数据或者数据分析结果以图表的形式展示在各种平台上。这要求大数据分析平台有着强大的数据图表渲染功能,并且要内置丰富的可视化效果,以满足用户的不同展示需求。
4. Hadoop的优缺点
优点:
(一)高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖;
(二)高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
(三)高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
(四)高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
缺点:
(一)不适合低延迟数据访问。
(二)无法高效存储大量小文件。
(三)不支持多用户写入及任意修改文件。
5.Hadoop的核心
Hadoop的核心就是HDFS和MapReduce,而两者只是理论基础,不是具体可使用的高级应用,Hadoop旗下有很多经典子项目,比如HBase、Hive等,这些都是基于HDFS和MapReduce发展出来的。
HDFS
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
MapReduce
通俗说MapReduce是一套从海量源数据提取分析元素最后返回结果集的编程模型,将文件分布式存储到硬盘是第一步,而从海量数据中提取分析我们需要的内容就是MapReduce做的事了。MapReduce是一种用于数据处理的编程模型。该模型非常简单。同一个程序Hadoop可以运行用各种语言编写的MapReduce程序。在本章中,我们将看到用Java,Ruby,Python和C++这些不同语言编写的不同版本。最重要的是,MapReduce程序本质上是并行的,因此可以将大规模的数据分析交给任何一个拥有足够多机器的运营商。MapReduce的优势在于处理大型数据集,所以下面首先来看一个例子。
关系型数据库和MapReduce的比较
|
|
传统关系型数据库 |
MapReduce |
|
数据大小 |
GB |
PB |
|
访问 |
交互型和批处理 |
批处理 |
|
更新 |
多次读写 |
一次写入多次读取 |
|
结构 |
静态模式 |
动态模式 |
|
集成度 |
高 |
低 |
|
伸缩性 |
非线性 |
线性 |