from:https://www.zhihu.com/question/24675366?sort=created
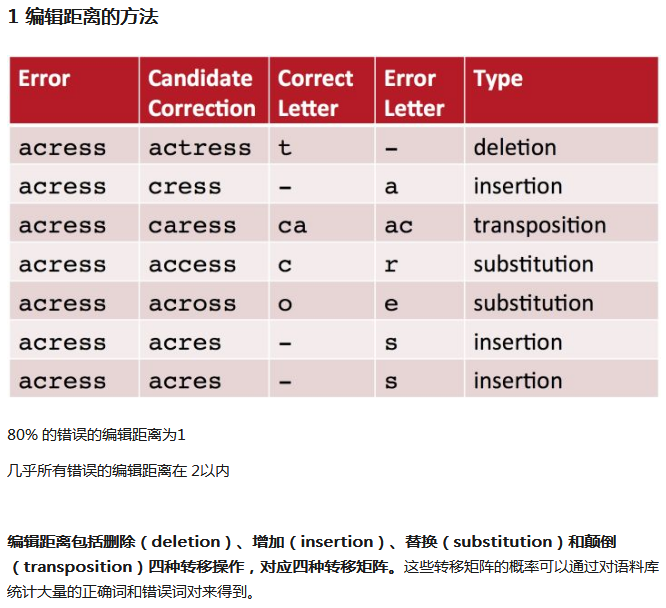
中文:主要是从拼音角度,比如输入“雷缝”(雷锋),使用编辑距离会改变要查询的语义,所以我们从同音词入手,使用噪声信道模型,先确定出一些常见的相关词,再确定概率。
英文:主要是单词拼写,可以使用编辑距离。
之前自己实习的时候,根据同事的讲解,自己的理解,总结过一篇文章,这里copy过来,刚好回答这个问题。
总结一下问题:
理论模型:Noisy Channel Model(噪声信道模型)

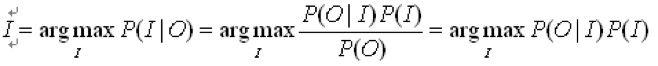
总结一下问题:
根据用户输入的query,以及其它信息,判断用户是否输入错误,如果输入错误,猜测用户原本想输入的query并提示。
再举几个栗子:
- case1:当用户在搜索引擎中输入query时,本来想输入,“中国好声音”,但是因为不小心,输入了“中国好sengyin”,这时需要搜索引擎能发现用户输入了错误的查询语句,提示原本用户想输入的query,“中国好声音”,
- case2:用户本想输入,“肯德基”,但是因为记不清这几个字的字形,只记得字的发音,错误地输入了,“肯得鸡”,这里,搜索引擎需要发现用户原本想输入的query,“肯德基”
理论模型:Noisy Channel Model(噪声信道模型)
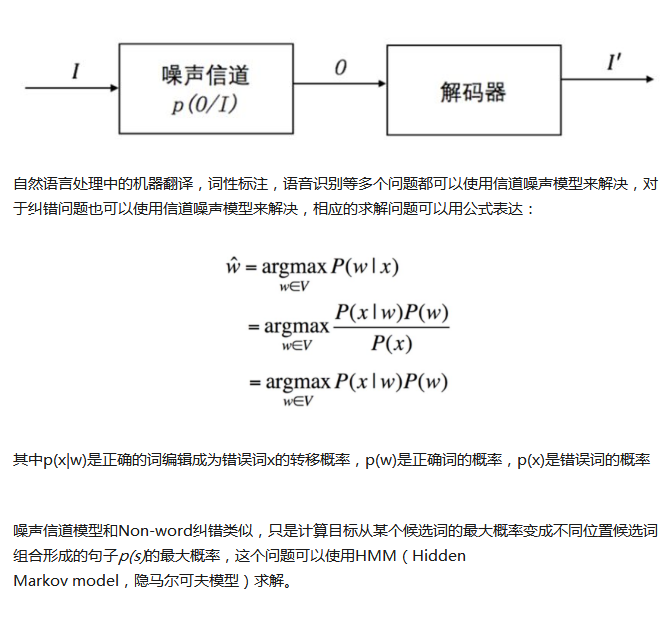
噪声信道试图通过带噪声的输出信号恢复输入信号,形式化定义为:
应用到这个问题:把用户输入的query记为input_query,用户原来想输入的query记为correct_query,那么correct_query对应于噪声信道模型的Input,input_query对应于那个模型的Output
我对所有可对的correct_query,我们要分别计算P(input_query | correct_query) * P(correct_query ),
- P(correct_query) 可以使用unigram语言模型统计得出
- P(input_query | correct_query) 可以使用input_query和correct之间的编辑距离和拼音编辑距离、可以从模糊音、形似字字典的数据给出input_query和correct_query之间的距离信息,可以从用户session中挖掘可能可以用到的数据,因为有些用户会,主动对自己输错的query进行修改直到正确为止,P(input_query | correct_query)和用户将input_query改写成correct_query的次数 / input_query出现的总次数成正比例关系。
纠错总体分这么几个方面:
- 同音纠错,
- 形似字纠错(五笔和手写输入,会带来形似字错误),
- “多字、少字、顺序错误”,
- 模糊音纠错,
举个栗子:
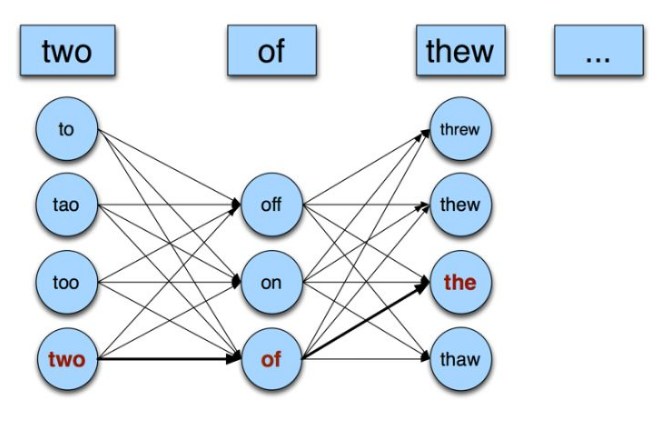
- case1: 比如用户输入,“kendeji”,那么,从同音纠错的角度,可能的correct_query可以是“肯德基”,“肯得鸡”,从形似字纠错方面看没有什么可能的correct_query,“多字、少字、顺序错误”角度,可以是“肯德基店”,我们先获取这些可能的correct_query的集合,称之为候选集,然后对于集合中的每个correct_query计算P(input_query | correct_query) * P(correct_query ),值最大为最后的提示的correct_query
- case2:比如用户输入,“汗丽轩”,从同音纠错的角度,可能的correct_query可以是“汉丽轩”,“韩丽轩”,从形似字纠错方面看correct_query可能是“汗雨轩”,模糊音纠错角度看,可能是,“汉腻轩”,我们先获取这些可能的correct_query的集合,称之为候选集,然后对于集合中的每个correct_query计算P(input_query | correct_query) * P(correct_query ),值最大为最后的提示的correct_query
ps:纠错时会采用一个策略,叫片段纠错策略,会把长度比较大的query,先切段,再对每个片段进行纠错
############################################################################