StudCodeGenerator类的继承体系如下:
主要看子类ICacheStubGenerator与StubGenerator。
1、StubGenerator
StubGenerator继承自StubCodeGenerator。
StubGenerator顾名思义就是用来生成Stub的,这里的Stub实际是一段可执行的汇编代码,具体来说就是生成StubRoutines中定义的多个public static的函数调用点,调用方可以将其作为一个经过优化后的函数直接使用。
void StubRoutines::initialize1() {
if (_code1 == NULL) {
// ResourceMark的作用类似于HandleMark,两者mark的区域不同,一个是ResourceArea,一个是HandleArea
ResourceMark rm;
// 创建一个保存不会重定位的本地代码的Blob
_code1 = BufferBlob::create("StubRoutines (1)", code_size1);
CodeBuffer buffer(_code1);
// 生成字节码解释模板
StubGenerator_generate(&buffer, false);
}
}
这里涉及到一个2个非常重要的类BufferBlob与CodeBuffer,生成的所有可执行机器码片段Stub都是经过CodeBuffer向BufferBlob中写入的,所以BufferBlob是最终存储代码片段的地方,在后面将详细介绍代码缓存及代码存储相关的类。
调用的StubGenerator_generate()函数的实现如下:
void StubGenerator_generate(CodeBuffer* code, bool all) {
StubGenerator g(code, all);
}
// 调用StubGenerator的构造函数
StubGenerator(CodeBuffer* code, bool all) : StubCodeGenerator(code) {
// generate_initial和generate_all两个方法都是给StubRoutines中的static public的函数调用地址赋值,即生成stub
if (all) {
generate_all();
} else {
generate_initial(); // 如果传入false执行的是initial相关的代码
}
}
// 调用StubCodeGenerator的构造函数
StubCodeGenerator::StubCodeGenerator(CodeBuffer* code, bool print_code) {
// 构造一个新的MacroAssembler实例
_masm = new MacroAssembler(code);
_first_stub = _last_stub = NULL;
_print_code = print_code;
}
调用的generate_initial()函数将生成StubRoutines中定义的多个public static的函数调用点。
StubCodeGenerator类的定义如下:
// The base class for all stub-generating code generators.
// Provides utility functions.
class StubCodeGenerator: public StackObj {
protected:
MacroAssembler* _masm; // 用来生成汇编代码
StubCodeDesc* _first_stub;
StubCodeDesc* _last_stub;
bool _print_code;
// ...
};
这个类中有个非常重要的属性_masm,类型为MacroAssembler*。MacroAssembler是生成机器码的地方,相关类中提供了许多机器码生成相关的方法。在创始MacroAssembler对象时传入了CodeBuffer对象,所以会将生成的机器码通过CodeBuffer写入BufferBlob中。
调用的generate_initial()函数的实现如下:
// Initialization
void generate_initial() {
// Generates all stubs and initializes the entry points
// This platform-specific settings are needed by generate_call_stub()
create_control_words();
// entry points that exist in all platforms Note: This is code
// that could be shared among different platforms - however the
// benefit seems to be smaller than the disadvantage of having a
// much more complicated generator structure. See also comment in
// stubRoutines.hpp.
StubRoutines::_forward_exception_entry = generate_forward_exception();
StubRoutines::_call_stub_entry = generate_call_stub(StubRoutines::_call_stub_return_address);
// is referenced by megamorphic call
StubRoutines::_catch_exception_entry = generate_catch_exception();
// atomic calls
StubRoutines::_atomic_xchg_entry = generate_atomic_xchg();
StubRoutines::_atomic_xchg_ptr_entry = generate_atomic_xchg_ptr();
StubRoutines::_atomic_cmpxchg_entry = generate_atomic_cmpxchg();
StubRoutines::_atomic_cmpxchg_long_entry = generate_atomic_cmpxchg_long();
StubRoutines::_atomic_add_entry = generate_atomic_add();
StubRoutines::_atomic_add_ptr_entry = generate_atomic_add_ptr();
StubRoutines::_fence_entry = generate_orderaccess_fence();
StubRoutines::_handler_for_unsafe_access_entry = generate_handler_for_unsafe_access();
// platform dependent
StubRoutines::x86::_get_previous_fp_entry = generate_get_previous_fp();
StubRoutines::x86::_get_previous_sp_entry = generate_get_previous_sp();
StubRoutines::x86::_verify_mxcsr_entry = generate_verify_mxcsr();
// Build this early so it's available for the interpreter.
StubRoutines::_throw_StackOverflowError_entry = generate_throw_exception(
"StackOverflowError throw_exception",
CAST_FROM_FN_PTR(address,
SharedRuntime::
throw_StackOverflowError));
if (UseCRC32Intrinsics) {
// set table address before stub generation which use it
StubRoutines::_crc_table_adr = (address)StubRoutines::x86::_crc_table;
StubRoutines::_updateBytesCRC32 = generate_updateBytesCRC32();
}
}
可以看到对_call_stub_entry等的初始化,_call_stub_entry初始化调用的generate_call_stub()函数在之前已经详细介绍过,这里不再介绍。还有许多的Stub,这里暂时不介绍,后面如果有涉及会详细介绍。这里需要重点理解生成的代码如何存储到之前介绍的Stub队列中的。例如generate_forward_exception()函数中有如下调用:
address start = __ pc();
就是Stub代码的入口地址。调用的是AbstraceAssembler类中的pc()方法,如下:
address pc() const { return code_section()->end(); }
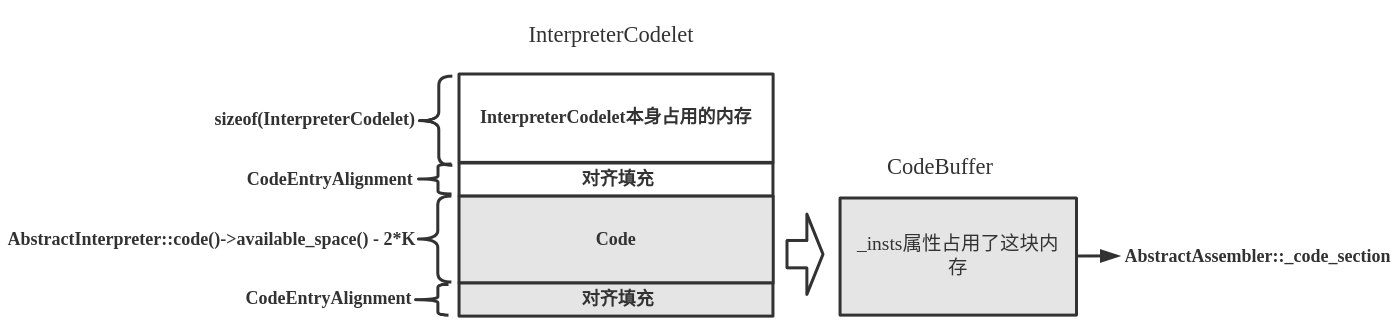
后面就会调用movptr()等各种方法将机器码写入AbstractAssembler类的_code_section中,也就是写入InterpreterCodelet对象中,如下图所示。
2、StubCodeDesc
在StubCodeMark中定义的_cdesc属性的类型为StubCodeDesc类。StubCodeDesc用来描述一段生成的Stub,StubCodeDesc保存的信息通常用于调试和打印日志。目前所有的StubCodeDesc都是链式保存的,如果查找比较慢就可能会改变。StubCodeDesc类的定义如下:
// A StubCodeDesc describes a piece of generated code (usually stubs).
// This information is mainly useful for debugging and printing.
// Currently, code descriptors are simply chained in a linked list,
// this may have to change if searching becomes too slow.
class StubCodeDesc: public CHeapObj<mtCode> {
protected:
static StubCodeDesc* _list; // the list of all descriptors
static int _count; // length of list
StubCodeDesc* _next; // the next element in the linked list
const char* _group; // the group to which the stub code belongs
const char* _name; // the name assigned to the stub code
int _index; // serial number assigned to the stub
address _begin; // points to the first byte of the stub code (included)
address _end; // points to the first byte after the stub code (excluded)
// ...
public:
StubCodeDesc(const char* group, const char* name, address begin) {
assert(name != NULL, "no name specified");
//_list相当于链表头的StubCodeDesc指针,每创建一个新的StubCodeDesc实例则插入到链表的头部
// 将原来的头部实例作为当前实例的的_next
_next = _list;
_group = group;
_name = name;
_index = ++_count; // (never zero)
_begin = begin;
_end = NULL;
_list = this;
};
// ...
};
3、StubCodeMark
在generate_initial()函数中调用的generate_forward_exception()、generate_call_stub()等函数开始时会创建一个StubCodeMark对象,在函数返回时会调用这个对象的析构函数释放相关资源。例如:
StubCodeMark mark(this, "StubRoutines", "forward exception");
StubCodeMark类的定义如下:
// Stack-allocated helper class used to assciate a stub code with a name.
// All stub code generating functions that use a StubCodeMark will be registered
// in the global StubCodeDesc list and the generated stub code can be identified
// later via an address pointing into it.
// StubCodeMark是一个工具类,用于将一个生成的stub同其名称关联起来,StubCodeMark会给当前stub
// 创建一个新的StubCodeDesc实例,并将其注册到全局的StubCodeDesc链表中,stub可以通过地址查找到
// 对应的StubCodeDesc实例。
class StubCodeMark: public StackObj {
protected:
StubCodeGenerator* _cgen;
StubCodeDesc* _cdesc;
// ...
};
构造函数与析构函数如下:
// Implementation of CodeMark
StubCodeMark::StubCodeMark(StubCodeGenerator* cgen, const char* group, const char* name) {
_cgen = cgen;
// _cgen->assembler()->pc()返回的是StubCodeDesc的start属性,即stub code的起始地址
MacroAssembler* ma = _cgen->assembler();
_cdesc = new StubCodeDesc(group, name, ma->pc());
_cgen->stub_prolog(_cdesc);
// define the stub's beginning (= entry point) to be after the prolog:
// 重置stub code的起始地址,避免stub_prolog中改变了起始地址
_cdesc->set_begin(ma->pc());
}
StubCodeMark::~StubCodeMark() {
// flush方法将生成的汇编代码写入到CodeBuffer中
_cgen->assembler()->flush();
// 设置end属性
_cdesc->set_end(_cgen->assembler()->pc());
// 校验当前StubCodeDesc处于链表头部,即在StubCodeMark构造完成到析构前没有创建一个新的StubCodeDesc实例
assert(StubCodeDesc::_list == _cdesc, "expected order on list");
_cgen->stub_epilog(_cdesc);
// 将生成的stub注册到操作系统中,相当于操作系统加载了某个函数的实现到当前进程的代码区
Forte::register_stub(_cdesc->name(), _cdesc->begin(), _cdesc->end());
}
StubCodeDesc用来描述一段生成的Stub,StubCodeDesc保存的信息通常用于调试和打印日志。
在构造函数中调用的stub_prolog()函数是个空实现。
在析构函数中调用的stub_epilog()函数的实现如下:
void StubCodeGenerator::stub_epilog(StubCodeDesc* cdesc) {
// default implementation - record the cdesc
if (_first_stub == NULL) {
_first_stub = cdesc;
}
_last_stub = cdesc;
}
在析构函数中调用的AbstractAssembler类的flush()函数的实现如下:
void AbstractAssembler::flush() {
address pos = addr_at(0);
int offst = offset();
ICache::invalidate_range(pos,offst );
}
// Code emission & accessing
address addr_at(int pos) const {
return code_section()->start() + pos;
}
int offset() const {
return code_section()->size();
}
csize_t size() const {
return (csize_t)(_end - _start);
}
调用的invalidate_range()函数的实现如下:
void AbstractICache::invalidate_range(address start, int nbytes) {
static bool firstTime = true;
if (firstTime) {
guarantee(start == CAST_FROM_FN_PTR(address, _flush_icache_stub),"first flush should be for flush stub");
firstTime = false;
return;
}
if (nbytes == 0) {
return;
}
// Align start address to an icache line boundary and transform
// nbytes to an icache line count.
const uint line_offset = mask_address_bits(start, ICache::line_size-1);
if (line_offset != 0) {
start -= line_offset;
nbytes += line_offset;
}
intptr_t temp = round_to(nbytes, ICache::line_size);
int lines = temp >> ICache::log2_line_size;
call_flush_stub(start, lines);
}
void AbstractICache::call_flush_stub(address start, int lines) {
// The business with the magic number is just a little security.
// We cannot call the flush stub when generating the flush stub
// because it isn't there yet. So, the stub also returns its third
// parameter. This is a cheap check that the stub was really executed.
static int magic = 0xbaadbabe;
int auto_magic = magic; // Make a local copy to avoid race condition
int r = (*_flush_icache_stub)(start, lines, auto_magic);
guarantee(r == auto_magic, "flush stub routine did not execute");
++magic;
}
_flush_icache_stub是函数指针,在ICacheStubGenerator类中的ICacheStubGenerator::generate_icache_flush()函数初始化。
4、ICacheStubGenerator
调用ICacheStubGenerator::generate_icache_flush()函数的调用栈如下所示。
ICacheStubGenerator::generate_icache_flush() icache_x86.cpp AbstractICache::initialize() icache.cpp icache_init() icache.cpp CodeCache::initialize() codeCache.cpp codeCache_init() codeCache.cpp init_globals() init.cpp
ICacheStubGenerator类的定义如下:
class ICacheStubGenerator : public StubCodeGenerator {
public:
ICacheStubGenerator(CodeBuffer *c) : StubCodeGenerator(c) {}
// Generate the icache flush stub.
//
// Since we cannot flush the cache when this stub is generated,
// it must be generated first, and just to be sure, we do extra
// work to allow a check that these instructions got executed.
//
// The flush stub has three parameters (see flush_icache_stub_t).
//
// addr - Start address, must be aligned at log2_line_size
// lines - Number of line_size icache lines to flush
// magic - Magic number copied to result register to make sure
// the stub executed properly
//
// A template for generate_icache_flush is
//
// #define __ _masm->
//
// void ICacheStubGenerator::generate_icache_flush(
// ICache::flush_icache_stub_t* flush_icache_stub
// ) {
// StubCodeMark mark(this, "ICache", "flush_icache_stub");
//
// address start = __ pc();
//
// // emit flush stub asm code
//
// // Must be set here so StubCodeMark destructor can call the flush stub.
// *flush_icache_stub = (ICache::flush_icache_stub_t)start;
// };
//
// #undef __
//
// The first use of flush_icache_stub must apply it to itself. The
// StubCodeMark destructor in generate_icache_flush will call Assembler::flush,
// which in turn will call invalidate_range (see asm/assembler.cpp), which
// in turn will call the flush stub *before* generate_icache_flush returns.
// The usual method of having generate_icache_flush return the address of the
// stub to its caller, which would then, e.g., store that address in
// flush_icache_stub, won't work. generate_icache_flush must itself set
// flush_icache_stub to the address of the stub it generates before
// the StubCodeMark destructor is invoked.
void generate_icache_flush(ICache::flush_icache_stub_t* flush_icache_stub);
};
generate_icache_flush()函数的实现如下:
void ICacheStubGenerator::generate_icache_flush(ICache::flush_icache_stub_t* flush_icache_stub) {
StubCodeMark mark(this, "ICache", "flush_icache_stub");
address start = __ pc();
const Register addr = c_rarg0;
const Register lines = c_rarg1;
const Register magic = c_rarg2;
Label flush_line, done;
__ testl(lines, lines);
__ jcc(Assembler::zero, done);
// Force ordering wrt cflush.
// Other fence and sync instructions won't do the job.
__ mfence();
__ bind(flush_line);
__ clflush(Address(addr, 0));
__ addptr(addr, ICache::line_size);
__ decrementl(lines);
__ jcc(Assembler::notZero, flush_line);
__ mfence();
__ bind(done);
__ movptr(rax, magic); // Handshake with caller to make sure it happened!
__ ret(0);
// Must be set here so StubCodeMark destructor can call the flush stub.
*flush_icache_stub = (ICache::flush_icache_stub_t)start;
}
生成的汇编代码如下:
0x00007fffe1000060: test %esi,%esi 0x00007fffe1000062: je 0x00007fffe1000079 // 当lines为0时,直接跳转到done 0x00007fffe1000068: mfence // -- flush_line -- 0x00007fffe100006b: clflush (%rdi) 0x00007fffe100006e: add $0x40,%rdi // 加一个line_size,值为64 0x00007fffe1000072: dec %esi 0x00007fffe1000074: jne 0x00007fffe100006b // 如果lines不为0,则跳转到flush_line 0x00007fffe1000076: mfence // -- done --
// Handshake with caller to make sure it happened! 0x00007fffe1000079: mov %rdx,%rax 0x00007fffe100007c: retq
其中的clflush指令说明如下:
clflush--- Flushes and invalidates a memory operand and its associated cache line from all levels of the processor's cache hierarchy
在处理器缓存层次结构(数据与指令)的所有级别中,使包含源操作数指定的线性地址的缓存线失效。失效会在整个缓存一致性域中传播。如果缓存层次结构中任何级别的缓存线与内存不一致(污损),则在使之失效之前将它写入内存。源操作数是字节内存位置。
mfence可以序列化加载与存储操作。
对 MFENCE 指令之前发出的所有加载与存储指令执行序列化操作。此序列化操作确保:在全局范围内看到 MFENCE 指令后面(按程序顺序)的任何加载与存储指令之前,可以在全局范围内看到 MFENCE 指令前面的每一条加载与存储指令。MFENCE 指令的顺序根据所有的加载与存储指令、其它 MFENCE 指令、任何 SFENCE 与 LFENCE 指令以及任何序列化指令(如 CPUID 指令)确定。