Java对象通过Oop来表示。Oop指的是 Ordinary Object Pointer(普通对象指针)。在 Java 创建对象实例的时候创建,用于表示对象的实例信息。也就是说,在 Java 应用程序运行中每创建一个 Java 对象,在 JVM 内部都会创建一个 Oop 对象来表示 Java 对象。
Oop涉及到的相关类的继承关系如下图所示。
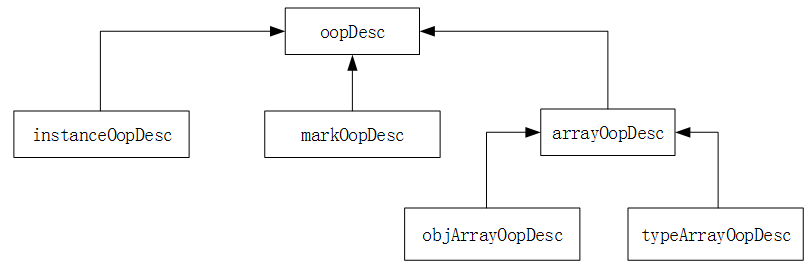
1、oopDesc类
oopDesc的一个别名为oop,所以HotSpot中一般会使用oop来表示oopDesc类型。
oopDesc 是 所 有 的 类 名 为 xxxOopDesc 格 式 的 类 的 基 类 , 这 些 类 的 实 例 表 示 Java 对 象,所以xxxOopDesc 格式的类中会声明一些保存 Java 对象的字段,并且也可以直接被 C++获取。类及重要属性的定义如下:
位置:/openjdk/hotspot/src/share/vm/oops/oop.hpp
class oopDesc {
...
private:
volatile markOop _mark;
union _metadata {
Klass* _klass;
narrowKlass _compressed_klass;
} _metadata;
...
}
Java对象内存布局主要分为header(头部)和fields(实例字段)。header由_mark和_metadata组成。_mark字段保存了Java对象的一些信息,如GC年龄,锁状态等;_metadata使用联合体(union)来声明 ,这样是为了在 64 位机器上能对指针进行压缩。因为从32位平台到64位时,主要就是指针由4字节变为了8字节,所以通常64位HotSpot消耗的内存会比32位的大,造成堆内存损失,不过从JDK 1.6 update14开始,64位的JVM正式支持了-XX:+UseCompressedOops(默认开启)。这个可以压缩指针,起到节约内存占用的作用。
在64位系统下,存放_metadata的空间大小是8字节,_mark是8字节,对象头为16字节。64位开启指针压缩的情况下,存放_metadata的空间大小是4字节,_mark是8字节,对象头为12字节。
启用-XX:+UseCompressedOops命令后,主要会压缩如下的一些对象:
- 每个Class的属性指针(静态成员变量);
- 每个对象的属性指针;
- 普通对象数组的每个元素指针。
当然,压缩也不是所有的指针都会压缩,对一些特殊类型的指针,HotSpot是不会优化的,例如指向Metaspace的Class对象指针、本地变量、堆栈元素、入参、返回值和NULL指针不会被压缩。
64位地址分为堆的基地址+偏移量,当堆内存小于32GB时候,在压缩过程中,把偏移量除以8后的结果保存到32位地址。当解压时再把32位地址放大8倍,所以启用-XX:+UseCompressedOops命令的条件是堆内存要在4GB*8=32GB以内。具体实现方式是在机器码中植入压缩与解压指令,可能会给JVM增加额外的开销。
总结一下:
- 如果GC堆大小在4G以下,直接砍掉高32位,避免了编码解码过程;
- 如果GC堆大小在4G以上32G以下,则启用-XX:+UseCompressedOops命令;
- 如果GC堆大小大于32G,压指失效,使用原来的64位。
联合体中定义的_klass或_compressed_klass指针指向的是Klass实例,这个Klass实例保存了Java对象的实际类型,也就是Java对象所对应的Java类。
调用header_size()函数获取header占用的内存空间的大小,具体实现如下:
位置:/openjdk/hotspot/src/share/vm/oops/oop.inline.hpp
static int header_size() {
return sizeof(oopDesc)/HeapWordSize;
}
计算占用的字的大小,对于64位机器来说,一个字的大小为8字节,所以HeapWordSize的值为8。
Java对象的header信息可以存储到oopDesc类中定义的_mark和_metadata属性上,而Java对象的fields没有在oopDesc类中定义相应的属性来存储,所以只能申请一定大小的空间,然后按顺序进行存储。对象字段是存放在紧跟着oopDesc实例本身占用的内存空间之后的,在获取时只能通过偏移来取值。
opDesc 类的field_base()函数可用于获取字段的地址,实现如下:
位置:/openjdk/hotspot/src/share/vm/oops/oop.inline.hpp
inline void* field_base(int offset) const {
return (void*)&( (char*)this )[offset];
}
offset是偏移量,计算相对于当前实例this的内存首地址的偏移量。
2、markOopDesc类
上面介绍oopDesc类时,可以看到定义了一个属性_mark,而类型为markOop,其实这是markOopDesc的别名。markOopDesc类的实例可以表示Java对象头信息的“Mark Word",包含的信息有哈希码、GC分代年龄、偏向锁标记、线程持有的锁、偏向线程ID、偏向时间戳等。
markOopDesc类的实例并不能表示一个具体的Java对象,而是通过一个字的各个位来表示Java对象的头信息。对于32位系统来说,一个字为32位(4字节),而对于64位系统来说,一个字有64位(8字节)。由于目前64位是主流,所以笔者不在对32位的结构进行说明。
下图表示了在Java对象不同状态下的Mark Word各个位区间的含义。
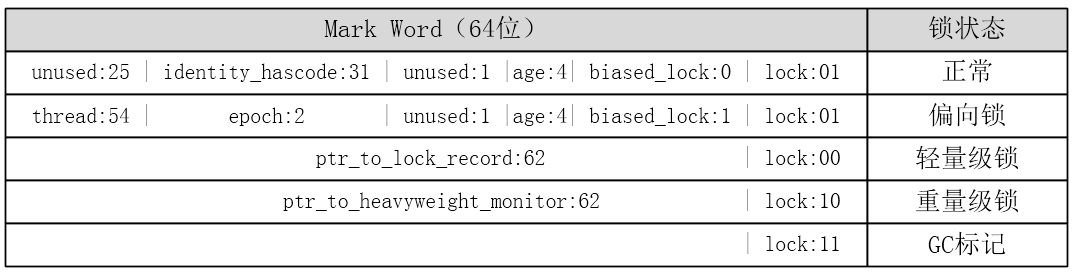
上面每一行代表对象处于某种状态时的样子。其中各部分的含义如下:
- lock:2位的锁状态标记位,由于希望用尽可能少的二进制位表示尽可能多的信息,所以设置了lock标记。该标记的值不同,整个Mark Word表示的含义不同。biased_lock和lock一起表示了锁的状态。
- biased_lock:对象是否启用偏向锁标记,只占1个二进制位。为1时表示对象启用偏向锁,为0时表示对象没有偏向锁。lock和biased_lock共同表示对象的锁状态。
- age:占用4个二进制位,存储的是Java对象的年龄。在GC中,如果对象在Survivor区复制一次,年龄增加1。当对象达到设定的阈值时,将会晋升到老年代。默认情况下,并行GC的年龄阈值为15,并发GC的年龄阈值为6。由于age只有4位,所以最大值为15,这就是-XX:MaxTenuringThreshold选项最大值为15的原因。
- identity_hashcode:占用31个二进制位,用来存储对象的HashCode,采用延迟加载技术。调用方法System.identityHashCode()计算,并会将结果写到该对象头中。如果当前对象的锁状态为偏向锁,由于偏向锁没有存储HashCode的地方,所以调用identityHashCode()方法会造成锁升级,而轻量级锁和重量级锁所指向的lock record或monitor都有存储HashCode的空间。hashCode 只针对 identity hash code。用户自定义的 hashCode() 方法所返回的值不存在 Mark Word 中。Identity hash code 是未被覆写的 java.lang.Object.hashCode() 或者 java.lang.System.identityHashCode(Object) 所返回的值。
- thread:持有偏向锁的线程ID。
- epoch:偏向锁的时间戳。
- ptr_to_lock_record:轻量级锁状态下,指向栈中锁记录的指针。
- ptr_to_heavyweight_monitor:重量级锁状态下,指向对象监视器Monitor的指针。
关于锁与锁升级相关的内容,后续文章会详细介绍,这里只需要大概认识一下相关的字段即可。
相关文章的链接如下:
1、在Ubuntu 16.04上编译OpenJDK8的源代码
关注公众号,有HotSpot源码剖析系列文章!

参考文章:
(2)JVM Anatomy Quark #23: Compressed References