上一篇详细介绍了HDFS集群,还有操作HDFS集群的一些命令,常用的命令:

hdfs dfs -ls xxx
hdfs dfs -mkdir -p /xxx/xxx
hdfs dfs -cat xxx
hdfs dfs -put local cluster
hdfs dfs -get cluster local
hdfs dfs -cp /xxx/xxx /xxx/xxx
hdfs dfs -chmod -R 777 /xxx
hdfs dfs -chown -R zyh:zyh /xxx
注意:这里要说明一下-cp,我们可以从本地文件拷贝到集群,集群拷贝到本地,集群拷贝到集群。
一、Hadoop客户端配置
其实在前面配置的每一个集群节点都可以做一个Hadoop客户端。但是我们一般都不会拿用来做集群的服务器来做客户端,需要单独的配置一个客户端。
1)安装JDK
2)安装Hadoop
3)客户端配置子core-site.xml

4)客户端配置之mapred-site.xml

5)客户端配置之yarn-site.xml

以上就搭建了一个Hadoop的客户端
二、Java访问HDFS集群
2.1、HDFS的Java访问接口
1)org.apache.hadoop.fs.FileSystem
是一个通用的文件系统API,提供了不同文件系统的统一访问方式。
2)org.apache.hadoop.fs.Path
是Hadoop文件系统中统一的文件或目录描述,类似于java.io.File对本地文件系统的文件或目录描述。
3)org.apache.hadoop.conf.Configuration
读取、解析配置文件(如core-site.xml/hdfs-default.xml/hdfs-site.xml等),或添加配置的工具类
4)org.apache.hadoop.fs.FSDataOutputStream
对Hadoop中数据输出流的统一封装
5)org.apache.hadoop.fs.FSDataInputStream
对Hadoop中数据输入流的统一封装
2.2、Java访问HDFS主要编程步骤
1)构建Configuration对象,读取并解析相关配置文件
Configuration conf=new Configuration();
2)设置相关属性
conf.set("fs.defaultFS","hdfs://1IP:9000");
3)获取特定文件系统实例fs(以HDFS文件系统实例)
FileSystem fs=FileSystem.get(new URI("hdfs://IP:9000"),conf,“hdfs");
4)通过文件系统实例fs进行文件操作(以删除文件实例)
fs.delete(new Path("/user/liuhl/someWords.txt"));
2.3、使用FileSystem API读取数据文件
有两个静态工厂方法来获取FileSystem实例文件系统。

常用的就第二个和第四个
三、实战Java访问HDFS集群
3.1、环境介绍
1)使用的是IDEA+Maven来进行测试
2)Maven的pom.xml文件
 pom.xml
pom.xml3)HDFS集群一个NameNode和两个DataNode
3.2、查询HDFS集群文件系统的一个文件将它文件内容打印出来
package com.jslg.zyh.hadoop.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
public class CatDemo_0010 {
public static void main(String[] args) throws IOException {
// 创建Configuration对象
Configuration conf=new Configuration();
// 创建FileSystem对象
FileSystem fs=
FileSystem.get(URI.create(args[0]),conf);
// 需求:查看/user/kevin/passwd的内容
// args[0] hdfs://1.0.0.5:9000/user/zyh/passwd
// args[0] file:///etc/passwd
FSDataInputStream is=
fs.open(new Path(args[0]));
byte[] buff=new byte[1024];
int length=0;
while((length=is.read(buff))!=-1){
System.out.println(
new String(buff,0,length));
}
System.out.println(
fs.getClass().getName());
}
}
1)需要在HDFS文件系统中有passwd.txt文件,如果没有需要自己创建
hdfs dfs -mkdir -p /user/zyh
hdfs dfs -put /etc/passwd /user/zyh/passwd.txt
2)将Maven打好的jar包发送到服务器中,这里我们就在NameNode主机中执行,每一个节点都是一个客户端。
注意:
 这里要发送第二个包,因为它把相关类也打进jar中
这里要发送第二个包,因为它把相关类也打进jar中
 查看服务器已经收到jar包
查看服务器已经收到jar包
3)执行jar包查看结果
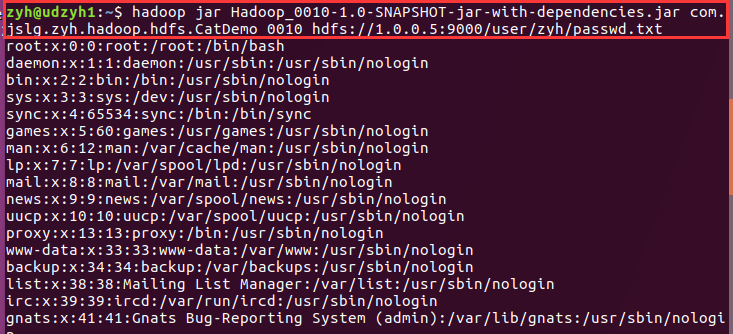
我们可以看到查询出来了passwd.txt中的内容
注意:在最后我们还查看了一下FileSystem类,因为我们知道FileSystem是抽象类,它是根据后面的URI来确定到底调用的是哪一个子类的。

3.3、我们在IEDA中执行来获取文件系统的内容并打印在控制台和相应的本地文件中
1)主要代码
public static void main(String[] args) throws IOException {
//创建configuration对象
Configuration conf = new Configuration();
//创建FileSystem对象
//需求:查看hdfs集群服务器/user/zyh/passwd.txt的内容
FileSystem fs = FileSystem.get(URI.create("hdfs://1.0.0.5:9000/user/zyh/passwd.txt"), conf);
// args[0] hdfs://1.0.0.3:9000/user/zyh/passwd.txt
// args[0] file:///etc/passwd.txt
FSDataInputStream is = fs.open(new Path("hdfs://1.0.0.5:9000/user/zyh/passwd.txt"));
OutputStream os=new FileOutputStream(new File("D:/a.txt"));
byte[] buff= new byte[1024];
int length = 0;
while ((length=is.read(buff))!=-1){
System.out.println(new String(buff,0,length));
os.write(buff,0,length);
os.flush();
}
System.out.println(fs.getClass().getName());
//这个是根据你传的变量来决定这个对象的实现类是哪个
}
2)Maven重新编译,并执行
3)结果
在控制台中:
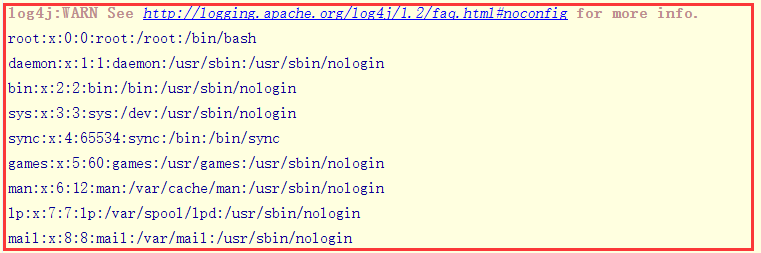
在本地文件中:

3.4、获取HDFS集群文件系统中的文件到本地文件系统
1)主要代码
public class GetDemo_0010 {
public static void main(String[] args) throws IOException {
Configuration conf=
new Configuration();
// 获取从集群上读取文件的文件系统对象
// 和输入流对象
FileSystem inFs=
FileSystem.get(
URI.create(args[0]),conf);
FSDataInputStream is=
inFs.open(new Path(args[0]));
// 获取本地文件系统对象
//当然这个你也可以用FileOutputStream
LocalFileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path(args[1]));
byte[] buff=new byte[1024];
int length=0;
while((length=is.read(buff))!=-1){
os.write(buff,0,length);
os.flush();
}
System.out.println(
inFs.getClass().getName());
System.out.println(
is.getClass().getName());
System.out.println(
outFs.getClass().getName());
System.out.println(
os.getClass().getName());
os.close();
is.close();
}
}
2)结果

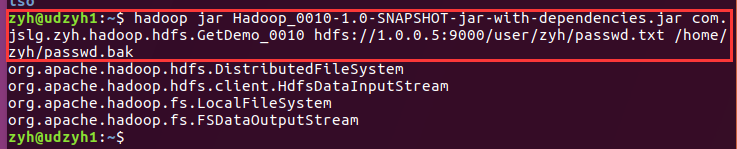
我们可以看到对于HDFS集群中获取的FileSystem对象是分布式文件系统,而输入流是HdfsDataInputStream主要用来做数据的传输。
对于本地来说获取到的FileSystem对象时本地文件系统,而输出流就是FSDataOutputStream。
将HDFS中的文件拿到windows中:
//创建configuration对象
Configuration conf = new Configuration();
// 获取从集群上读取文件的文件系统对象
// 和输入流对象
FileSystem inFs=
FileSystem.get(
URI.create("file://1.0.0.5:9000/user/kevin/passwd"),conf);
FSDataInputStream is=
inFs.open(new Path("hdfs://1.0.0.5:9000/user/kevin/passwd"));
// 获取本地文件系统对象
LocalFileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path("C:\passwd"));
byte[] buff=new byte[1024];
int length=0;
while((length=is.read(buff))!=-1){
os.write(buff,0,length);
os.flush();
}
System.out.println(
inFs.getClass().getName());
System.out.println(
is.getClass().getName());
System.out.println(
outFs.getClass().getName());
System.out.println(
os.getClass().getName());
os.close();
is.close();
3.5、通过设置命令行参数变量来编程
这里需要借助Hadoop中的一个类Configured、一个接口Tool、ToolRunner(主要用来运行Tool的子类也就是run方法)
分析:
1)我们查看API可以看到ToolRunner中有一个run方法:

里面需要一个Tool的实现类和使用args用来传递参数的String类型的数据
2)分析Configured
这是Configurable接口中有一个getConf()方法
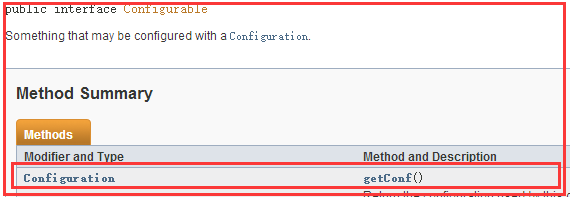
而在Configured类中实现了Configurable接口

所以Configured类中实现了Configurable接口的getConf()方法,使用它来获得一个Configuration对象
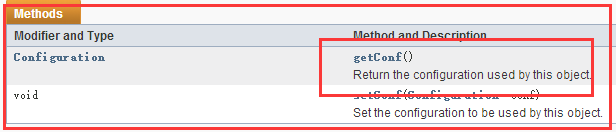
3)细说Configuration对象
可以获取Hadoop的所有配置文件中的数据
还可以通过使用命令行中使用-D(-D是一个标识)使用的变量以及值
1)主要代码
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class GetDemo_0011
extends Configured
implements Tool{
@Override
public int run(String[] strings) throws Exception{
//我们所有的代码都写在这个run方法中
Configuration conf=
getConf();
String input=conf.get("input");
String output=conf.get("output");
FileSystem inFs=
FileSystem.get(
URI.create(input),conf);
FSDataInputStream is=
inFs.open(new Path(input));
FileSystem outFs=
FileSystem.getLocal(conf);
FSDataOutputStream os=
outFs.create(new Path(output));
IOUtils.copyBytes(is,os,conf,true);
return 0;
}
public static void main(String[] args) throws Exception{
//ToolRunner中的run方法中需要一个Tool的实现类,和
System.exit(
ToolRunner.run(
new GetDemo_0011(),args));
}
}
分析:
1)介绍IOUtils
它是Hadoop的一个IO流的工具类,查看API中可知!
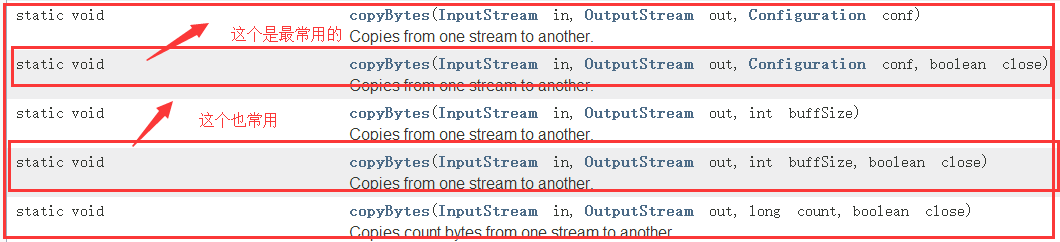
2)打包jar发送给服务器执行

3)查看结果
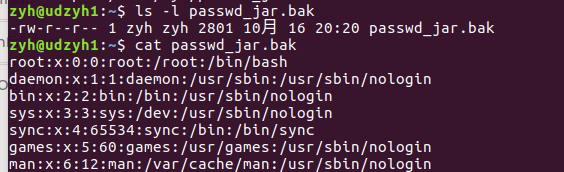
3.6、从HDFS集群中下载文件到本地
1)普通版
P00032_HdfsDemo_PutFile_00102)可以观察到写入了多少
P00031_HdfsDemo_PutFile_001