kNN功能:解决输入是数值型或者标称型的分类问题
kNN大致原理:输入数据集相当于在一定维度的空间中标点,测试集(或者说要预测标签的),相当于是计算与这些已有点的距离(一般是欧式距离),选择前k个距离最近的,看这k个已标点的标签是什么(也就是属于哪一类),返回k个中占比最大的标签作为预测结果。ps:k一般取20
算法大体步骤:
1)计算已知类别数据集(训练集)中的点与当前点之间的距离
2)按照距离递增次序排序
3)选取与当前点距离最小的k个点
4)确定前k个点所在类别出现的频率
5)返回前k个点出现频率最高的类别作为当前点的预测分类
下面用Python3编写kNN:
from numpy import * import operator # 运算符模块 def classifyo(inx, dataSet, labels, k): """ 该算法的核心所在,基本编程思想就是算法的步骤 :param inx: 测试集数据(处理过的向量) :param dataSet: 训练集(不带标签的) :param labels:训练集标签(必须与dataSet行数相同) :param k:算法中k的取值,即选择近邻的数目 :return:预测结果 """ # 1)计算距离d = sqrt((x1-x2)^2 + (y1-y2)^2) dataSetSize = dataSet.shape[0] # tile函数是numpy中的,相当于是把inx当做元素,生成dataSetSize*1的向量 diffMat = tile(inx, (dataSetSize,1)) - dataSet sqDiffmat = diffMat ** 2 # 将矩阵的每一行相加 sqDistance = sqDiffmat.sum(axis=1) distance = sqDistance ** 0.5 # 2)排序 # y=x.argsort()函数,比如x=[3,1,2],3对应的索引是0,x排序后3在最后,所以y[3]=0.即返回值是索引[1,2,0] sortedDistIndicies = distance.argsort() # 3)选择与当前值最小的k个点 classCount = {} for i in range(k): # 找到样本类型 voteIlabel = labels[sortedDistIndicies[i]] # sortedDistIndicies[0]为最小值的索引 # 在字典中将该类型加一 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 # 4)找出出现频率最高的 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) # 5)返回预测 return sortedClassCount[0][0]
书中共将一个小例子test1,与两个示例。
示例1:提高约会匹配对效果。共有三个属性:每年获得的飞行常客里程数、玩视频游戏所耗的时间比、每周消费的冰淇淋公升数;一个标签好感度里面有三种:didntLike,smallDoses,largeDoses。数据集如下:
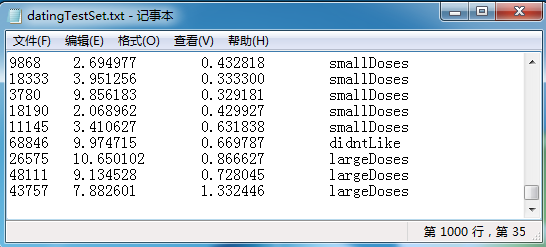
这里共1000个数据样本,程序测试时是挑选前10%作为测试集(有点缺点是这里不是随机挑的,是按顺序来的),剩下的做训练集。最后验证看预测对的占的总比例。
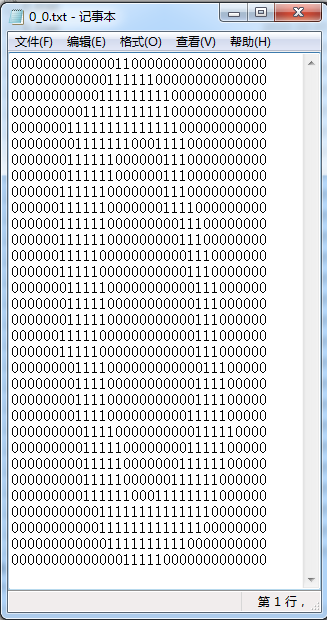
示例2:手写识别系统
它这里为了能简单的用上之前写的分类器,给的不是图片,而是32*32的二进制图像。如下:
完整的配有三个测试的kNN.py文件如下:


1 #!/usr/bin/env python 2 #-*-coding:utf-8 -*- 3 4 from numpy import * 5 import operator # 运算符模块 6 7 from os import listdir #测试中用到的 8 9 10 def classifyo(inx, dataSet, labels, k): 11 """ 12 该算法的核心所在,基本编程思想就是算法的步骤 13 14 :param inx: 测试集数据(处理过的向量) 15 :param dataSet: 训练集(不带标签的) 16 :param labels:训练集标签(必须与dataSet行数相同) 17 :param k:算法中k的取值,即选择近邻的数目 18 :return:预测结果 19 20 """ 21 # 1)计算距离d = sqrt((x1-x2)^2 + (y1-y2)^2) 22 dataSetSize = dataSet.shape[0] 23 # tile函数是numpy中的,相当于是把inx当做元素,生成dataSetSize*1的向量 24 diffMat = tile(inx, (dataSetSize,1)) - dataSet 25 sqDiffmat = diffMat ** 2 26 # 将矩阵的每一行相加 27 sqDistance = sqDiffmat.sum(axis=1) 28 distance = sqDistance ** 0.5 29 30 # 2)排序 31 # y=x.argsort()函数,比如x=[3,1,2],3对应的索引是0,x排序后3在最后,所以y[3]=0.即返回值是索引[1,2,0] 32 sortedDistIndicies = distance.argsort() 33 34 # 3)选择与当前值最小的k个点 35 classCount = {} 36 for i in range(k): 37 # 找到样本类型 38 voteIlabel = labels[sortedDistIndicies[i]] # sortedDistIndicies[0]为最小值的索引 39 # 在字典中将该类型加一 40 classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 41 42 # 4)找出出现频率最高的 43 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) 44 # 5)返回预测 45 return sortedClassCount[0][0] 46 47 # ----------------------------------------------------------------------------------- 48 def creatDataSet(): 49 """ 50 创建训练数据集和标签 51 :return: 数据集(二维向量,即表格),标签(一维向量) 52 """ 53 group = array([[1.0, 1.1],[1.0, 1.0], [0.0, 0.0], [0.0, 0.1]]) 54 labels = ['A', 'A', 'B', 'B'] 55 return group, labels 56 57 def test1(): 58 """ 59 第一个例子演示: 60 训练集是四个点,两个靠的近是A,另外两个标签是B; 61 预测的也是一个个点【0.1,0.1】,看它属于哪一类 62 """ 63 group, labels = creatDataSet() 64 print(str(group)) 65 print(str(labels)) 66 print(classifyo([0.1, 0.1], group, labels, 3)) 67 68 # ----------------------------------------------------------------------------- 69 """ 70 上面是用二维坐标点测试,下面是实例:用该算法提高约会配对效果。 71 """ 72 def file2matrix(filename): 73 ''' 74 导入.txt文件数据,转换为标准的向量训练集 75 :param filename: 数据文件目录 76 :return: 数据矩阵returnMat和对应的类别classLabelVector(标签) 77 ''' 78 with open(filename) as fr: 79 numberOfLines = len(fr.readlines()) # 获取文件中数据的行数 80 returnMat = zeros((numberOfLines, 3)) 81 classLabelVector = [] 82 index = 0 83 with open(filename) as fr: 84 for line in fr.readlines(): 85 line = line.strip() 86 listFromLine = line.split(' ') 87 returnMat[index,:] = listFromLine[0:3] 88 classLabelVector.append(listFromLine[-1]) 89 index += 1 90 return returnMat, classLabelVector 91 92 def autoNorm(dataSet): 93 """ 94 归一化特征值,消除属性之间量级不同导致的影响 95 归一化公式:Y = (X-Xmin)/(Xmax-Xmin) 96 :param dataSet:数据集(无标签的) 97 :return:归一化后的数据集normDataSet,ranges和minVals即最小值与范围,并没有用到 98 """ 99 #找到表格中每一个属性的最大最小值 100 minVals = dataSet.min(axis=0) # 使用0值表示沿着每一列或行标签索引值向下执行方法;使用1值表示沿着每一行或者列标签模向执行对应的方法 101 maxVals = dataSet.max(0) 102 ranges = maxVals - minVals 103 norm_dataset = (dataSet - minVals) / ranges 104 return norm_dataset, ranges, minVals 105 106 def datingClassTest(path,k,precent=0.1): 107 ''' 108 对约会网站的测试方法:这里前precent做测试集 109 :precent : 选取数据集中百分之多少作为测试集 110 :path : 文件路径 111 :k : 112 :return: 返回的是错误数量 113 ''' 114 hoRatio = precent 115 # 加载数据 116 datingDataMat, datingLabels = file2matrix(path) 117 # 归一化数据 118 normMat, ranges, minVals = autoNorm(datingDataMat) 119 # m 表示数据的行数,即矩阵的第一维 120 m = normMat.shape[0] 121 # 设置测试的样本数量, numTestVecs:m表示训练样本的数量 122 numTestVecs = int(m * hoRatio) 123 print('测试样本的数量是:',numTestVecs) 124 errorCount = 0.0 125 for i in range(numTestVecs): 126 # 对数据测试 127 classifierResult = classifyo(normMat[i,:],normMat[numTestVecs:m, :],datingLabels[numTestVecs:m],k) 128 print("测试结果是:%s, 真实结果是:%s"% (classifierResult, datingLabels[i])) 129 if classifierResult != datingLabels[i]: 130 errorCount += 1.0 131 print("the total error rate is: %f" % (errorCount / float(numTestVecs))) 132 return errorCount 133 134 # -------------------------------------------------------------------------------------------------------------------- 135 """ 136 实例2:手写识别系统 137 """ 138 def img2vector(filename): 139 """ 140 将图像数据转换为向量 141 :param filename: 图片文件 因为我们的输入数据的图片格式是 32 * 32的 142 :return: 一维矩阵 143 该函数将图像转换为向量:该函数创建 1 * 1024 的NumPy数组,然后打开给定的文件, 144 循环读出文件的前32行,并将每行的头32个字符值存储在NumPy数组中,最后返回数组。 145 """ 146 returnVect = zeros((1, 1024)) 147 fr = open(filename) 148 for i in range(32): 149 lineStr = fr.readline() 150 for j in range(32): 151 returnVect[0, 32 * i + j] = int(lineStr[j]) 152 return returnVect 153 154 155 def handwritingClassTest(path_train,path_test,path_train_i,path_test_i,k): 156 # 1. 导入数据 157 hwLabels = [] 158 trainingFileList = listdir(path_train) # load the training set 存放的是文件名 159 m = len(trainingFileList) 160 trainingMat = zeros((m, 1024)) 161 # hwLabels存储0~9对应的index位置, trainingMat存放的每个位置对应的图片向量 162 for i in range(m): 163 fileNameStr = trainingFileList[i] 164 fileStr = fileNameStr.split('.')[0] # take off .txt 165 classNumStr = int(fileStr.split('_')[0]) 166 hwLabels.append(classNumStr) 167 # 将 32*32的矩阵->1*1024的矩阵 168 trainingMat[i, :] = img2vector(path_train_i % fileNameStr) 169 170 # 2. 导入测试数据 171 testFileList = listdir(path_test) # iterate through the test set 172 errorCount = 0.0 173 mTest = len(testFileList) 174 for i in range(mTest): 175 fileNameStr = testFileList[i] 176 fileStr = fileNameStr.split('.')[0] # take off .txt 177 classNumStr = int(fileStr.split('_')[0]) 178 vectorUnderTest = img2vector(path_test_i % fileNameStr) 179 classifierResult = classifyo(vectorUnderTest, trainingMat, hwLabels, k) 180 print("the classifier came back with: %d, the real answer is: %d" % (classifierResult, classNumStr)) 181 if (classifierResult != classNumStr): errorCount += 1.0 182 print(" the total number of errors is: %d" % errorCount) 183 print(" the total error rate is: %f" % (errorCount / float(mTest))) 184 185 186 if __name__ == '__main__': 187 # test1() 188 189 path = "E:数据集以及一些书的配套资料MLiA_SourceCodemachinelearninginactionCh02datingTestSet.txt" 190 datingClassTest(path, 3, 0.1) 191 192 # path_train = r'E:数据集以及一些书的配套资料MLiA_SourceCodemachinelearninginactionCh02digits rainingDigits' 193 # path_test = r'E:数据集以及一些书的配套资料MLiA_SourceCodemachinelearninginactionCh02digits estDigits' 194 # # 路径后面多加一个\%s,也就是打开它下面的子目录 195 # path_test_i = r'E:数据集以及一些书的配套资料MLiA_SourceCodemachinelearninginactionCh02digits estDigits\%s' 196 # path_train_i = r'E:数据集以及一些书的配套资料MLiA_SourceCodemachinelearninginactionCh02digits rainingDigits\%s' 197 # handwritingClassTest(path_train, path_test,path_train_i,path_test_i, 3)
以上是用自己编的kNN模块,这里用一下sklearn模块中的kNN:
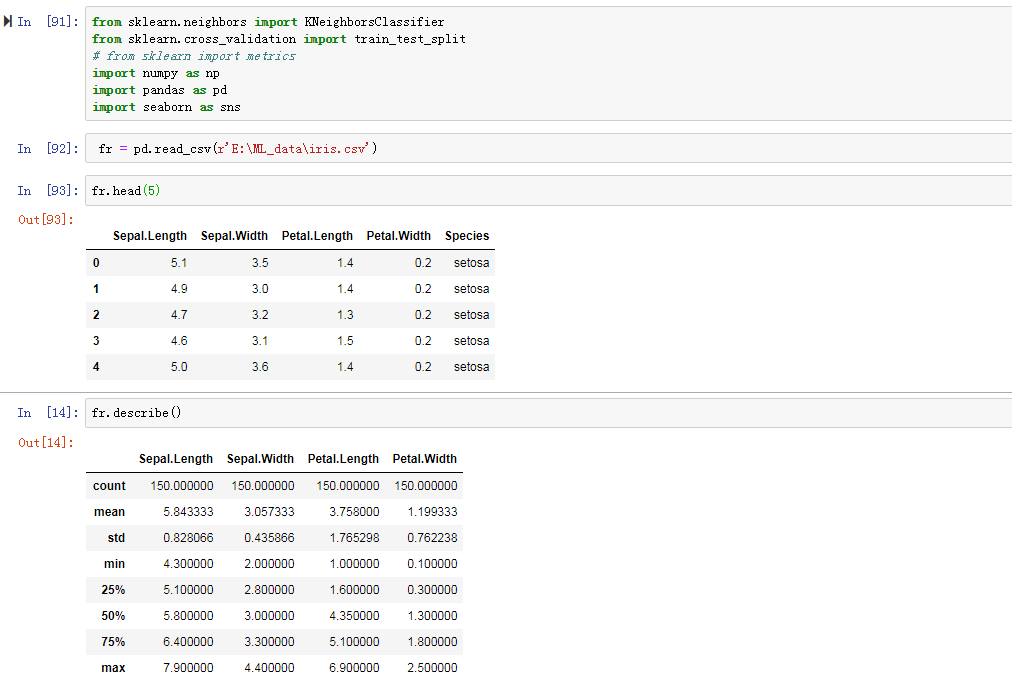

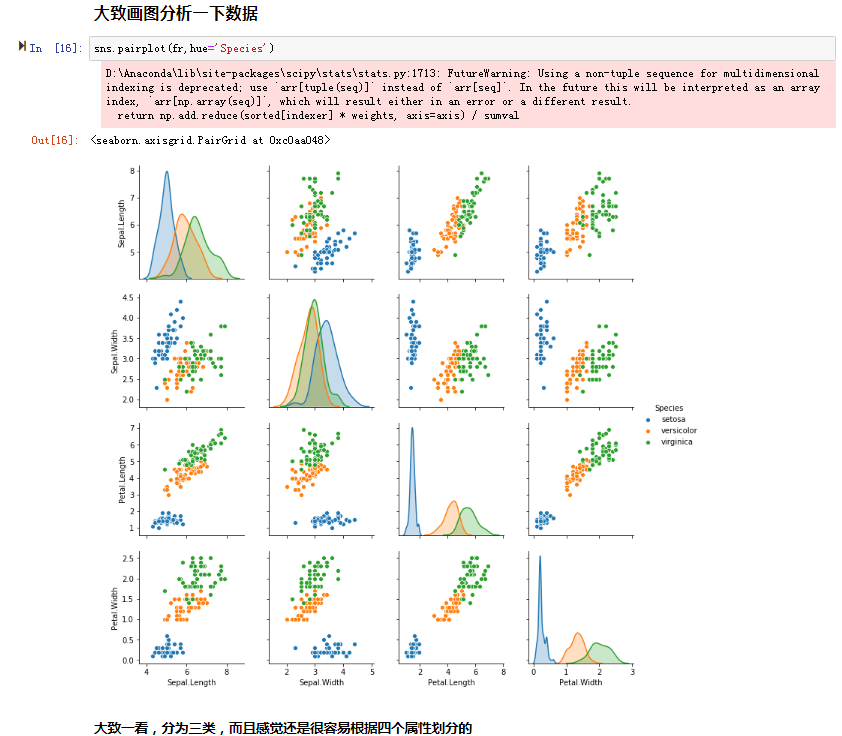
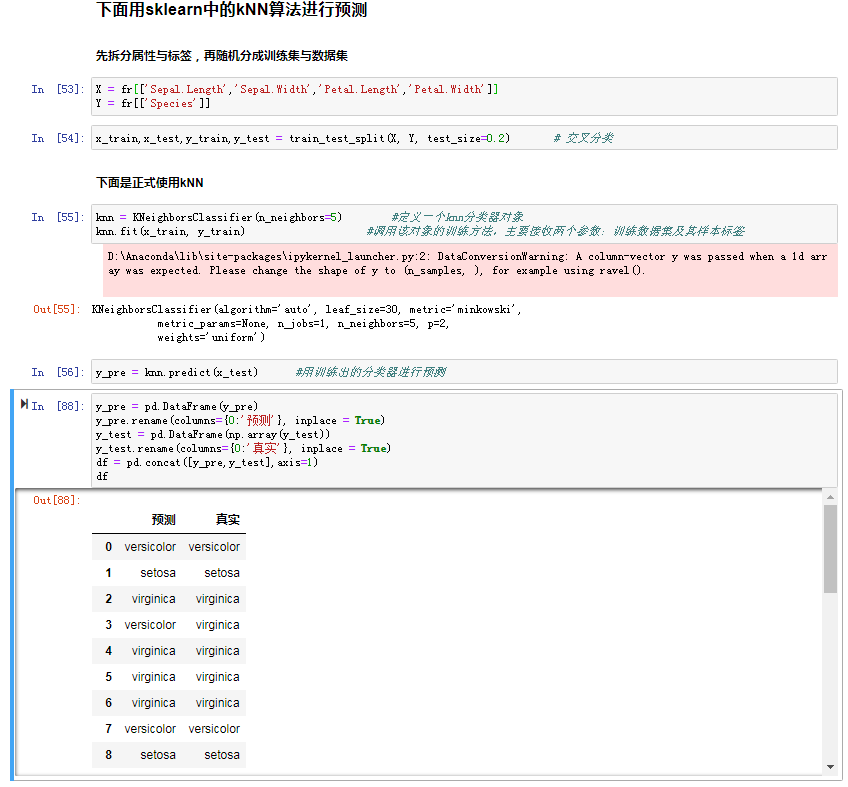
补充:neighbors.KNeighborsClassifier(n_neighbors=5, weights='uniform', algorithm='auto', leaf_size=30,p=2, metric=’minkowski’, metric_params=None, n_jobs=1)
n_neighbors 是用来确定多数投票规则里的K值,也就是在点的周围选取K个值最为总体范围
weights : 这个参数很有意思,它的作用是在进行分类判断的时候给最近邻的点加上权重,它的默认值是'uniform',也就是等权重,所以在这种情况下我们就可以使用多数投票规则来判断输入实例的类别预测。还有一个选择是'distance',是按照距离的倒数给定权重。在这种情况下,距离输入实例最近点的类别情况比其他点类别情况更具有说服力。举个例子假如距离询问点最近的三个数据点中,有 1 个 A 类和 2 个 B 类,并且假设 A 类离询问点非常近,而两个 B 类距离则稍远。在等权加权中,K(3)NN 会判断问题点为 B 类;而如果使用距离加权,那么 A 类有更高的权重(因为更近),如果它的权重高于两个 B 类的权重的总和(类别于多数投票规则使用个数,这里只需要大于B类权重的和就可以了),那么算法会判断问题点为 A 类。权重功能的选项应该视应用的场景而定。还有最后一种情况就是用户自己设定权重的设置方法。
algorithm 是分类时采取的算法,有 {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’},一般情况下选择auto就可以,它会自动进行选择最合适的算法。
p: 在机器学习系列中,我们知道p=1时,距离方法定义为曼哈顿距离,在p=2的时候我们定为欧几里得距离。默认值为2。
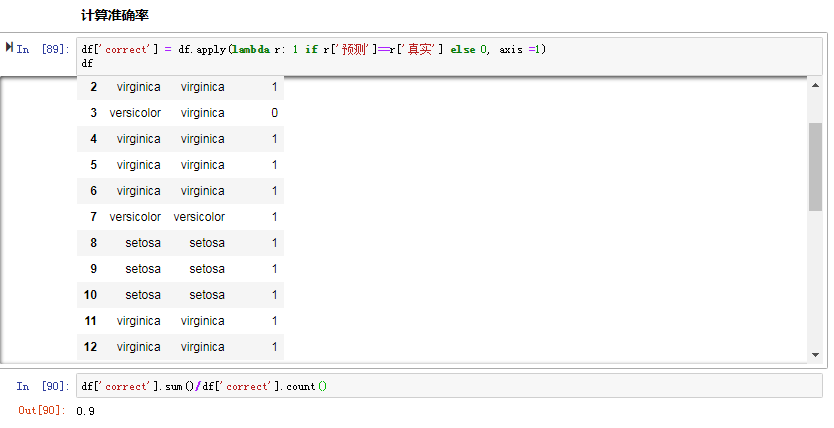
总结:这里的准确率不是很高,可能是因为数据没有归一化;比如Sepal.Length这个属性的值偏大,所以占的权重比较大。也确实这样,后来补加了:(sklearn中的归一化方式有很多,入门这里)
from sklearn import preprocessing
min_max_scaler = preprocessing.MinMaxScaler()
x_train = min_max_scaler.fit_transform(x_train)
x_test = min_max_scaler.fit_transform(x_test)
准确率提到了:0.9666666666666667