本文参考Wang Shusen老师的教学视频:https://www.youtube.com/watch?v=aJRsr39F4dI&list=PLvOO0btloRntpSWSxFbwPIjIum3Ub4GSC&index=2
1. Multi-Head (Self-)Attention Layer
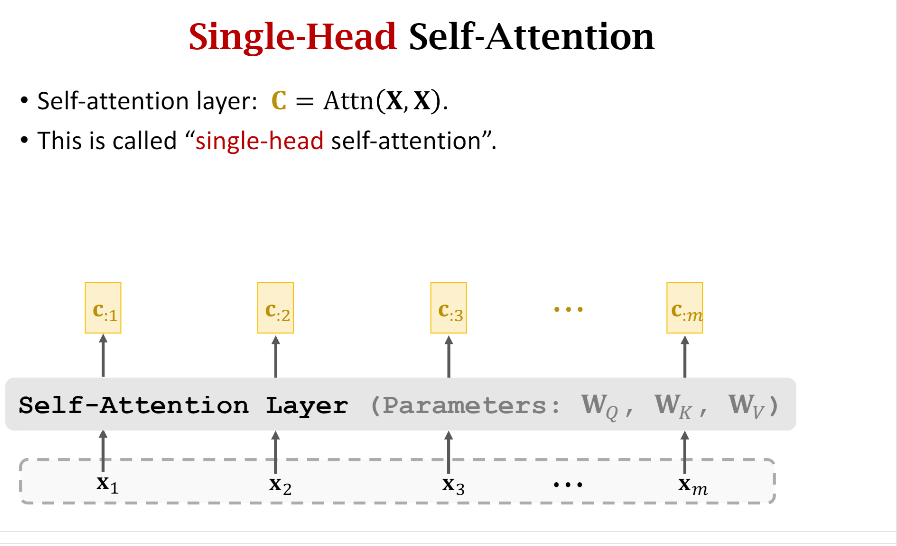
在上一篇文章中我们介绍了Attention层和Self-Attention层,计算逻辑大同小异。只不过之前介绍的都只是Single-Head Self-Attention Layer,如下图示。
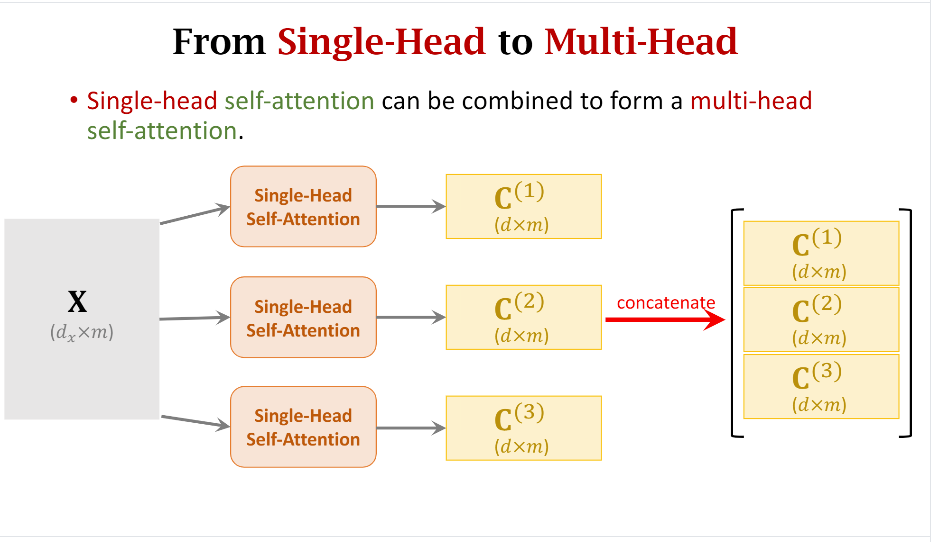
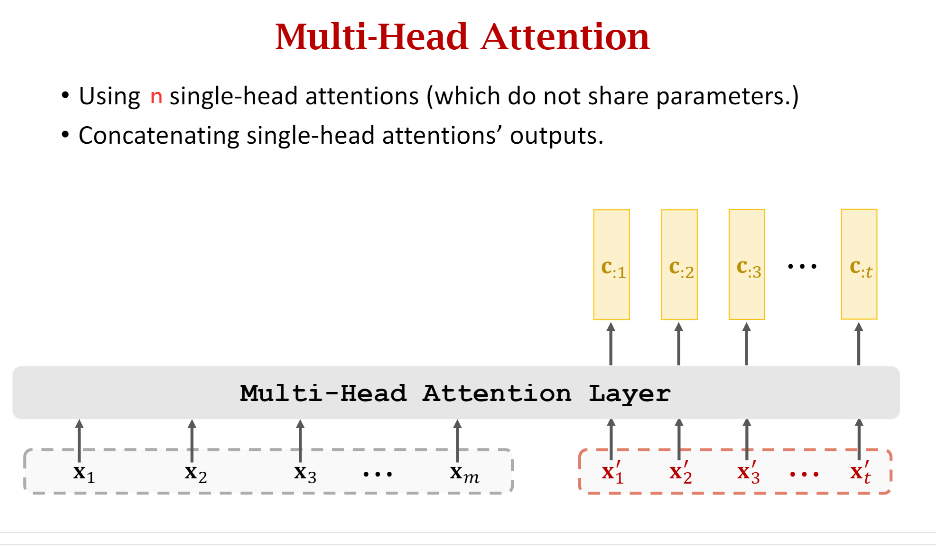
而Transformer中的Multi-Head的意思就是我们把多个Single-Head的结果拼接在一起,具体看下面的示意图:
可以看到,每个Single-Head的输出是一个维度为(d imes m)的矩阵(C^{i}),其中(m)表示输入的词向量个数,(d)每个词向量的长度。这里的(C)等价于上图中的({c_{:1},c_{:2},...,c_{:m}})。下图中是三个Head拼接在一起的例子,其实你也可以拼接更多。
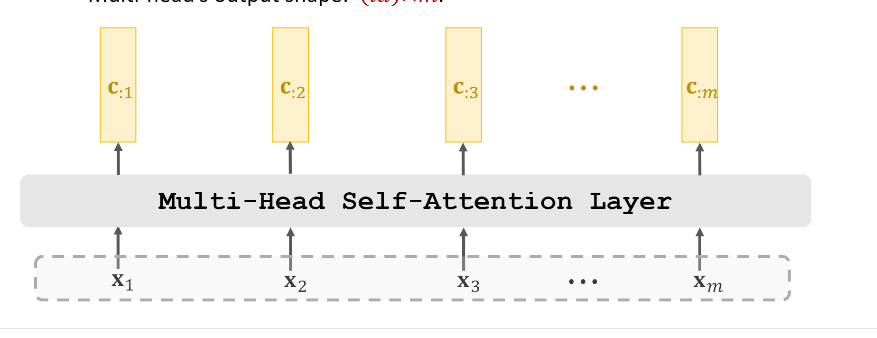
每个Head之间的权重是不共享的。另外,所谓拼接其实是对每个Head的输出(C^{i})拼接,而其是在特征(即(d))这个维度做拼接。所以假如有(n)个Head,那么最后这个Multi-Head的输出矩阵(C)的维度就是((nd) imes m)。所以简化后的Multi-Head Self-Attention Layer示意图如下:
上面画的是Self-Attention的Multi-Head,那么Attention的Multi-Head其实类似,如下图示:
2. 堆叠Multi-Head Self-Attention Layer
上一节中介绍的是单个Multi-Head Self-Attention Layer,其实我们可以堆叠多个,细节如下。
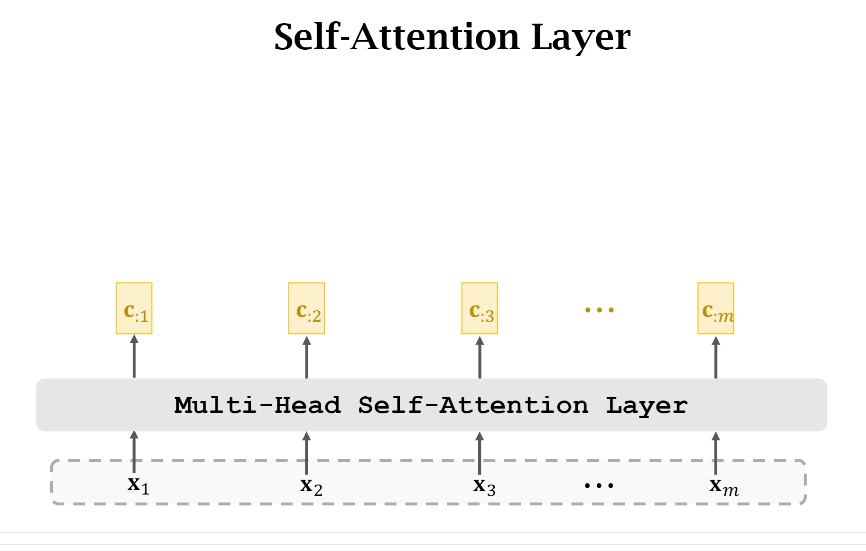
上图给出的是单个Multi-Head Self-Attention Layer,其实类似地我们可以把这(m)个({c_{:j},jin[1,m]})看成是下一个Multi-Head的输入。不过这一般还会额外加一个全连接层对每一个(c)做一个映射,如下图示:
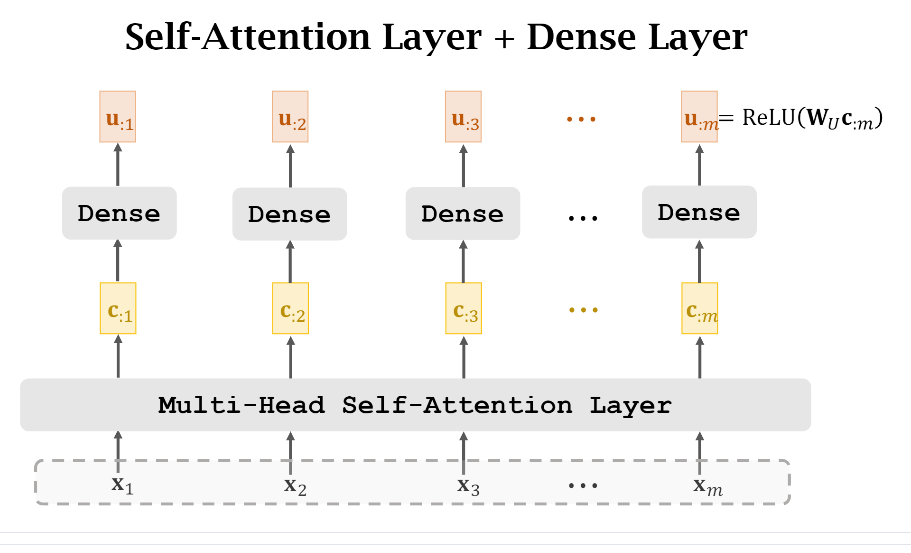
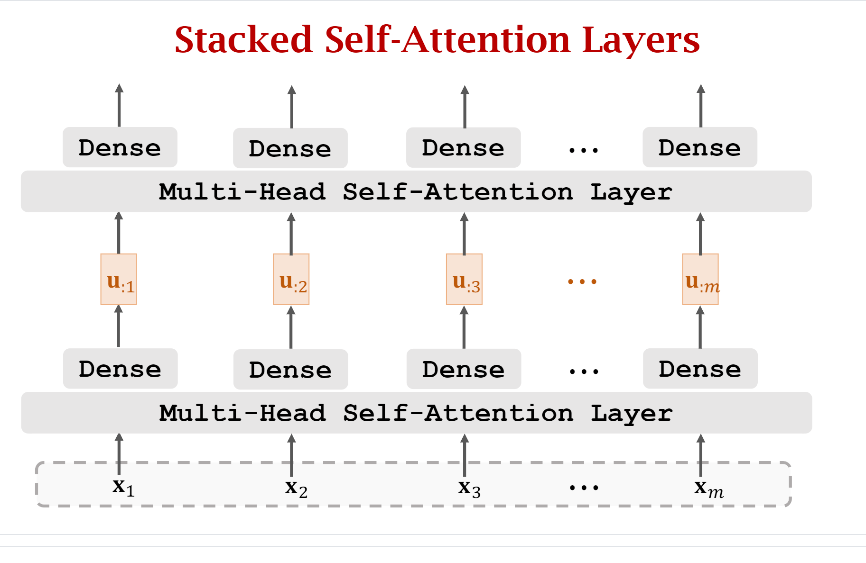
之后,我们再添加一个Multi-Head Self-Attention Layer,如下图示
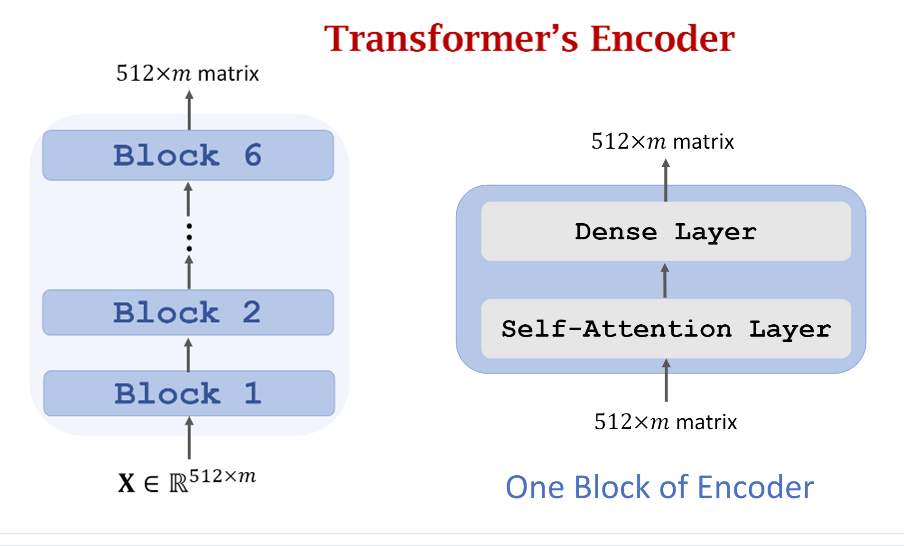
3. Transformer's Encoder
知道了Multi-Head以及如何将多个Multi-Head做堆叠,我们就能很自然的知道Transformer的Encoder的构造原理。
下图的左边就是Transformer的Encoder结构示意图,可以看到它有两个特点:
- 输入和输出的维度是一样的,都是(512 imes m),其中512表示单个词向量的长度,(m)表示词数量
- Encoder由6个Block堆叠而成,每个Block的结构如下图右边所示,可以看到每个Block的输入和输出的维度大小也是保持一致的,每一个Block其实就是一个(Multi-Head) Self-attention Layer 加一个Dense Layer
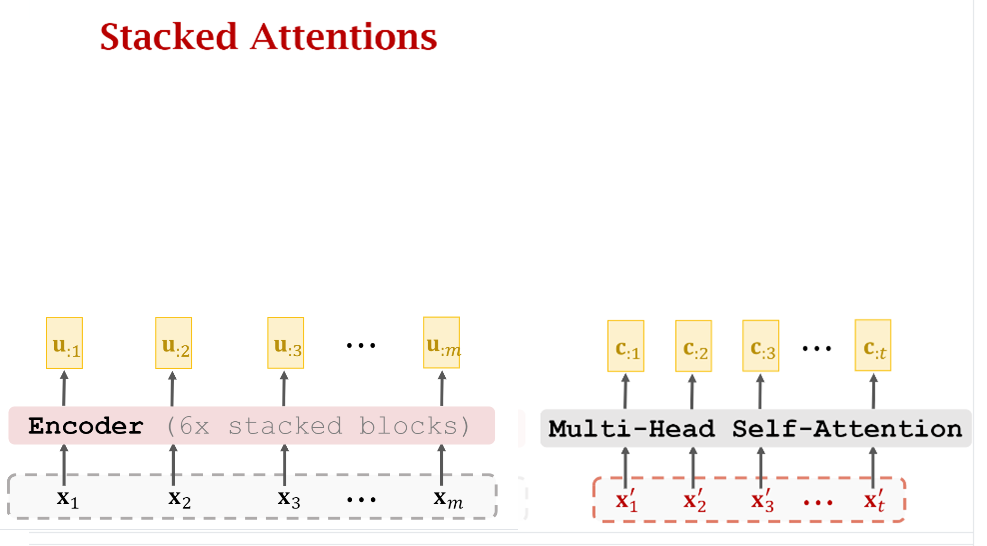
4. 堆叠Attention Layers
注意第2节和第3节介绍的知识对Self-Attention Layer做堆叠,由Self-Attention这个名字我们也能知道它是只计算模块内部各个数据之间的关系,而本节要介绍的Attention Layer则是用来计算不同模块(即Encoder和Decoder)的数据之间的关系。下面我们逐渐介绍Encoder和Decoder如何连接在一起。
首先下图分出来互相之间还没建立联系的Encoder和Decoder,其中Encoder由6个堆叠的Block组成,这在前面刚刚介绍过,而Decoder其实还没有画全,目前只有一个Multi-Head Self-Attention层。
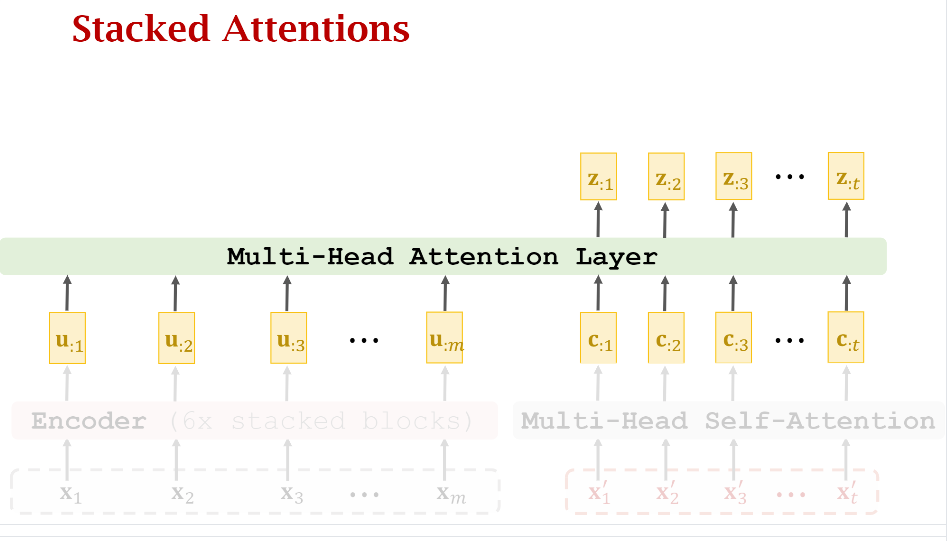
而要建立Encoder和Decoder之间的联系,就需要加上一个Attention Layer,如下图所示。可以看到Multi-Head Attention-Layer的输入有两个:
- Encoder最后一层的输出({u_{:j},jin[1,m]}),总的维度是(mathbb{R}^{512 imes m})
- Decoder第一个Multi-Head Self-Attention的输出({c_{:j},jin[1,t]}),总的维度是(mathbb{R}^{512 imes t})
它的输出是(t)个(z)向量,总的维度和Decoder的输入一样,都是(mathbb{R}^{512 imes t})
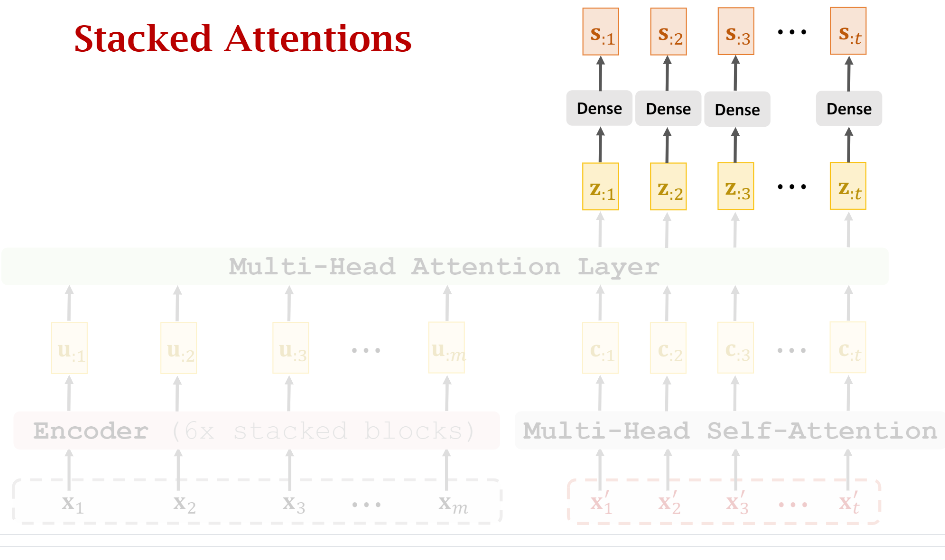
要实现堆叠,同样需要加上(t)个Dense Layer对所有的(z)做一个映射。下图就是Encoder和Decoder某一层建立联系的示意图
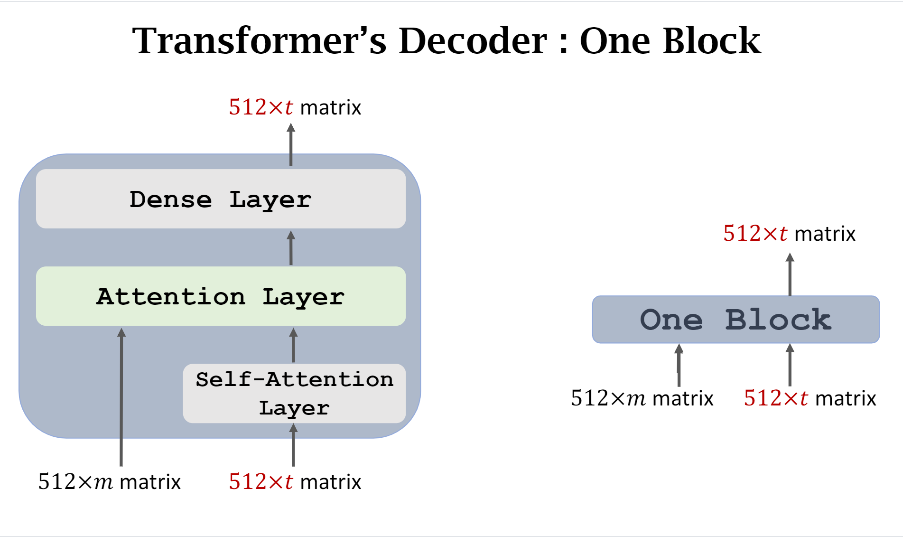
我们对上图中Decoder做一个简化可以得到下图。
我们先看下图左边,可以看到输入有两个,(512 imes m) matrix表示Encoder的输出,它会作为Decoder的每一个Block的输入,(512 imes t)就是Decoder上一个Block的输出,或者是最初的输入数据,它们的维度永远保持不变。
下图右边就是Decoder 的Block最简化示意图了,两个输入,一个输出。另外输出的维度和Decoder的输入保持一致。
5. Transformer: Encoder + Decoder
基于前面的内容,我们把Encoder和Decoder的所有细节都介绍了,现在我们从全局的角度看看Transformer长什么样,如下图示。
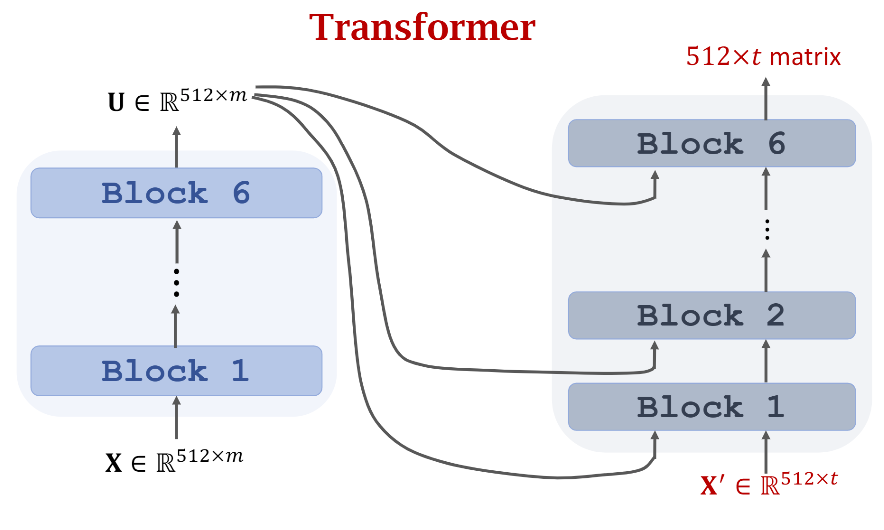
根据上图,我们可以作如下总结:
- Encoder最后一个Block的输出结果会被作为Decoder每个Block的输入参与Attention Layer的计算
- Decoder的每个Block接收两个输入,输出矩阵的维度和Decoder的输入维度保持一样
其实,Transformer还有很多细节这里没有讲到,这里只做简短补充:
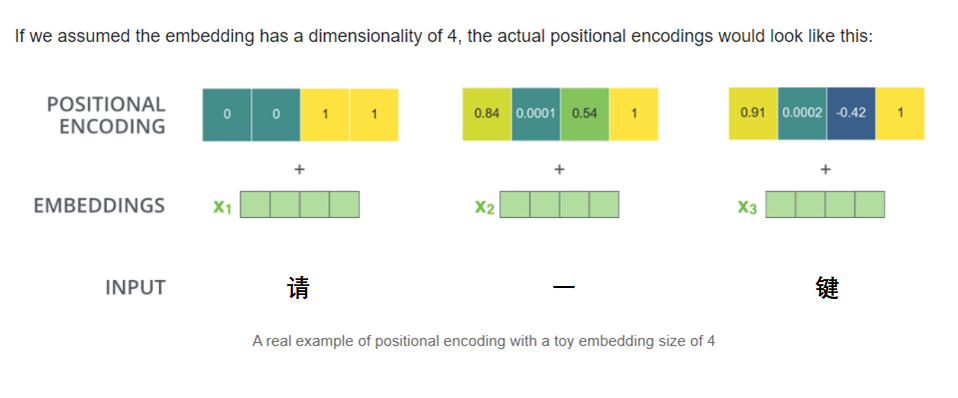
- Position Encoding: 这个其实就是对一个句子里每个单词的位置做编码,比如“请一键三连”,我们应该把“请”标记为0,“一”标记为1,其他同理,只不过Transformer是通过某种算法把这些位置信息也编码成了和词向量同等长度的向量,在将输入传入模型之前,每个单词的词向量都需要加上它自己的Position Encoding,如下图(https://jalammar.github.io/illustrated-transformer/)所示
- Skip-connection: 前面反复提到过Encoder和Decoder的每个Block输入输出维度保持不变,那么很自然地,我们可以将输入和输出做Skip-Connection,在前面的示意图中就没有画出这个细节了。
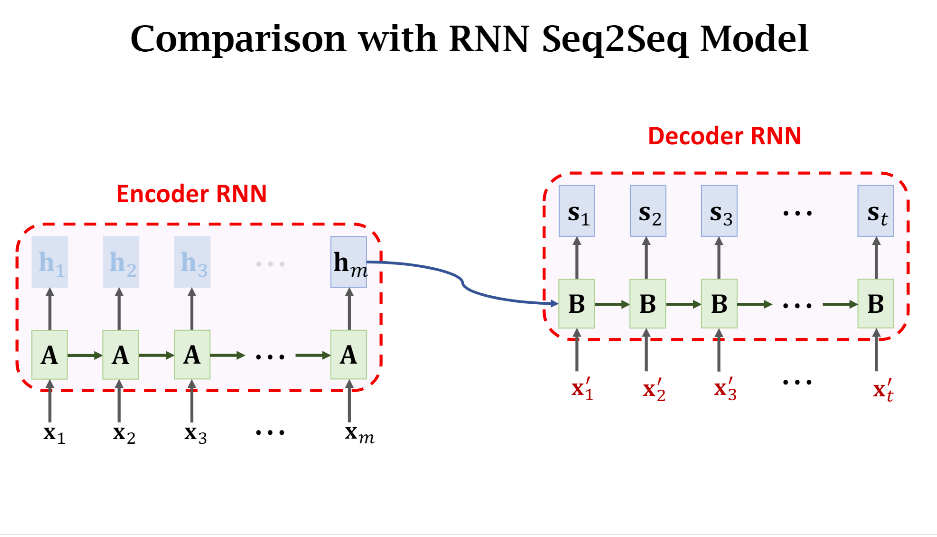
下图给出了基于RNN实现的Seq2Seq模型结构,我们将Transformer和它作对比的话,可以发现二者还是非常相似的,都是Decoder接收Encoder的输出,换句话说RNN Seq2Seq能做的事情,Transformer理论上也都能做到。说到这,也可以很自然地看出Encoder的编码能力的好坏对Decoder的结果起到至关重要的作用,而Encoder该如何训练也是一个值得关注的问题。不过BERT技术的提出就是为了提高Encoder的编码能力,这个会在下一篇文章中介绍~
6. 应用实例
介绍完了Transformer的结构,如果你还觉得模糊(应该不会了吧),可以看看下面的例子进一步加深理解。
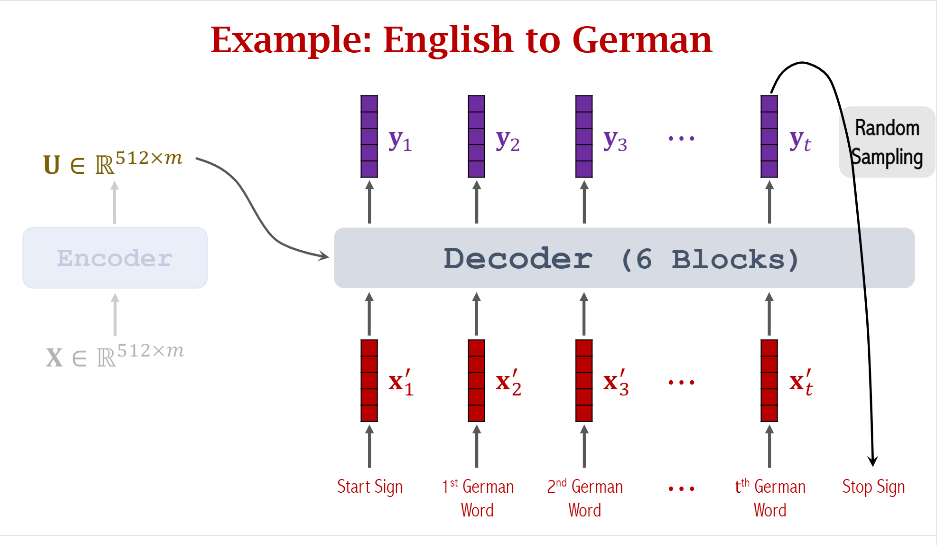
假如这个实例是将英文翻译成德文,首先我们看看Encoder的结构如下图示,左边是简化图,右边展示了(m)个输入和输出的对应关系
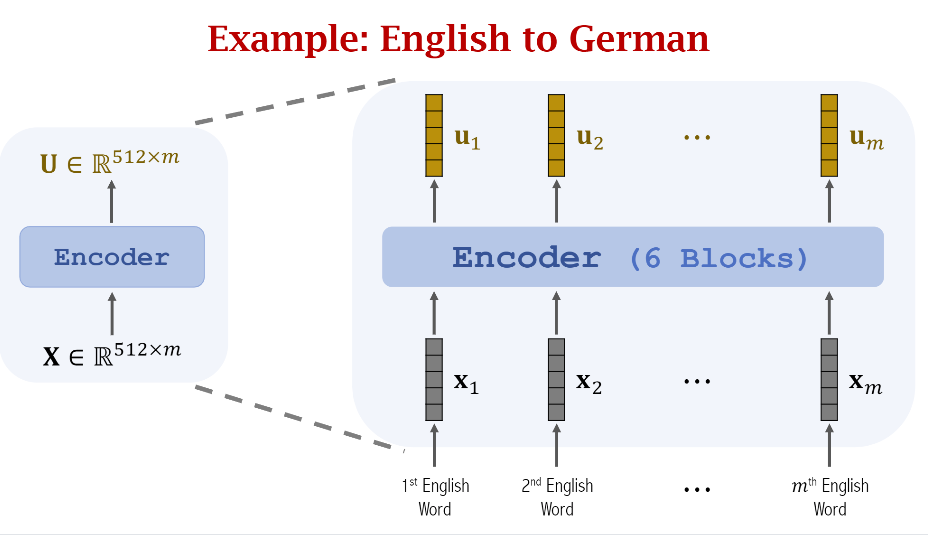
下一步,我们需要做的是将Encoder的输出传给Decoder并做预测
可以看到Decoder的第一个输入是一个固定的起始符号,它的embedding是固定的,它对应的输出是(y_1),你可以把它理解成是一个概率分布,和分类模型类似,每个单词都有不同的权重,我们可以根据概率随机采样或者只选择概率最大的单词作为Decoder下一个输入单词。
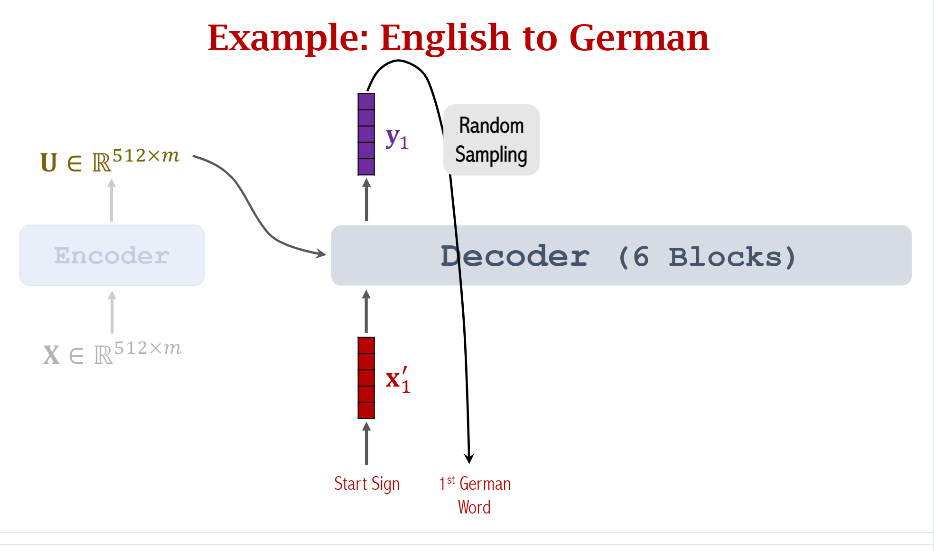
我们重复上面的步骤直到采样到了停止符号(Stop Sign)。至此一个句子的翻译就完成了。