性能调优相关文档书籍
http://dev.mysql.com/doc/refman/5.7/en/group-by-optimization.html
http://dev.mysql.com/doc/refman/5.7/en/order-by-optimization.html
《MySQL性能调优与架构设计》
SQL查询优化总结
-
缺失索引,查询速度差别是100倍:首先应考虑在 where 及 order by 涉及的列上建立索引


1 show index from mb_ransomrequestform; 2 ALTER TABLE mb_ransomrequestform ADD INDEX IDX_corporationid (corporationid); 3 drop index IDX_corporationid on mb_ransomrequestform;
-
避免在 where 子句使用不能使用索引的操作符,比如!=、<>、like “%xx%”、or。否则将导致引擎放弃使用索引而进行全表扫描。
1)like “%xx%”改成like “xxx%”可以使用索引
mysql> select bill.billId from EE_PawnBill bill, EE_PawnerInfo pawner where bill.pawnerid = pawner.pawnerid and bill.businessstatus in (0,1,5) and bill.corporationid = 14077 and bill.status = 0 and pawner.username like '%薛建%' and (bill.printflag = '1' or bill.printstatus=0) order by bill.crtTime desc limit 15; +----------------------+ | billId | +----------------------+ | DD330150020160421002 | +----------------------+ 1 row in set (2.58 sec) mysql> select bill.billId from EE_PawnBill bill, EE_PawnerInfo pawner where bill.pawnerid = pawner.pawnerid and bill.businessstatus in (0,1,5) and bill.corporationid = 14077 and bill.status = 0 and pawner.username like '薛建%' and (bill.printflag = '1' or bill.printstatus=0) order by bill.crtTime desc limit 15; +----------------------+ | billId | +----------------------+ | DD330150020160421002 | +----------------------+ 1 row in set (0.01 sec)
2) select id from t where num=10 or num=20可以这样查询:select id from t where num=10 union all select id from t where num=20, 但不是所有or都不会使用索引,mysql自动优化:
desc select * from ee_pawncontinue c where c.CONTINUECODE="34010300013" or c.BILLID="00000618201205300002"; Using union(IDX_CONTINUECODE,index_billid); Using where
-
减少不必要的子查询,但是有时合适的子查询比没有子查询更有效。
mysql> select count(*) from (select * from EE_PawnBill where corporationid = 2494) bill left join mb_ransomrequestform rrf on rrf.corporationid = 2494 and bill.pawncode=rrf.pawncode , EE_PawnerInfo pawner, EE_PawnRansom ransom where bill.pawnerid = pawner.pawnerid and bill.billid = ransom.billid and bill.printflag = 1 and ransom.corporationid = 2494; +----------+ | count(*) | +----------+ | 28798 | +----------+ 1 row in set (1.02 sec) mysql> select count(*) from EE_PawnBill bill left join mb_ransomrequestform rrf on bill.corporationid = 2494 and rrf.corporationid = 2494 and bill.pawncode=rrf.pawncode , EE_PawnerInfo pawner, EE_PawnRansom ransom where bill.pawnerid = pawner.pawnerid and bill.billid = ransom.billid and bill.printflag = 1 and ransom.corporationid = 2494; +----------+ | count(*) | +----------+ | 28798 | +----------+ 1 row in set (0.32 sec)
-
Where条件:合适的where条件限定,不是越多越好,不是越少越好。应尽量避免全表扫描。
mysql> select count(*) from EE_PawnBill bill left join mb_ransomrequestform rrf on bill.corporationid = 2494 and rrf.corporationid = 2494 and bill.pawncode=rrf.pawncode , EE_PawnerInfo pawner, EE_PawnRansom ransom where bill.pawnerid = pawner.pawnerid and bill.billid = ransom.billid and bill.printflag = 1 and ransom.corporationid = 2494 and bill.corporationid = 2494; +----------+ | count(*) | +----------+ | 28798 | +----------+ 1 row in set (0.46 sec) mysql> select count(*) from EE_PawnBill bill left join mb_ransomrequestform rrf on bill.corporationid = 2494 and rrf.corporationid = 2494 and bill.pawncode=rrf.pawncode , EE_PawnerInfo pawner, EE_PawnRansom ransom where bill.pawnerid = pawner.pawnerid and bill.billid = ransom.billid and bill.printflag = 1 and bill.corporationid = 2494; +----------+ | count(*) | +----------+ | 28798 | +----------+ 1 row in set (0.42 sec) mysql> select count(*) from EE_PawnBill bill left join mb_ransomrequestform rrf on bill.corporationid = 2494 and rrf.corporationid = 2494 and bill.pawncode=rrf.pawncode , EE_PawnerInfo pawner, EE_PawnRansom ransom where bill.pawnerid = pawner.pawnerid and bill.billid = ransom.billid and bill.printflag = 1 and ransom.corporationid = 2494; +----------+ | count(*) | +----------+ | 28798 | +----------+ 1 row in set (0.27 sec)
-
避免可能造成全表扫描的用法
-
MySQL Max()函数的优化:MySQL Max() 函数是用来找出记录集中最大值的记录。
mysql> select max(pawner.pawnerId) from EE_PawnerInfo pawner where pawner.pawnerId like '1203400201605%'; +----------------------+ | max(pawner.pawnerId) | +----------------------+ | 120340020160531001 | +----------------------+ 1 row in set (0.28 sec) mysql> select pawner.pawnerId from EE_PawnerInfo pawner where pawner.pawnerId like '1203400201605%' order by pawner.pawnerId desc limit 1; +--------------------+ | pawnerId | +--------------------+ | 120340020160531001 | +--------------------+ 1 row in set (0.06 sec)
提高mysql千万级大数据SQL查询优化30条经验
http://www.jincon.com/archives/120/
30条经验
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num is null可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:select id from t where num=0 3.应尽量避免在 where 子句中使用!=或<>操作符,否则引擎将放弃使用索引而进行全表扫描。 4.应尽量避免在 where 子句中使用or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:select id from t where num=10 or num=20可以这样查询:select id from t where num=10 union all select id from t where num=20 5.in 和 not in 也要慎用,否则会导致全表扫描,如:select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了:select id from t where num between 1 and 3 6.下面的查询也将导致全表扫描:select id from t where name like '李%'若要提高效率,可以考虑全文检索。 7. 如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:select id from t where num=@num可以改为强制查询使用索引:select id from t with(index(索引名)) where num=@num 8.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:select id from t where num/2=100应改为:select id from t where num=100*2 9.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:select id from t where substring(name,1,3)='abc' ,name以abc开头的id应改为:select id from t where name like 'abc%' 10.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。 11.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。 12.不要写一些没有意义的查询,如需要生成一个空表结构:select col1,col2 into #t from t where 1=0这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:create table #t(...) 13.很多时候用 exists 代替 in 是一个好的选择:select num from a where num in(select num from b)用下面的语句替换:select num from a where exists(select 1 from b where num=a.num) 14.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。 15. 索引并不是越多越好,索引固然可 以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。 16. 应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。 17.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。 18.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。 19.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。 20.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。 21.避免频繁创建和删除临时表,以减少系统表资源的消耗。 22.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。 23.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。 24.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。 25.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。 26.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。 27. 与临时表一样,游标并不是不可使 用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时 间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。 28.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送DONE_IN_PROC 消息。 29.尽量避免大事务操作,提高系统并发能力。 30.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。30条经验
MySQL性能调优之Query优化相关方法
MySQL Query Optimizer
>desc select * from table;
processlist
http://dev.mysql.com/doc/refman/5.7/en/show-processlist.html
>show processlist;
>show full processlist;
$ mysqladmin -h localhost -u user -pPassword processlist
select count(*) from table bill left join (select max(cont.enddate) as enddate, cont.billid f
select p.relatedId, p.picType, p.picName, p.picPath, p.entityId from table1 p
Explain and Profiling
MySQL可以通过EXPLAIN或DESC来查看并分析SQL语句的执行情况
set profiling=1;
select …;
show profiles;
set profiling=0;
show profile cpu,block io for query 1;
几个分析慢查询及优化的例子
mysql Copying to tmp table on disk 影响性能的解决方法
问题
set profiling=1; select cont.billId, cont.pawnCode, cont.continueCode, cont.pawnerName, pawner.address as pawnerAddress, pawner.certificateName as pawnerCertName, pawner.certificateCode as pawnerCertCode, bill.pawnMoney as originalMoney, cont.pawnMoney, cont.beginDate, cont.endDate, cont.chargeMoney, cont.interestMoney, cont.shouldCharge, cont.disactCharge, cont.monthRate, cont.continueCharge, cont.interestRate, cont.shouldMoney, cont.status, cont.uploadStatus, cont.printStatus, crf.approveStatus as isPhone, cont.continueId from EE_PawnContinue cont left join mb_continuerequestform crf on crf.corpid = 2494 and cont.continueid=crf.continueid , EE_PawnBill bill, EE_PawnerInfo pawner where bill.pawnerid = pawner.pawnerid and bill.billid = cont.billid and bill.corporationid = 2494 and cont.printstatus = 1 and cont.status = 0 order by cont.continueCode desc limit 15; show profiles; set profiling=0; show profile cpu,block io for query 1; /* Affected rows: 0 已找到记录: 32 警告: 0 持续时间 4 queries: 36.266 sec. */
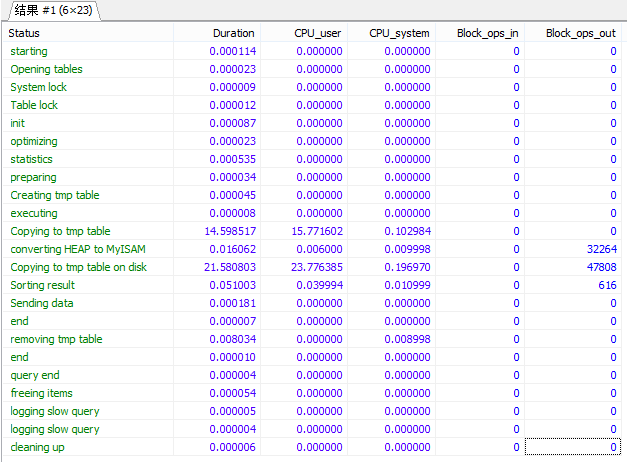
分析
经过查资料发现mysql可以通过变量tmp_table_size和max_heap_table_size来控制内存表大小上限,如果超过上限会将数据写到磁盘上,从而会有物理磁盘的读写操作,导致影响性能。
我们可以通过调整这两个变量的值来提升性能(当然前提条件是mysql所在服务器有足够的内存)。
首先可以通过下面语句查看当前的变量值:
SHOW VARIABLES LIKE 'max_heap_table_size%';
然后通过SET GLOBAL max_heap_table_size=522715200; 设置变量值为512M,你可以根据自己的情况设置合适的值;tmp_table_size变量的设置方法一样。
现状
mysql> SHOW VARIABLES LIKE 'max_heap_table_size%'; +---------------------+----------+ | Variable_name | Value | +---------------------+----------+ | max_heap_table_size | 67108864 | +---------------------+----------+ 1 row in set (0.00 sec) mysql> SHOW VARIABLES LIKE 'tmp_table_size%'; +----------------+--------+ | Variable_name | Value | +----------------+--------+ | tmp_table_size | 262144 | +----------------+--------+ 1 row in set (0.00 sec) mysql> show global status like 'created_tmp%'; +-------------------------+----------+ | Variable_name | Value | +-------------------------+----------+ | Created_tmp_disk_tables | 2270736 | | Created_tmp_files | 613427 | | Created_tmp_tables | 73485634 | +-------------------------+----------+ 3 rows in set (0.00 sec)
关于MySQL tmp_table_size max_heap_table_size
http://www.t086.com/article/4813
tmp_table_size:
SET GLOBAL max_heap_table_size=134217728; //128M
SET tmp_table_size=16777216; //16M
SET GLOBAL tmp_table_size=33554432; //32M
SET GLOBAL tmp_table_size=134217728;
测试环境:提高tmp_table_size到tmp_table_size最大值128M后,Copying to tmp table on disk的时耗降到了0.
但是Copying to tmp table的时间依然基本没有改变,去掉了没用到的select items后,时耗影响仍然不大,去掉的列中没有text或者大varchar类型,因此应该影响不大。
Copying to tmp table太慢 解决方式
mysqladmin -h 192.168.1.155 -u root -p@*** processlist
登陆到后台,查询一下 /opt/mysql/bin/mysqladmin processlist;
发现一个查询状态为: Copying to tmp table 而且此查询速度非常慢,基本一分钟左右才出来,后面是很多查询,状态为lock。
原因也是查询涉及的中间数据太多导致,应该避免全表扫描等查询。
MySQL Sending data导致查询很慢的问题详细分析
http://www.tuicool.com/articles/QzMZJb
Sending data: The thread is processing rows for a statement and also is sending data to the client.
这个数据中就可以看到MyISAM的Sending data比InnoDB的Sending data费时太多了。查看mysql文档
http://dev.mysql.com/doc/refman/5.0/en/general-thread-states.html
Sending data
The thread is reading and processing rows for a SELECT statement, and sending data to the client. Because operations occurring during this this state tend to perform large amounts of disk access (reads), it is often the longest-running state over the lifetime of a given query.
Sending data是去磁盘中读取select的结果,然后将结果返回给客户端。这个过程会有大量的IO操作。你可以使用show profile cpu for query XX;来进行查看,发现MyISAM的CPU_system比InnnoDB大很多。至此可以得出结论是MyISAM进行表查询(区别仅仅使用索引就可以完成的查询)比InnoDB慢。
问题1:返回列的问题
经过一 一排查,最后定为到一个description的列上,这个列的设计为: `description` varchar(8000) DEFAULT NULL COMMENT '游戏描述', 可以看出,不返回description的时候,查询时间只需要15s,返回的时候,需要216s, 两者相差15倍.
有几种解决方法:
1) 查询时去掉description的查询 ,但这受限于业务的实现,可能需要业务做较大调整
2) 增大Innodb buffer pool ,但由于Innodb buffer pool会根据查询进行自动调整,因此如果gm_platform_info不是热门表,作用也不是很明显
3) 表结构优化 ,将descripion拆分到另外的表,这个改动较大,需要已有业务配合修改
问题2:order by + limit问题
select items.itemNum from ee_pawnitems items left join ee_pawnbill bills on items.billid = bills.billid left join ee_pawnerinfo info on bills.pawnerid = info.pawnerid left join kc_items_instock istock on items.billid = istock.billid and items.itemnum = istock.itemnum where 1 = 1 and bills.finishstatus = 1 and bills.printstatus=1 and bills.status = 0 and bills.corporationid = 2991 order by bills.pawnCode desc ; /* Affected rows: 0 已找到记录: 34,881 警告: 0 持续时间 1 query: 0.156 sec. (+ 0.297 sec. network) */ select items.itemNum from ee_pawnitems items left join ee_pawnbill bills on items.billid = bills.billid left join ee_pawnerinfo info on bills.pawnerid = info.pawnerid left join kc_items_instock istock on items.billid = istock.billid and items.itemnum = istock.itemnum where 1 = 1 and bills.finishstatus = 1 and bills.printstatus=1 and bills.status = 0 and bills.corporationid = 2991 order by bills.pawnCode desc limit 15; /* Affected rows: 0 已找到记录: 15 警告: 0 持续时间 1 query: 4.625 sec. */
改了order by的条件:
select bills.pawnCode, items.itemNum, info.userName, bills.businessStatus, items.itemName, bills.busiTypeId, bills.pawnMoney, items.stockStatus, bills.billId, istock.importTime, info.certificateType, info.certificateCode, istock.stockId, istock.itemId, istock.itemCode, bills.beginDate, bills.endDate, datediff( curdate(), bills.endDate) as diffDays, items.entityId from ee_pawnitems items left join ee_pawnbill bills on items.billid = bills.billid left join ee_pawnerinfo info on bills.pawnerid = info.pawnerid left join kc_items_instock istock on items.billid = istock.billid and items.itemnum = istock.itemnum where 1 = 1 and bills.finishstatus = 1 and bills.printstatus=1 and bills.status = 0 and bills.corporationid = 2991 order by bills.pawnCode desc limit 15; /* Affected rows: 0 已找到记录: 15 警告: 0 持续时间 1 query: 4.672 sec. */ select bills.pawnCode, items.itemNum, info.userName, bills.businessStatus, items.itemName, bills.busiTypeId, bills.pawnMoney, items.stockStatus, bills.billId, istock.importTime, info.certificateType, info.certificateCode, istock.stockId, istock.itemId, istock.itemCode, bills.beginDate, bills.endDate, datediff( curdate(), bills.endDate) as diffDays, items.entityId from ee_pawnitems items left join ee_pawnbill bills on items.billid = bills.billid left join ee_pawnerinfo info on bills.pawnerid = info.pawnerid left join kc_items_instock istock on items.billid = istock.billid and items.itemnum = istock.itemnum where 1 = 1 and bills.finishstatus = 1 and bills.printstatus=1 and bills.status = 0 and bills.corporationid = 2991 order by bills.crttime desc limit 15; /* Affected rows: 0 已找到记录: 15 警告: 0 持续时间 1 query: 0.047 sec. */
另参考:http://www.111cn.net/database/mysql/46425.htm
MySQL Order by 语句用法与优化详解
http://www.jb51.net/article/38953.htm
以下情况order by不使用索引:
①SELECT * FROM t1 ORDER BY key_part1 DESC, key_part2 ASC;
--order by的字段混合ASC和DESC
②SELECT * FROM t1 WHERE key2=constant ORDER BY key1;
--用于查询行的关键字与ORDER BY中所使用的不相同
③SELECT * FROM t1 ORDER BY key1, key2;
--对不同的关键字使用ORDER BY:
推测:在同时使用order by和limit时,MySQL进行了某些优化,将语句执行逻辑从"where——order by——limit"变成了"order by——limit——where",具体出现问题与否是与表中数据有关的。
select bill.pawnCode, coalesce(cont1.pawnMoney, bill.pawnMoney) as pawnMoney, bill.beginDate, bill.endDate, bill.businessStatus, pawner.userName as pawnerName, pawner.certificateName as pawnerCertName, pawner.certificateCode as pawnerCertCode, bill.status, bill.uploadStatus, bill.printStatus, bill.pawnerId, bill.billId from EE_PawnBill bill left join EE_PawnContinue cont1 on cont1.billid = bill.billid and cont1.active = 1 and cont1.status = 0, EE_PawnerInfo pawner where bill.pawnerid = pawner.pawnerid and bill.finishstatus = 1 and bill.corporationid in (888880001,3365,7225,14402,33863,1278,1274,7075) and bill.printstatus = 1 and bill.status = 0 and bill.businessstatus in (0, 1, 4) and bill.begindate >= '2016-06-01' and bill.begindate <= '2016-06-08' order by bill.billId desc limit 15; /* Affected rows: 0 已找到记录: 0 警告: 0 持续时间 1 query: 3.297 sec. */ select * from (select bill.pawnCode, coalesce(cont1.pawnMoney, bill.pawnMoney) as pawnMoney, bill.beginDate, bill.endDate, bill.businessStatus, pawner.userName as pawnerName, pawner.certificateName as pawnerCertName, pawner.certificateCode as pawnerCertCode, bill.status, bill.uploadStatus, bill.printStatus, bill.pawnerId, bill.billId from EE_PawnBill bill left join EE_PawnContinue cont1 on cont1.billid = bill.billid and cont1.active = 1 and cont1.status = 0, EE_PawnerInfo pawner where bill.pawnerid = pawner.pawnerid and bill.finishstatus = 1 and bill.corporationid in (888880001,3365,7225,14402,33863,1278,1274,7075) and bill.printstatus = 1 and bill.status = 0 and bill.businessstatus in (0, 1, 4) and bill.begindate >= '2016-06-01' and bill.begindate <= '2016-06-08' order by bill.billId desc) a limit 15; /* Affected rows: 0 已找到记录: 0 警告: 0 持续时间 1 query: 0.031 sec. */
问题3:单列索引 vs. 组合索引
只有主键索引或者多一个corpid索引,查询时间一样:竟然没有使用corpId索引
select * from CorpKuaiMonthReportTwo corpkuaimo0_ where corpkuaimo0_.rptn='2016' and corpkuaimo0_.rptm='4' and corpkuaimo0_.corp_id=74536;
/* Affected rows: 0 已找到记录: 1 警告: 0 持续时间 1 query: 0.438 sec. */
使用组合索引:对于条件的顺序关系不大
select * from CorpKuaiMonthReportTwo corpkuaimo0_ where corpkuaimo0_.rptn='2016' and corpkuaimo0_.rptm='4' and corpkuaimo0_.corp_id=74536;
/* Affected rows: 0 已找到记录: 1 警告: 0 持续时间 1 query: 0.031 sec. */
select * from CorpKuaiMonthReportTwo corpkuaimo0_ where corpkuaimo0_.corp_id=74536 and corpkuaimo0_.rptn='2016' and corpkuaimo0_.rptm='4';
/* Affected rows: 0 已找到记录: 1 警告: 0 持续时间 1 query: 0.031 sec. */
MySQL query很快,network很慢的处理
select chanpayban0_.entityId as entityId28_, chanpayban0_.bankNo as bankNo28_, chanpayban0_.bankCode as bankCode28_, chanpayban0_.drctBankCode as drctBank4_28_, chanpayban0_.bankName as bankName28_, chanpayban0_.areaCode as areaCode28_, chanpayban0_.isSecBusiness as isSecBus7_28_, chanpayban0_.orderNum as orderNum28_, chanpayban0_.lastModifyTime as lastModi9_28_ from Chanpay_BankBranch chanpayban0_ where (exists (select 1 from Chanpay_AreaCode chanpayare1_ where chanpayare1_.codeMin+0<=chanpayban0_.areaCode+0 and chanpayare1_.codeMax+0>=chanpayban0_.areaCode+0 and chanpayare1_.areaCode='1100')) and chanpayban0_.bankNo='102'; /* Affected rows: 0 已找到记录: 214 警告: 0 持续时间 1 query: 0.062 sec. (+ 1.516 sec. network) */ ALTER TABLE Chanpay_AreaCode ADD INDEX IDX_codeMin (codeMin); ALTER TABLE Chanpay_AreaCode ADD INDEX IDX_codeMax (codeMax); ALTER TABLE Chanpay_AreaCode ADD INDEX IDX_areaCode (areaCode); select chanpayban0_.entityId as entityId28_, chanpayban0_.bankNo as bankNo28_, chanpayban0_.bankCode as bankCode28_, chanpayban0_.drctBankCode as drctBank4_28_, chanpayban0_.bankName as bankName28_, chanpayban0_.areaCode as areaCode28_, chanpayban0_.isSecBusiness as isSecBus7_28_, chanpayban0_.orderNum as orderNum28_, chanpayban0_.lastModifyTime as lastModi9_28_ from Chanpay_BankBranch chanpayban0_ where (exists (select 1 from Chanpay_AreaCode chanpayare1_ where chanpayare1_.codeMin+0<=chanpayban0_.areaCode+0 and chanpayare1_.codeMax+0>=chanpayban0_.areaCode+0 and chanpayare1_.areaCode='1000')) and chanpayban0_.bankNo='102' ; /* Affected rows: 0 已找到记录: 314 警告: 0 持续时间 1 query: 0.000 sec. (+ 0.125 sec. network) */ select chanpayban0_.entityId as entityId28_, chanpayban0_.bankNo as bankNo28_, chanpayban0_.bankCode as bankCode28_, chanpayban0_.drctBankCode as drctBank4_28_, chanpayban0_.bankName as bankName28_, chanpayban0_.areaCode as areaCode28_, chanpayban0_.isSecBusiness as isSecBus7_28_, chanpayban0_.orderNum as orderNum28_, chanpayban0_.lastModifyTime as lastModi9_28_ from Chanpay_BankBranch chanpayban0_ where (exists (select 1 from Chanpay_AreaCode chanpayare1_ where chanpayare1_.codeMin<=chanpayban0_.areaCode and chanpayare1_.codeMax>=chanpayban0_.areaCode and chanpayare1_.areaCode='1000')) and chanpayban0_.bankNo='102'; /* Affected rows: 0 已找到记录: 314 警告: 0 持续时间 1 query: 0.000 sec. (+ 0.094 sec. network) */
优化:
1. 还是索引的缺失
2. 不要在sql中使用算术表达式:chanpayare1_.codeMin+0<=chanpayban0_.areaCode+0
Mysql索引介绍及常见索引的区别
Mysql索引概念:
说说Mysql索引,看到一个很少比如:索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,有500也是目录,它当然效率低,目录是要占纸张的,而索引是要占磁盘空间的。
Mysql索引主要有两种结构:B+树和hash.
hash:hsah索引在mysql比较少用,他以把数据的索引以hash形式组织起来,因此当查找某一条记录的时候,速度非常快.当时因为是hash结构,每个键只对应一个值,而且是散列的方式分布.所以他并不支持范围查找和排序等功能.
B+树:b+tree是mysql使用最频繁的一个索引数据结构,数据结构以平衡树的形式来组织,因为是树型结构,所以更适合用来处理排序,范围查找等功能.相对hash索引,B+树在查找单条记录的速度虽然比不上hash索引,但是因为更适合排序等操作,所以他更受用户的欢迎.毕竟不可能只对数据库进行单条记录的操作.
Mysql常见索引有:
主键索引、唯一索引、普通索引、全文索引、组合索引
PRIMARY KEY(主键索引) ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` ) UNIQUE(唯一索引) ALTER TABLE `table_name` ADD UNIQUE (`column`)
INDEX(普通索引) ALTER TABLE `table_name` ADD INDEX index_name ( `column` ) FULLTEXT(全文索引) ALTER TABLE `table_name` ADD FULLTEXT ( `column` )
组合索引 ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )
Mysql各种索引区别:
普通索引:最基本的索引,没有任何限制
唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
主键索引:它 是一种特殊的唯一索引,不允许有空值。
全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。